Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
genroku
PPTX, PDF
82 views
文献データベースを使ったトレンドワード提示実験
雑誌記事索引と専門用語自動抽出システムを使って、トレンドワードを提示できるか試してみた
Technology
◦
Related topics:
Natural Language Processing
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 18
2
/ 18
3
/ 18
4
/ 18
5
/ 18
6
/ 18
7
/ 18
8
/ 18
9
/ 18
10
/ 18
11
/ 18
12
/ 18
13
/ 18
14
/ 18
15
/ 18
16
/ 18
17
/ 18
18
/ 18
More Related Content
PDF
PyData Tokyo Tutorial & Hackathon #1
by
Akira Shibata
PDF
Gunosy go2015 06-02
by
Yuta Kashino
PDF
20150128 cross2015
by
Akira Shibata
PDF
Web API入門
by
Masao Takaku
PDF
大規模データ時代に求められる自然言語処理
by
Preferred Networks
PDF
bigdata2012nlp okanohara
by
Preferred Networks
PDF
Survey of Scientific Publication Analysis by NLP and CV
by
Shintaro Yamamoto
PDF
Deep Learningと自然言語処理
by
Preferred Networks
PyData Tokyo Tutorial & Hackathon #1
by
Akira Shibata
Gunosy go2015 06-02
by
Yuta Kashino
20150128 cross2015
by
Akira Shibata
Web API入門
by
Masao Takaku
大規模データ時代に求められる自然言語処理
by
Preferred Networks
bigdata2012nlp okanohara
by
Preferred Networks
Survey of Scientific Publication Analysis by NLP and CV
by
Shintaro Yamamoto
Deep Learningと自然言語処理
by
Preferred Networks
Similar to 文献データベースを使ったトレンドワード提示実験
PDF
[DLHacks]Topic‑Aware Neu ral KeyphraseGenerationforSocial Media Language
by
Deep Learning JP
PDF
論文紹介:PaperRobot: Incremental Draft Generation of Scientific Idea
by
HirokiKurashige
PDF
GeneratingWikipedia_ICLR18_論文紹介
by
Masayoshi Kondo
PDF
大規模データに基づく自然言語処理
by
JunSuzuki21
PPTX
Neural Models for Information Retrieval
by
Keisuke Umezawa
PDF
大規模言語モデルとChatGPT
by
nlab_utokyo
PDF
Twitterにおける即時話題推定技術「どたばたかいぎ」の開発
by
Eric Sartre
PDF
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学)
by
Yuya Unno
PDF
LLM+LangChainで特許調査・分析に取り組んでみた
by
KunihiroSugiyama1
PDF
Lab-ゼミ資料-5-20150512
by
Yuki Ogasawara
PPTX
Interop2017
by
tak9029
PDF
リクルート式 自然言語処理技術の適応事例紹介
by
Recruit Technologies
PDF
学術情報流通のための識別子とメタデータDBを対象とした融合研究シーズ探索 - 超高層物理学分野における観測データを例として -
by
National Institute of Informatics
PDF
050830 openforum
by
Ikki Ohmukai
PPTX
opac検索ログさらなるビジョン
by
genroku
[DLHacks]Topic‑Aware Neu ral KeyphraseGenerationforSocial Media Language
by
Deep Learning JP
論文紹介:PaperRobot: Incremental Draft Generation of Scientific Idea
by
HirokiKurashige
GeneratingWikipedia_ICLR18_論文紹介
by
Masayoshi Kondo
大規模データに基づく自然言語処理
by
JunSuzuki21
Neural Models for Information Retrieval
by
Keisuke Umezawa
大規模言語モデルとChatGPT
by
nlab_utokyo
Twitterにおける即時話題推定技術「どたばたかいぎ」の開発
by
Eric Sartre
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学)
by
Yuya Unno
LLM+LangChainで特許調査・分析に取り組んでみた
by
KunihiroSugiyama1
Lab-ゼミ資料-5-20150512
by
Yuki Ogasawara
Interop2017
by
tak9029
リクルート式 自然言語処理技術の適応事例紹介
by
Recruit Technologies
学術情報流通のための識別子とメタデータDBを対象とした融合研究シーズ探索 - 超高層物理学分野における観測データを例として -
by
National Institute of Informatics
050830 openforum
by
Ikki Ohmukai
opac検索ログさらなるビジョン
by
genroku
文献データベースを使ったトレンドワード提示実験
1.
文献データベース を使ったトレンド ワード提示実験 2018年9月1日 CODE4LIB JAPAN カンファレンス
2018 東京大学・前田朗
2.
時系列で登録文献を追えば、 トレンドワードが出せるかも? ●図書館リソースを使おう! ●リアルタイム性が低いであろうこと は、ひとまず気にしない ●面白い結果がでればよし
3.
雑誌記事索引を使おう! ●国立国会図書館がOAI-PHMで提供 ●http://iss.ndl.go.jp/information/api/oai-pmh_info/ ●OAI-PMHなら日付指定でデータをとれる ●OAI-PMHのクライアントは自作 ●データ取得はPerl ●XMLからタイトル情報の取得は、Pytonの Beautifulesoup ●OAI-PMHの既存プログラムを使えるようにする より、自作のほうが話がはやい
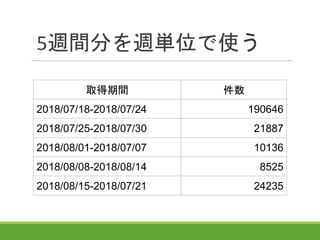
4.
5週間分を週単位で使う 取得期間 件数 2018/07/18-2018/07/24 190646 2018/07/25-2018/07/30
21887 2018/08/01-2018/07/07 10136 2018/08/08-2018/08/14 8525 2018/08/15-2018/07/21 24235
5.
専門用語自動抽出システム Python版TermExtractに決めた! ● テキストから専門用語とその重要度を提示 ● いくつかの重要度を組み合わせて使える ○
TF (Term Frequency) ○ Frequencey ○ IDF ○ LR ● 自分が開発担当という身も蓋もない選定理由が... http://gensen.dl.itc.u-tokyo.ac.jp/pytermextract/
6.
言選Web (専門用語自動抽出システムのWeアプリ版) 自然言語処理(しぜんげんごしょり、英語: natural language
processing、略称:NLP)は、人間 が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言 語学の一分野である。「計算言語学」(computational linguistics)との類似もあるが、自然言語 処理は工学的な視点からの言語処理をさすのに対して、計算言語学は言語学的視点を重視す る手法をさす事が多い[1]。データベース内の情報を自然言語に変換したり、自然言語の文章を より形式的な(コンピュータが理解しやすい)表現に変換するといった処理が含まれる。応用例と しては予測変換、IMEなどの文字変換が挙げられる。 自然言語の理解をコンピュータにさせることは、自然言語理解とされている。自然言語理解と、 自然言語処理の差は、意味を扱うか、扱わないかという説もあったが、最近は数理的な言語解 析手法(統計や確率など)が広められた為、パーサ(統語解析器)などが一段と精度や速度が上 がり、その意味合いは違ってきている。もともと自然言語の意味論的側面を全く無視して達成で きることは非常に限られている。このため、自然言語処理には形態素解析と構文解析、文脈解 析、意味解析などをSyntaxなど表層的な観点から解析をする学問であるが、自然言語理解は、 意味をどのように理解するかという個々人の理解と推論部分が主な研究の課題になってきてお り、両者の境界は意思や意図が含まれるかどうかになってきている。 https://ja.wikipedia.org/wiki/自然言語処理 から抜粋
7.
DFとIDF ● DF (Document
Frequency) ○ 用語を含むドキュメント数 / 総ドキュメント数 ○ たとえば、「犬」という語が5ドキュメント中の3ドキュメント にでてくるのであれば、 ⅗ になる ○ ドキュメント中の特徴的な語ほど数値が小さくなる ● IDF (Inverted Document Frequency) ○ DFの逆数 ○ たとえば、DFが ⅗ なら、IDFは 5/3 ○ ドキュメント中の特徴的な語ほど数値が大きくなる IDFが今回のメインの指標
8.
IDF リアルタイム検知基盤 5.0 動的負荷分散機能 5.0 磁性体ナノ構造
5.0 界面垂直磁気 5.0 ダブルクラッドBi添加石英光ファイバ 5.0 利得特性 5.0 FEAL 5.0 ビットスライス実装 5.0 バイトスライス実装 5.0 付け 5.0 集積導波路形半導体薄膜DFBレーザ 5.0 sモノリシック集積型シリコン光変調器 5.0 カラー映像 5.0 ※2018/8/8-2018/8/14 のデータからの結果 ドキュメント総数が多いと細かい重要度ランキングは厳しい
9.
ドキュメント中の用語出現 頻度を加味してみる ● TF (Term
Frequency) ○ 複合語中の語もカウント ○ たとえば、「図書館」と「公共図書館」が1回 づつ含まれるときに、「図書館」のTFを2とカ ウントする ● Frequency ○ 複合語中の語はカウントしない メジャーな TFIDF (TFとIDFのか け合わせ)でためしてみる
10.
TFIDF 者 490.0 研究 489.0 性
436.0 教育 414.0 of 395.0 日本 335.0 化 332.0 地域 264.0 法 260.0 会 246.0 社会 228.0 報告 215.0 タキイ 205.0 ※2018/8/8-2018/8/14 のデータからの結果 ありきたりな語ばかりで、これはちょっと…
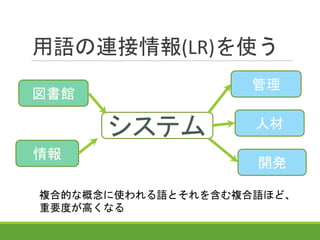
11.
用語の連接情報(LR)を使う 図書館 情報 システム 管理 開発 人材 複合的な概念に使われる語とそれを含む複合語ほど、 重要度が高くなる
12.
FLRIDF (Fequency ×
LR × IDF) 研究 36775.46872576881 日本 11076.069338894551 教育 11039.060829617707 人 6315.783403505855 地域 5529.479360663172 開発 5386.650164991226 社会 4603.838398553972 可能性 4147.825405415286 国際関連情報 4099.629431532681 平成 3244.3470837751006 学校 3141.060967252944 力 3045.488466568212 ※2018/8/8-2018/8/14 のデータからの結果 Frequencyの影響が大きいか?
13.
LRIDF (LR ×
IDF) 研究者等 739.3607994530884 教育消費者 627.6838055668969 支援者支援学 607.7753637962398 教育支援事業 599.6933079502791 社会科教育 591.4665950343987 数学教育学研究 589.439202619568 情報法 504.3245700707695 制御性 475.7789986140733 比較研究者 470.45576447665206 数学化 458.23054965287986 機能研究 448.47859812635 環境教育講演会 446.4600691944748 ※2018/8/8-2018/8/14 のデータからの結果 このくらいが、そこそこ面白そう! そこそこ、よくできました!
14.
まとめ ● せっかくの図書館リソースを使おう! ● 専門用語自動抽出システム(言選Web やTermextractほか)を使おう! ●
結果を気にせずためしてみよう!
15.
おまけ いろいろとパラメータ調整してみた
16.
FLRIDF ver 2 研究
7310460.0 教育 2538768.0 日本 739032.0 者 548744.0 社会 481712.0 地域 443118.0 性 414072.0 可能性 351111.3386491527 人 326960.0 支援 294872.0 化 292160.0 指導 255328.0 開発 241800.0
17.
FLRIDF ver3 者 2.0723197371374564e+25 教育
1.9867815964387044e+25 研究 1.7825290331377898e+25 性 9.392351096371422e+24 研究者 1.602260248999327e+24 教育研究 3.994081137863513e+23 化 1.4538949854085764e+23 指導者 5.8708606848005394e+22 支援者 4.554914406901245e+22 学習者 3.783403615609319e+22 研究会 3.3823198305769885e+22 技術者 2.214815383866987e+22 事業者 1.8535029269069891e+22 経営者 1.7420281114802677e+22
18.
LRIDF ver 4 研究
288880137360.0 教育 134277978288.0 者 43017139648.0 性 28575936864.0 研究者 9293214815.999998 化 7759769600.0 社会 5273782976.0 教育研究 4180081512.0 指導者 3752938608.0 会 3344021415.0 日本 3290170464.0 学習者 3148065935.9999995
Download





![言選Web
(専門用語自動抽出システムのWeアプリ版)
自然言語処理(しぜんげんごしょり、英語: natural language processing、略称:NLP)は、人間
が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言
語学の一分野である。「計算言語学」(computational linguistics)との類似もあるが、自然言語
処理は工学的な視点からの言語処理をさすのに対して、計算言語学は言語学的視点を重視す
る手法をさす事が多い[1]。データベース内の情報を自然言語に変換したり、自然言語の文章を
より形式的な(コンピュータが理解しやすい)表現に変換するといった処理が含まれる。応用例と
しては予測変換、IMEなどの文字変換が挙げられる。
自然言語の理解をコンピュータにさせることは、自然言語理解とされている。自然言語理解と、
自然言語処理の差は、意味を扱うか、扱わないかという説もあったが、最近は数理的な言語解
析手法(統計や確率など)が広められた為、パーサ(統語解析器)などが一段と精度や速度が上
がり、その意味合いは違ってきている。もともと自然言語の意味論的側面を全く無視して達成で
きることは非常に限られている。このため、自然言語処理には形態素解析と構文解析、文脈解
析、意味解析などをSyntaxなど表層的な観点から解析をする学問であるが、自然言語理解は、
意味をどのように理解するかという個々人の理解と推論部分が主な研究の課題になってきてお
り、両者の境界は意思や意図が含まれるかどうかになってきている。
https://ja.wikipedia.org/wiki/自然言語処理 から抜粋](https://image.slidesharecdn.com/trendwordzassku-180901231324/85/slide-6-320.jpg)



















![[DLHacks]Topic‑Aware Neu ral KeyphraseGenerationforSocial Media Language](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackstakgfinal-190820070754-thumbnail.jpg?width=640&height=640&fit=bounds)













