Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
株式会社ジオロジック
5,901 views
ソフトウェアエンジニアに知ってほしいAerospike
ソフトウェアエンジニアがAerospikeを使ったシステム設計をするのに必要な情報などです。 2016/03/03に、オプトさん主催の市ヶ谷Geed Knightで発表する内容です。
Technology
◦
Read more
10
Save
Share
Embed
Embed presentation
Download
Downloaded 19 times
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PPTX
キャッシュコヒーレントに囚われない並列カウンタ達
by
Kumazaki Hiroki
PPTX
研修成果プレゼン資料
by
Wataru Yamaura
PDF
Vivado hls勉強会1(基礎編)
by
marsee101
PPTX
冬のLock free祭り safe
by
Kumazaki Hiroki
ODP
MPSoCのPLの性能について
by
marsee101
PDF
ドキュメントを作りたくなってしまう魔法のツールSphinx
by
Takayuki Shimizukawa
PDF
Scapyで作る・解析するパケット
by
Takaaki Hoyo
PDF
インフラエンジニアの綺麗で優しい手順書の書き方
by
Shohei Koyama
キャッシュコヒーレントに囚われない並列カウンタ達
by
Kumazaki Hiroki
研修成果プレゼン資料
by
Wataru Yamaura
Vivado hls勉強会1(基礎編)
by
marsee101
冬のLock free祭り safe
by
Kumazaki Hiroki
MPSoCのPLの性能について
by
marsee101
ドキュメントを作りたくなってしまう魔法のツールSphinx
by
Takayuki Shimizukawa
Scapyで作る・解析するパケット
by
Takaaki Hoyo
インフラエンジニアの綺麗で優しい手順書の書き方
by
Shohei Koyama
What's hot
PDF
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
PPTX
World Locking Tools V1.0.0について~ 機能と導入 ~
by
Takahiro Miyaura
PPTX
OpenVRやOpenXRの基本的なことを調べてみた
by
Takahiro Miyaura
PDF
第4回Linux-HA勉強会資料 Pacemakerの紹介
by
ksk_ha
PPTX
MLflowで学ぶMLOpsことはじめ
by
Kenichi Sonoda
PDF
きつねさんでもわかるLlvm読書会 第2回
by
Tomoya Kawanishi
PDF
JVMパラメータチューニングにおけるOptunaの活用事例 ( Optuna Meetup #1 )
by
Hironobu Isoda
PPTX
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
PPTX
CEDEC2019 大規模モバイルゲーム運用におけるマスタデータ管理事例
by
sairoutine
PDF
Vivado hls勉強会4(axi4 master)
by
marsee101
PDF
中級グラフィックス入門~シャドウマッピング総まとめ~
by
ProjectAsura
PPTX
【Unity道場Houdini編】UnityとHoudiniで作るRealtimeVFX実践解説 前編
by
UnityTechnologiesJapan002
PDF
【解説】IKE(IIJ Kubernetes Engine):= Vanilla Kubernetes + 何?
by
IIJ
PDF
エンジニアから飛んでくるマサカリを受け止める心得
by
Reimi Kuramochi Chiba
PDF
はじめようARCore:自己位置推定・平面検出・FaceTracking
by
Takashi Yoshinaga
PDF
ピクサー USD 入門 新たなコンテンツパイプラインを構築する
by
Takahito Tejima
PDF
MRU : Monobit Reliable UDP ~5G世代のモバイルゲームに最適な通信プロトコルを目指して~
by
モノビット エンジン
PDF
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
PDF
Logicadの秒間16万リクエストをさばく広告入札システムにおける、gRPCの活用事例
by
Hironobu Isoda
PPTX
プログラマが欲しい仕様書とは
by
Katsutoshi Makino
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
World Locking Tools V1.0.0について~ 機能と導入 ~
by
Takahiro Miyaura
OpenVRやOpenXRの基本的なことを調べてみた
by
Takahiro Miyaura
第4回Linux-HA勉強会資料 Pacemakerの紹介
by
ksk_ha
MLflowで学ぶMLOpsことはじめ
by
Kenichi Sonoda
きつねさんでもわかるLlvm読書会 第2回
by
Tomoya Kawanishi
JVMパラメータチューニングにおけるOptunaの活用事例 ( Optuna Meetup #1 )
by
Hironobu Isoda
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
CEDEC2019 大規模モバイルゲーム運用におけるマスタデータ管理事例
by
sairoutine
Vivado hls勉強会4(axi4 master)
by
marsee101
中級グラフィックス入門~シャドウマッピング総まとめ~
by
ProjectAsura
【Unity道場Houdini編】UnityとHoudiniで作るRealtimeVFX実践解説 前編
by
UnityTechnologiesJapan002
【解説】IKE(IIJ Kubernetes Engine):= Vanilla Kubernetes + 何?
by
IIJ
エンジニアから飛んでくるマサカリを受け止める心得
by
Reimi Kuramochi Chiba
はじめようARCore:自己位置推定・平面検出・FaceTracking
by
Takashi Yoshinaga
ピクサー USD 入門 新たなコンテンツパイプラインを構築する
by
Takahito Tejima
MRU : Monobit Reliable UDP ~5G世代のモバイルゲームに最適な通信プロトコルを目指して~
by
モノビット エンジン
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
Logicadの秒間16万リクエストをさばく広告入札システムにおける、gRPCの活用事例
by
Hironobu Isoda
プログラマが欲しい仕様書とは
by
Katsutoshi Makino
ソフトウェアエンジニアに知ってほしいAerospike
1.
ソフトウェアエンジニアに知ってほしいAerospike 株式会社 CyberZ 藪本 晃輔
2.
自己紹介 藪本 晃輔 Facebook:kousuke.yabumoto.9 2014年
5月にCyberZ中途入社 現在は開発リーダーとして、マーケティング領域の 新規プロダクトを作っています新規プロダクトを作っています。 前職は大手SIerですが、DSPを作っていました。 今日お話しするAerospikeは、現在で2システム目です。 ただ、インフラ関連はそんなに詳しくないので、 システムレイヤーの話をします。
3.
会社紹介 スマートフォンに特化した広告マーケティング会社です。 ■事業 ①F.O.X(スマホ広告計測ツール) toBプロダクト:アドテクノロジー事業 ②OPENREC(ゲームプレイ動画) toCプロダクト:スマートフォンメディア事業 e-Sports大会「RAGE」開催 ■オフィス・開発環境 2015年7月にエンジニア専用オフィスがOPEN! 「エンジニアが働きやすい環境づくり」 2016年1月にメインフロアも全面リニューアル! ■募集職種(一部) ▼F.O.X ・システムエンジニア ・UI/UXエンジニア ・ビジネス責任者 ▼OPENREC ・アプリエンジニア
・Webエンジニア ・リードエンジニア ▼共通 ・インフラエンジニア 全員に電動昇降デスク、 アーロンチェアが支給されます 寝転がって開発できるスペースも! 社員の福利厚⽣の⼀環で ワンコインで利⽤できる社内カフェがあります アカデミーエリア。 社内勉強会も活発です
4.
いわゆるKVS(Key-Value-Store) Aerospike社が有償でサポート Community EditionがOSSで公開されており、無償で使用可能 「Aerospike」とは? データの格納はSSD-MEM SSD-MEMは、キーのハッシュをメモリに、データをSSDに保存します。 ※実際はファイルやメモリ等も選べますが、 実質SSD-MEMしか選択しない ーファイル:そんなに速くない(開発環境向き) ーメモリ:それならAerospikeじゃなくても…(開発環境向き) (以降SSD-MEMの設定がされているものとして話を進めます...)
5.
Aerospikeの特徴をいくつか紹介します
6.
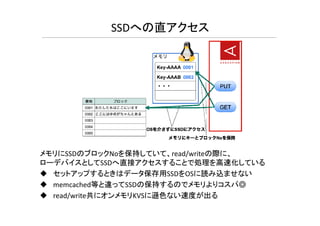
SSDへの直アクセス メモリにSSDのブロックNoを保持していて、read/writeの際に、 ローデバイスとしてSSDへ直接アクセスすることで処理を高速化している セットアップするときはデータ保存用SSDをOSに読み込ませない memcached等と違ってSSDの保持するのでメモリよりコスパ◎ read/write共にオンメモリKVSに遜色ない速度が出る
7.
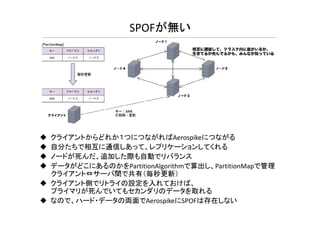
SPOFが無い クライアントからどれか1つにつながればAerospikeにつながる 自分たちで相互に通信しあって、レプリケーションしてくれる ノードが死んだ、追加した際も自動でリバランス データがどこにあるのかをPartitionAlgorithmで算出し、PartitionMapで管理 クライアント⇔サーバ間で共有(毎秒更新) クライアント側でリトライの設定を入れておけば、 プライマリが死んでいてもセカンダリのデータを取れる なので、ハード・データの両面でAerospikeにSPOFは存在しない
8.
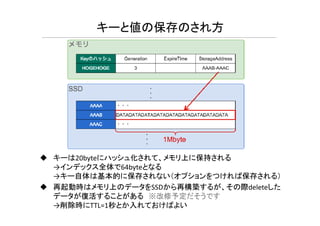
キーと値の保存のされ方 キーは20byteにハッシュ化されて、メモリ上に保持される →インデックス全体で64byteとなる →キー自体は基本的に保存されない(オプションをつければ保存される) 再起動時はメモリ上のデータをSSDから再構築するが、その際deleteした データが復活することがある ※改修予定だそうです →削除時にTTL=1秒とか入れておけばよい
9.
データを高速にread/write出来る SSDを使うため、インメモリと比べて、 低コストで大量のデータを扱うことができる データを永続化でき、信頼性が高い 特徴をまとめると・・ 単一障害点が無い (→あれ、ネット広告系システムに向いてるんじゃない・・?)
10.
とはいえ、 今日はAerospikeの営業に来たわけではないです(笑)
11.
もっと設計に役立ちそうな、 データモデルと設計のコツみたいな話をしていきます
12.
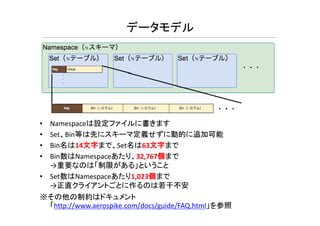
データモデル • Namespaceは設定ファイルに書きます • Set、Bin等は先にスキーマ定義せずに動的に追加可能 •
Bin名は14文字まで、Set名は63文字まで • Bin数はNamespaceあたり、32,767個まで →重要なのは「制限がある」ということ • Set数はNamespaceあたり1,023個まで →正直クライアントごとに作るのは若干不安 ※その他の制約はドキュメント 「http://www.aerospike.com/docs/guide/FAQ.html」を参照
13.
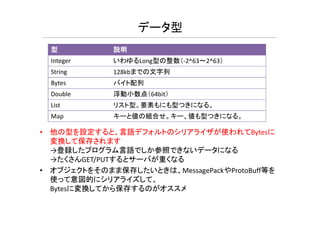
データ型 型 説明 Integer いわゆるLong型の整数(-2^63~2^63) String
128kbまでの文字列 Bytes バイト配列 Double 浮動小数点(64bit) List リスト型。要素もにも型つきになる。 値 組 値も • 他の型を設定すると、言語デフォルトのシリアライザが使われてBytesに 変換して保存されます →登録したプログラム言語でしか参照できないデータになる →たくさんGET/PUTするとサーバが重くなる • オブジェクトをそのまま保存したいときは、MessagePackやProtoBuff等を 使って意図的にシリアライズして、 Bytesに変換してから保存するのがオススメ Map キーと値の組合せ。キー、値も型つきになる。
14.
キー設計① • キーはハッシュ化されて、結構綺麗に負荷分散されます →キー自体が連番だったりしても、ハッシュ化することで綺麗に分散される • 例えばユーザーデータなど、ひとつのキーにアクセス集中せず、 全体の量が多いデータを処理するのは得意 •
逆に、ひとつのキーに対して短い間隔で大量にアクセスをすると、 KEY_BUSYというエラーが出ます →これはレコードのロック待ちが溜まりすぎてる状態らしい →とはいえ同時に大量に同じキーにアクセスしなければ大丈夫
15.
キー設計②(KEY_BUSY対策) とはいえ、キャンペーン情報などをキーにしたいケースもありますよね Aerospikeに、Bin単位でインクリメントや追加するようなAPIもあるし・・・ • キーを分散しておく(例えばキャンペーン毎に必ず10キー用意しておく) →それでもあんまり多いと耐えられない • サーバ内で値をキャッシュし、10秒に一回PUTする →サーバ数が数万とか無ければ回るんじゃないか →更新するタイミングをちょっとずつずらせればベスト [KEY_BUSY対策案]
16.
• write_block_size(最大1MB)を超える値は入れられない →超えるとRecord too
bigエラーが出ます • 逆に値が大きすぎると、期待したパフォーマンスが出ない →通信コスト →ディスクIO だいたい50b t 1kbくらいが良さそう 値の設計 [長さの話] • だいたい50byte~1kbくらいが良さそう →リリース前に、本番のデータを入れてレイテンシの検証をした方がいい [キーの話] • Aerospikeに保存される際、キーがハッシュ化されて取り出せなくなるので、 必要ならBinのひとつを使ってキーの値を入れておくといいかもしれない ※オプションをつけるとScanやクエリの時は取り出せるようになります
17.
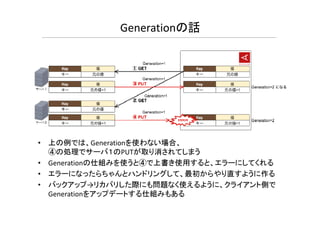
Generationの話 • 上の例では、Generationを使わない場合、 ④の処理でサーバ1のPUTが取り消されてしまう • Generationの仕組みを使うと④で上書き使用すると、エラーにしてくれる •
エラーになったらちゃんとハンドリングして、最初からやり直すように作る • バックアップ→リカバリした際にも問題なく使えるように、クライアント側で Generationをアップデートする仕組みもある
18.
エラーハンドリング Aerospikeのエラーコードは現在使っているライブラリに登録されているだ けで、63項目ありました。 その中でハンドリングしておいた方がいいものいくつかを紹介します。 エラーコード どうするか 3:Generation Error
リトライ処理を入れる。 それでも出るときは無視か処理を見直す。 9 Ti t リトライ処理を入れる9:Timeout リトライ処理を入れる。 もしかしたら、Aerospikeの負荷が高すぎるかも。 13:Record too big 設計ミス、もしくは超レアケース。設計を見直しましょ う。※1MB以上のレコードを入れた時に出ます。 14:Key Busy 設計ミス。Key Busyのことを考えて設計しよう。 他にもAerospikeのサーバ側のログにはいろんなことが書いてあるので、 ちゃんと監視するようにしましょう。
19.
• 全件をなめるAPI「Scan」がありますが、これは使わない方がいいです! • Scan自体が遅いだけでなく、通常のGET/PUTの速度にも影響します •
Scanしなくていいようにキーの設計をしましょう • もちろん絶対に使っちゃいけないわけではなく、月一回レコードの内部を 調査するとか、データのリカバリするとかは、もちろんOK ただ、その場合でもScanの優先度を下げましょう!(APIで設定できます) その他の設計のコツ ~Scanは使わない~ • 通常業務の範囲の処理では、 「Scan」を使わなくてもいい設計をしましょう(大事なことなのでry
20.
• はじめのキャパシティプランニングで、high_water_markを見てなかった →突然Aerospikeのデータが消え出した・・・ →ちゃんと設定項目は全部理解しましょう • GenerationPolicyを指定してなかったため →当然Generationが効かずデータ不整合が起きた・・・ •
PUTの時にRecordExistsActionを指定してなかった 部 だ 新 たか た 全部 新され ま た 最後に、僕がAerospikeで失敗したこと →一部のBinだけ更新したかったのに、全部更新されてしまった・・・ • 現在JavaのクライアントライブラリをScalaで使っているが、 Scalaからそのまま使おうとしていたために、 全部の型が言語デフォルトのシリアライザが使われてしまった・・・ →Aerospikeのクライアントライブラリは、型変換とかうまくやってくれない ので、実装するときにケアしてあげないといけない • あといくつかAerospike側のバグもいくつか踏んだ・・・ →クライアントライブラリのバグは、細かく報告したら、報告後30分くらい でバージョンアップリリースされたので、分かればサポートは早かった
21.
Aerospikeをプロダクションで使うなら、 設定や仕組みをちゃんと理解して設計しましょう まとめ
22.
ご静聴ありがとうございました
Download










![キー設計②(KEY_BUSY対策)
とはいえ、キャンペーン情報などをキーにしたいケースもありますよね
Aerospikeに、Bin単位でインクリメントや追加するようなAPIもあるし・・・
• キーを分散しておく(例えばキャンペーン毎に必ず10キー用意しておく)
→それでもあんまり多いと耐えられない
• サーバ内で値をキャッシュし、10秒に一回PUTする
→サーバ数が数万とか無ければ回るんじゃないか
→更新するタイミングをちょっとずつずらせればベスト
[KEY_BUSY対策案]](https://image.slidesharecdn.com/aerospikev1-160303085009/85/Aerospike-15-320.jpg)
![• write_block_size(最大1MB)を超える値は入れられない
→超えるとRecord too bigエラーが出ます
• 逆に値が大きすぎると、期待したパフォーマンスが出ない
→通信コスト
→ディスクIO
だいたい50b t 1kbくらいが良さそう
値の設計
[長さの話]
• だいたい50byte~1kbくらいが良さそう
→リリース前に、本番のデータを入れてレイテンシの検証をした方がいい
[キーの話]
• Aerospikeに保存される際、キーがハッシュ化されて取り出せなくなるので、
必要ならBinのひとつを使ってキーの値を入れておくといいかもしれない
※オプションをつけるとScanやクエリの時は取り出せるようになります](https://image.slidesharecdn.com/aerospikev1-160303085009/85/Aerospike-16-320.jpg)