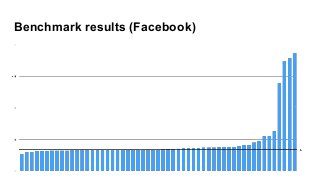
Presto query optimizer: pursuit of performance
The talk from DataWorks Summit 2018 in San Jose, CA
https://dataworkssummit.com/san-jose-2018/session/presto-query-optimizer-pursuit-of-performance/
Folow us at @starburstdata and our blog:
https://www.starburstdata.com/technical-blog/








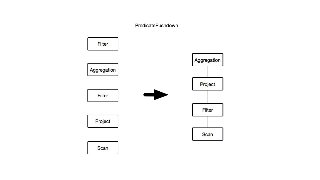


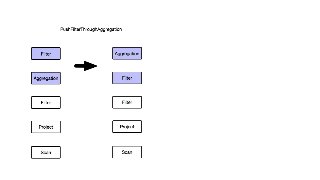
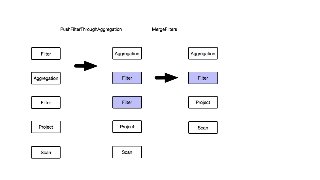
![Migrating from monolithic optimizers to rules
● Fallback behavior
● Controlled via config option or
per-query session property
● Removed after a few releases
optimizers = [
RuleBasedOptimizer(
legacy = LimitPushdown,
rules = [
PushLimitThroughProject,
PushLimitThroughUnion,
PushLimitThroughJoin
]
),
PredicatePushdown,
PruneUnusedColumns,
AddExchanges,
EliminateCrossJoins,
...
]](https://image.slidesharecdn.com/prestooptimizer-dataworkssummit2018-180626163206/85/Presto-query-optimizer-at-DataWorks-Summit-2018-16-320.jpg?cb=1530030976)
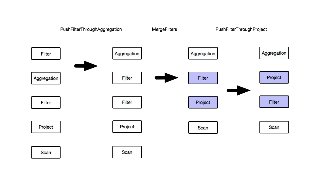
![Adding cost-aware optimizers
● Just another rule
● Can reason about cost
optimizers = [
RuleBasedOptimizer(
rules = [
PushLimitThroughProject,
PushLimitThroughUnion,
PushLimitThroughJoin,
ReorderJoins
]
),
...
]
class ReorderJoins {
ReorderJoins(CostComparator) { ... }
Pattern getPattern() { ... }
Node apply(Node) { ... }
}](https://image.slidesharecdn.com/prestooptimizer-dataworkssummit2018-180626163206/85/Presto-query-optimizer-at-DataWorks-Summit-2018-17-320.jpg?cb=1530030976)