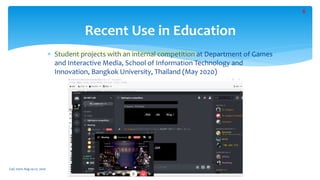
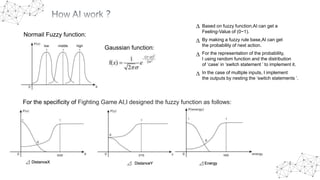
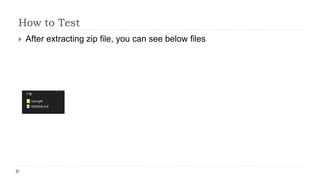
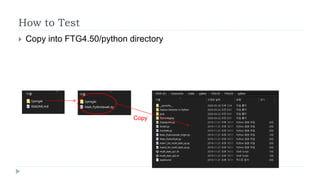
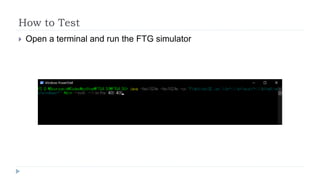
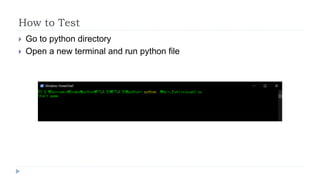
The document outlines the 2020 Fighting Game AI Competition, detailing the development of various AIs for fighting games, with a focus on the FightingICE platform. It describes participant entries from several countries, competition rules, and the technologies used, including deep reinforcement learning and Monte Carlo Tree Search. The winners demonstrated advanced techniques such as adaptive learning and opponent modeling, with the top AI being erhea_pi, followed by tera thunder and butcherpudge.



















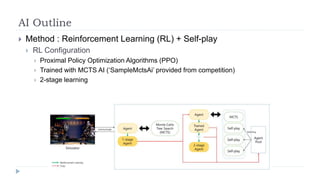

















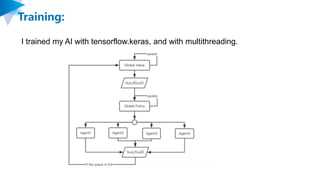
![Algorithm: Reinforcement Learning with PPO
I used model-free reinforcement learning algorithm, Proximal
Policy Optimization, to train my AI.
Following is the clipped surrogate objective which OpenAI
proposed in Proximal Policy Optimization Algorithms, 2017. I
used it as the objective to train my AI and update the weights.
Reference:
Schulman J, Wolski F, Dhariwal P, et al. Proximal Policy
Optimization Algorithms[J]. arXiv: Learning, 2017.](https://image.slidesharecdn.com/2020-fighting-game-artificial-intelligence-competitionforupload-200829011519/85/2020-Fighting-Game-AI-Competition-49-320.jpg)






































![[한국어] Multiagent Bidirectional- Coordinated Nets for Learning to Play StarCra...](https://cdn.slidesharecdn.com/ss_thumbnails/multiagentbidirectional-coordinatednetsforlearningtoplaystarcraftcombatgames-170623022918-thumbnail.jpg?width=640&height=640&fit=bounds)


























