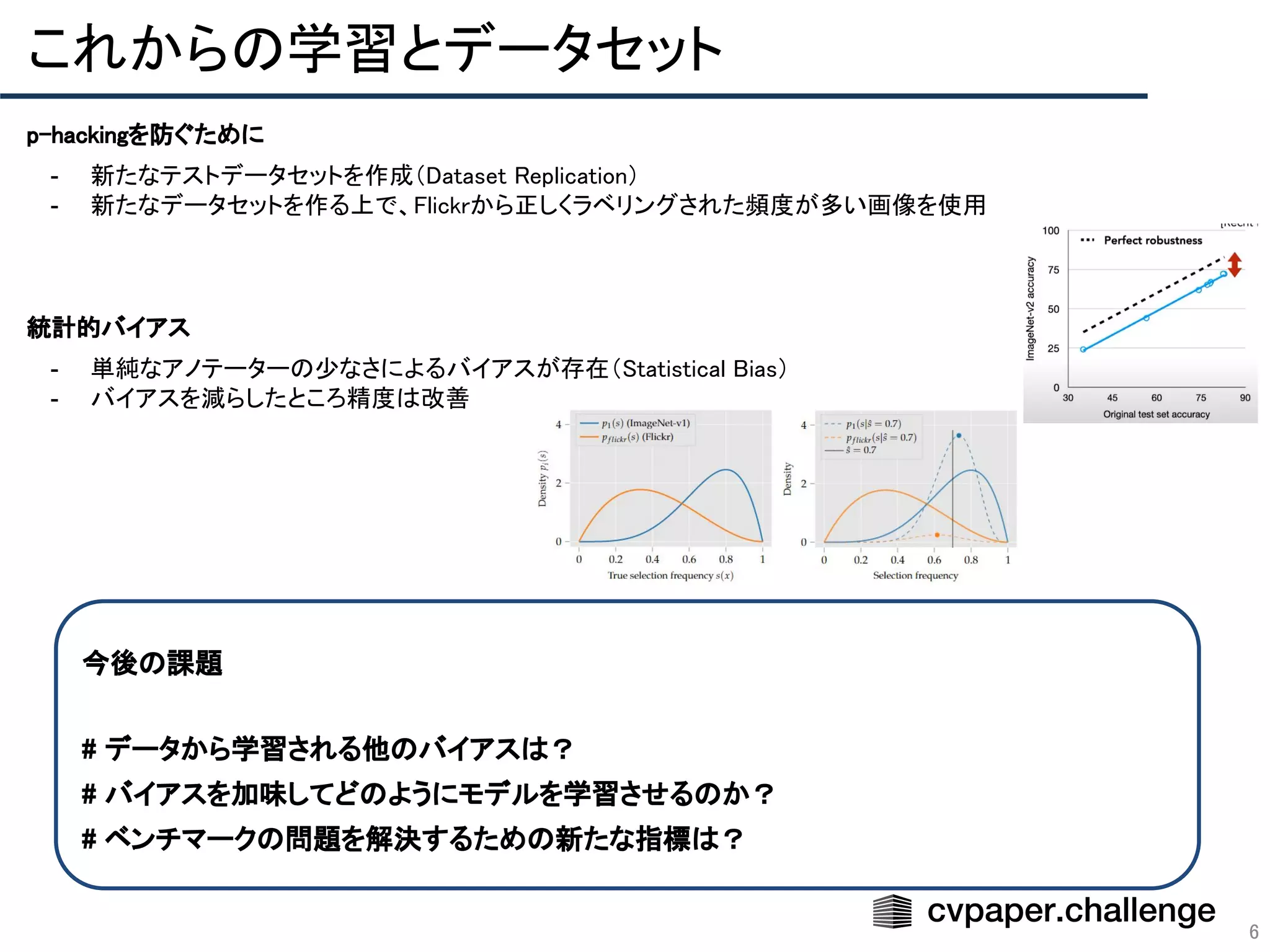
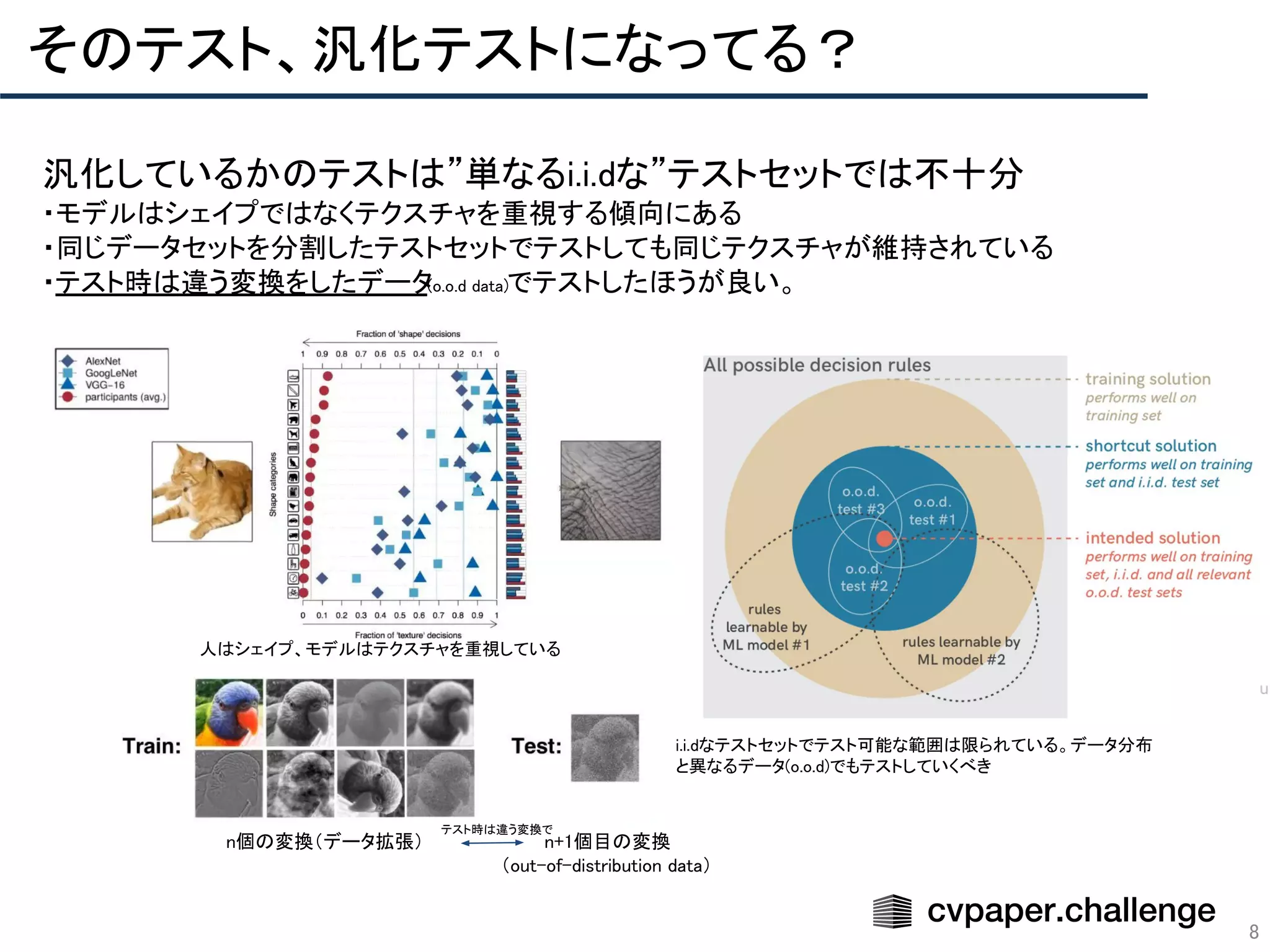
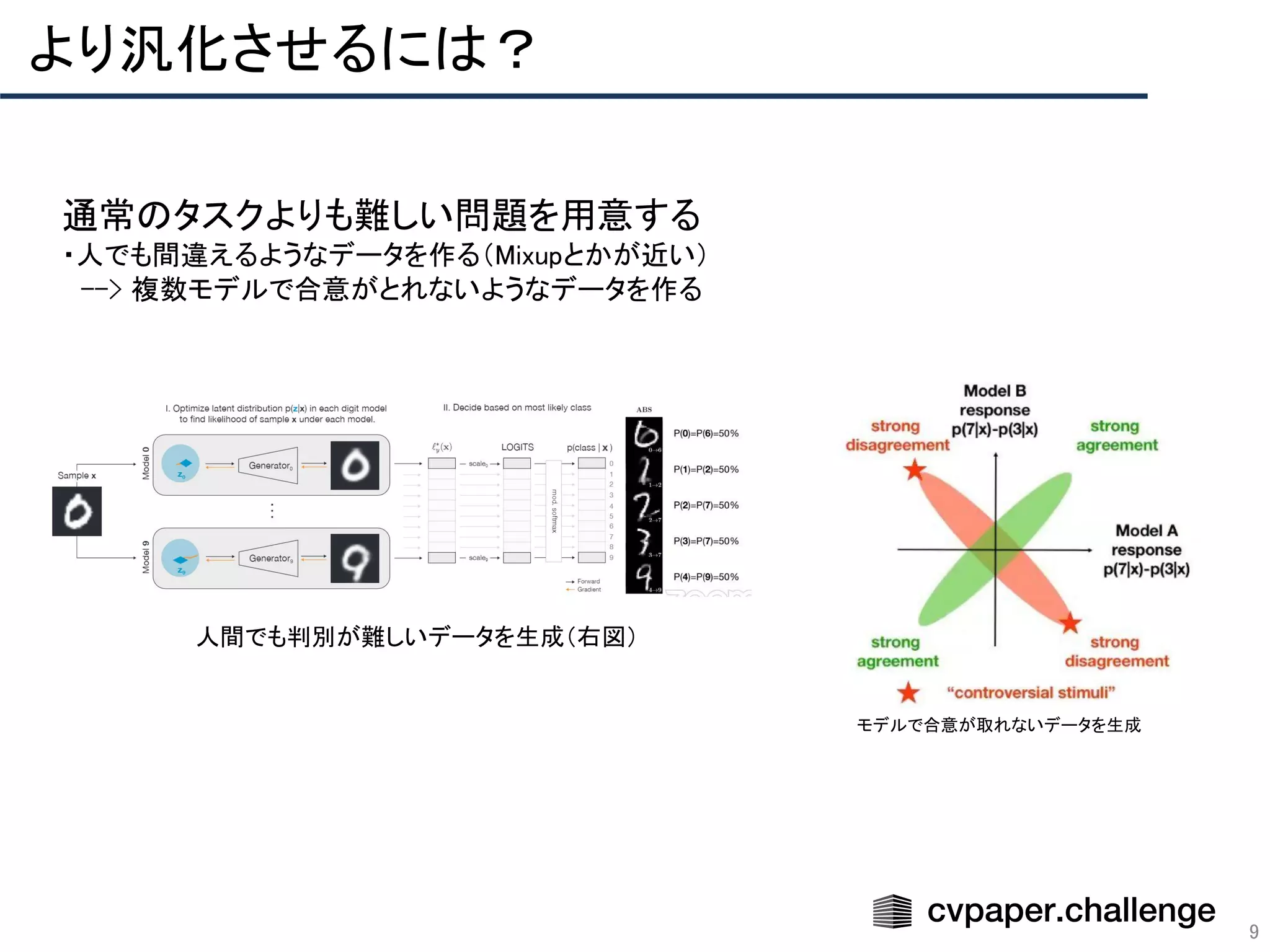
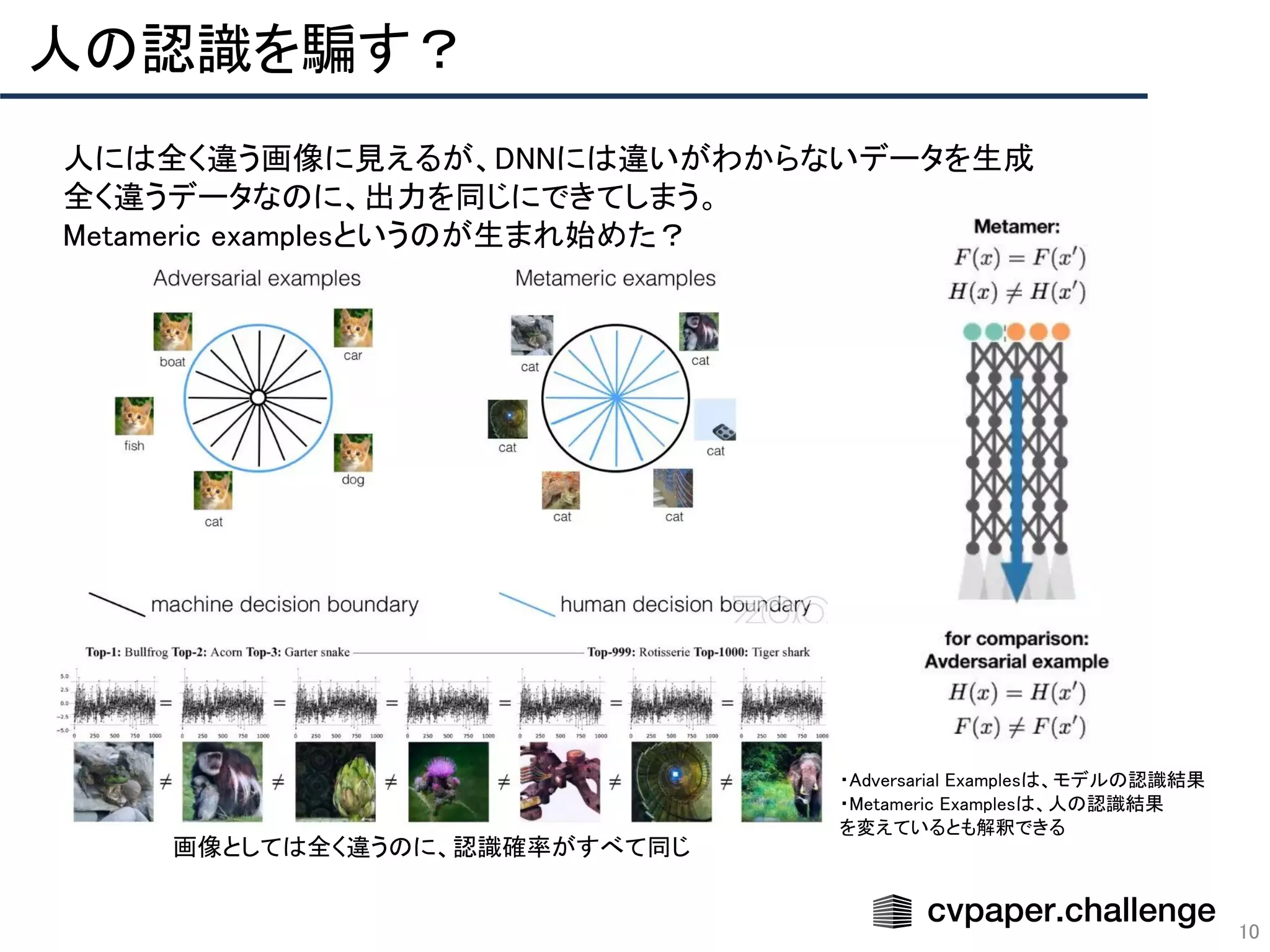
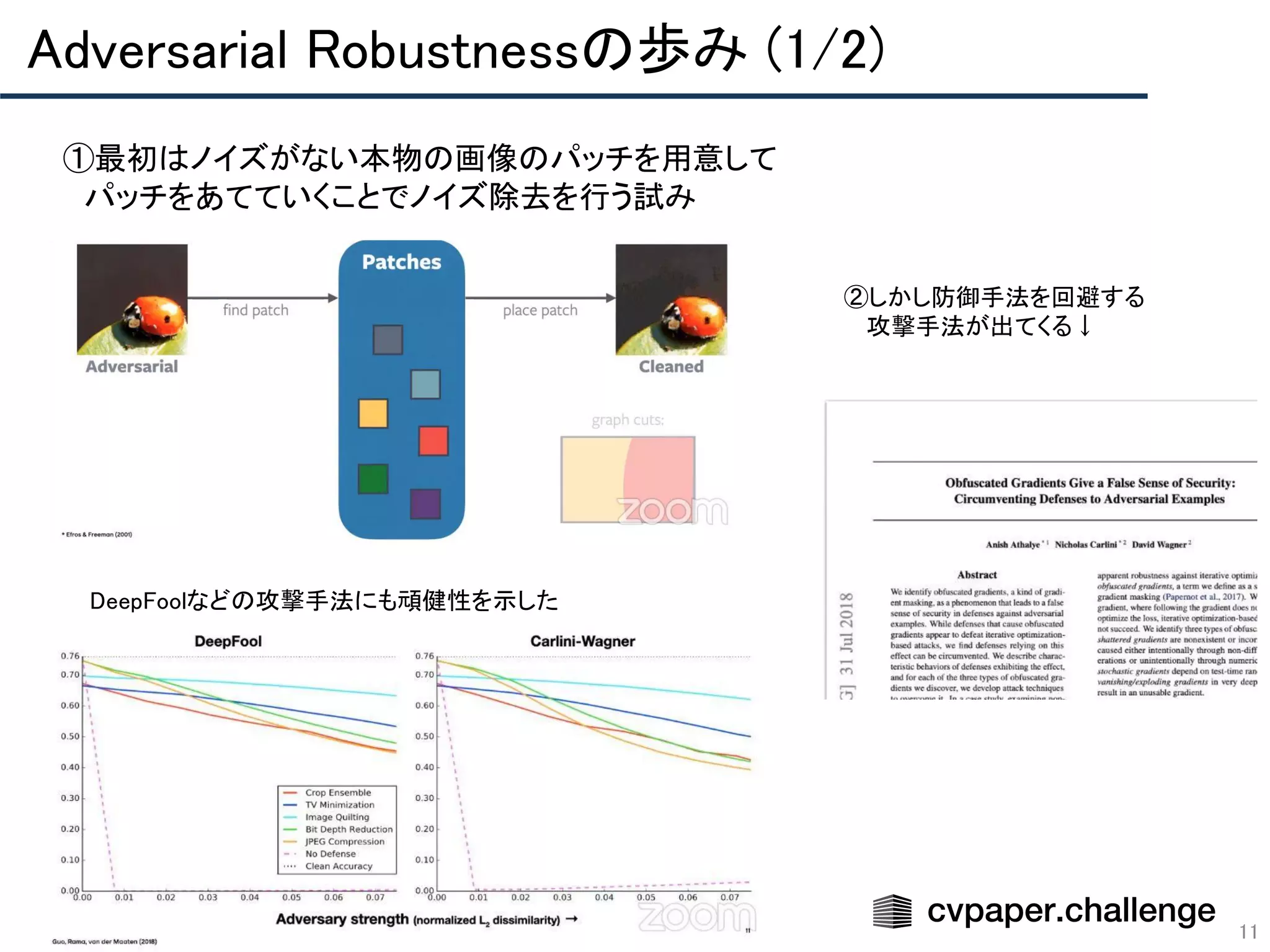
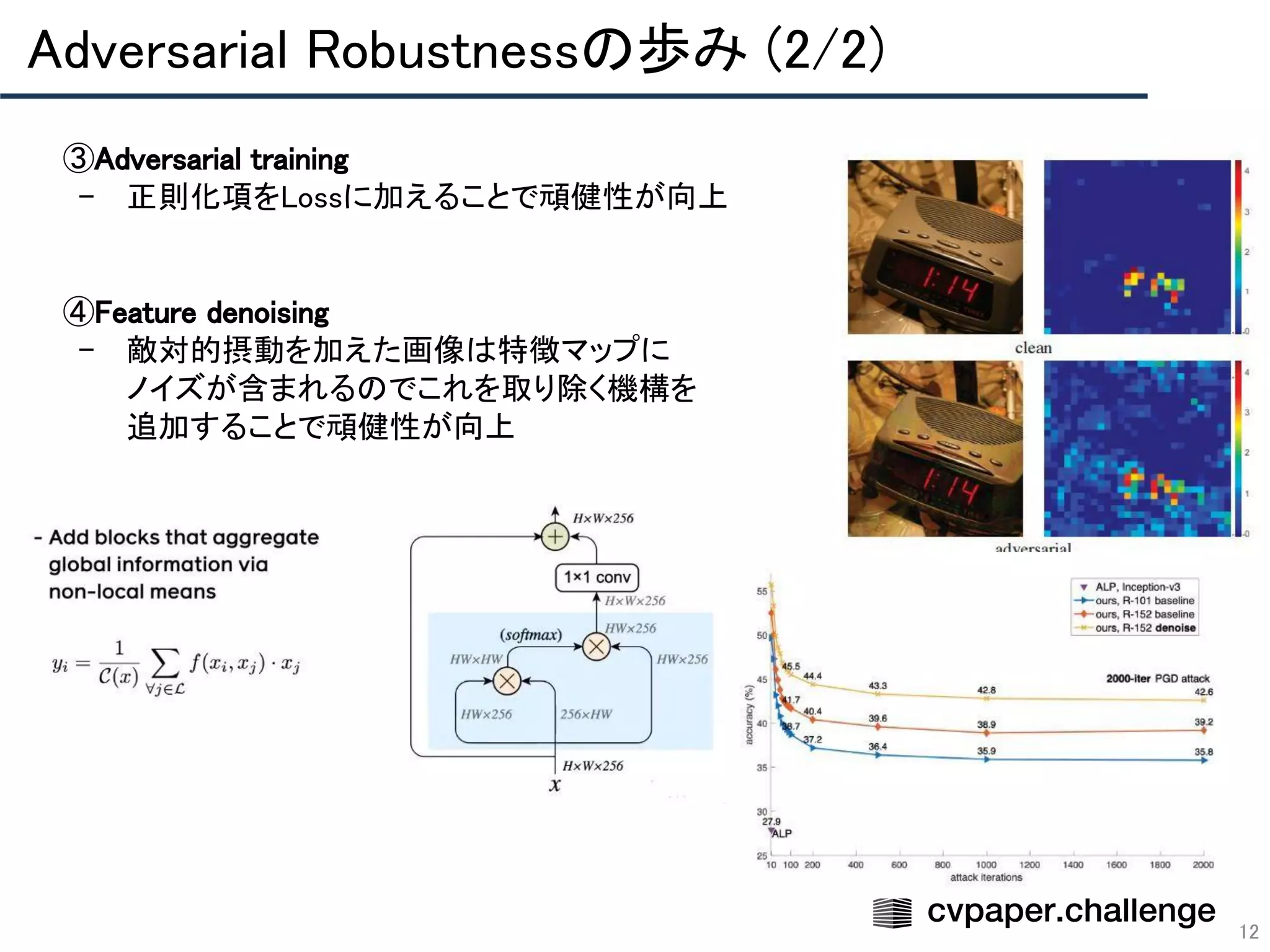
Download to read offline

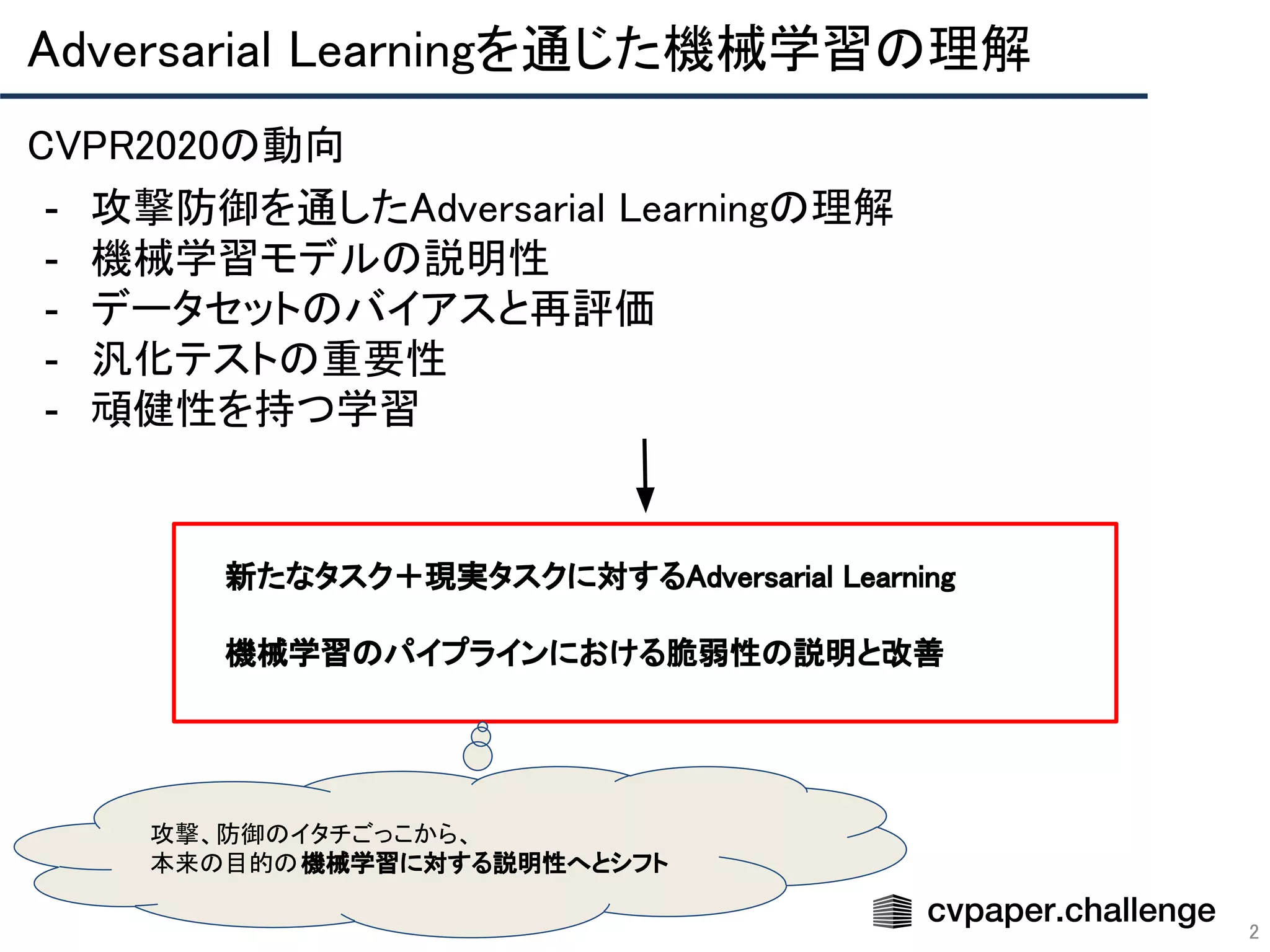
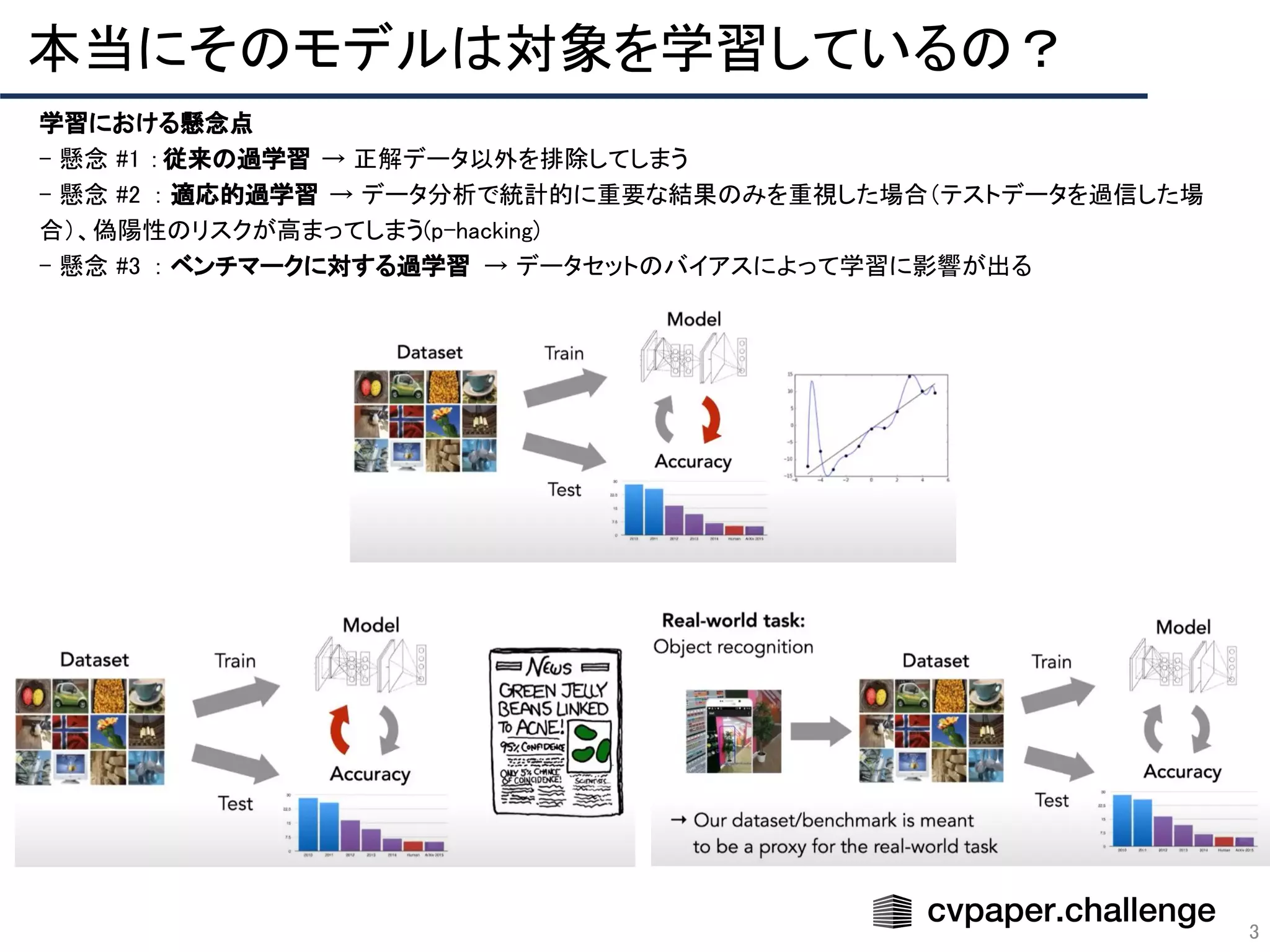
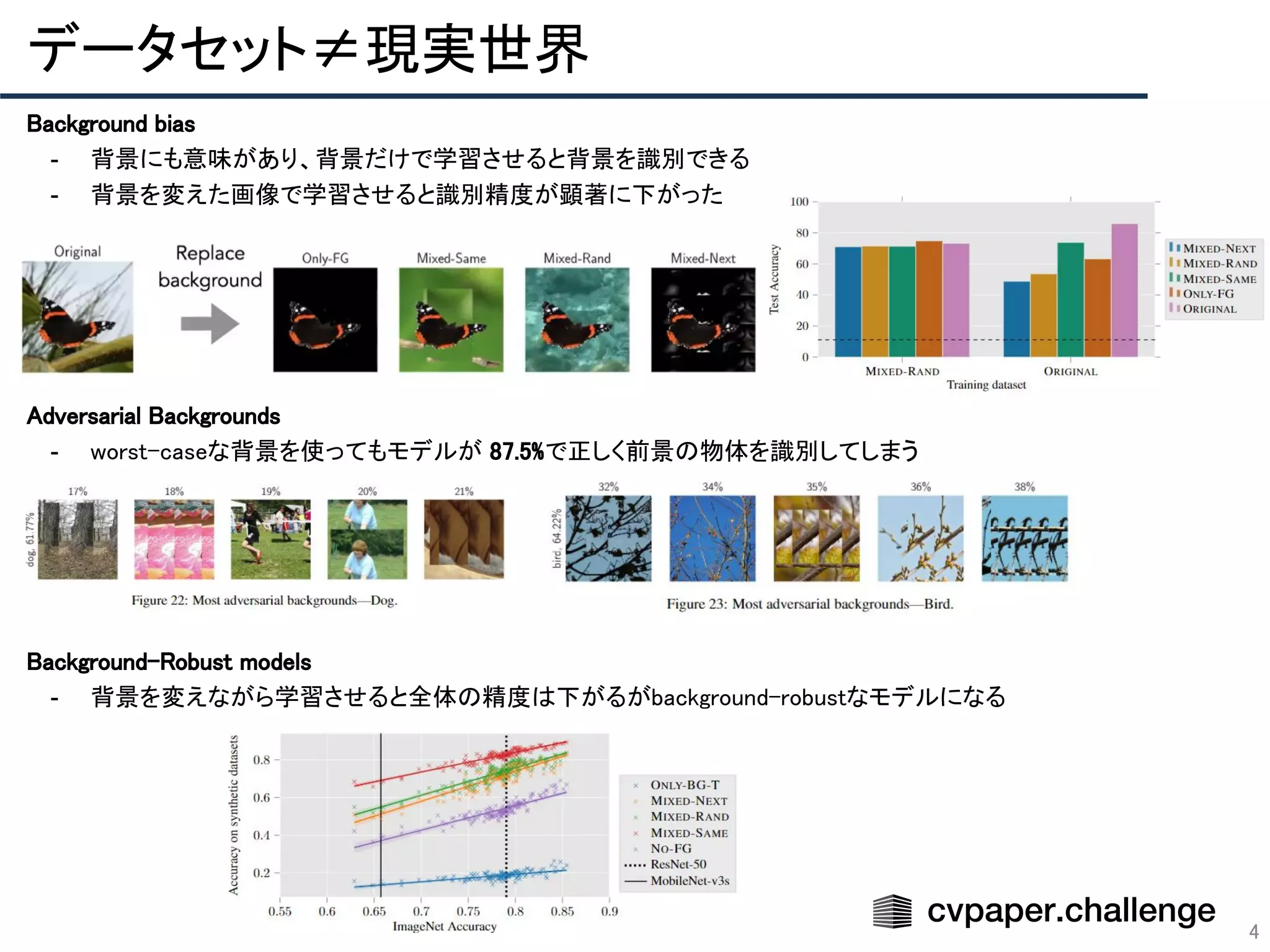
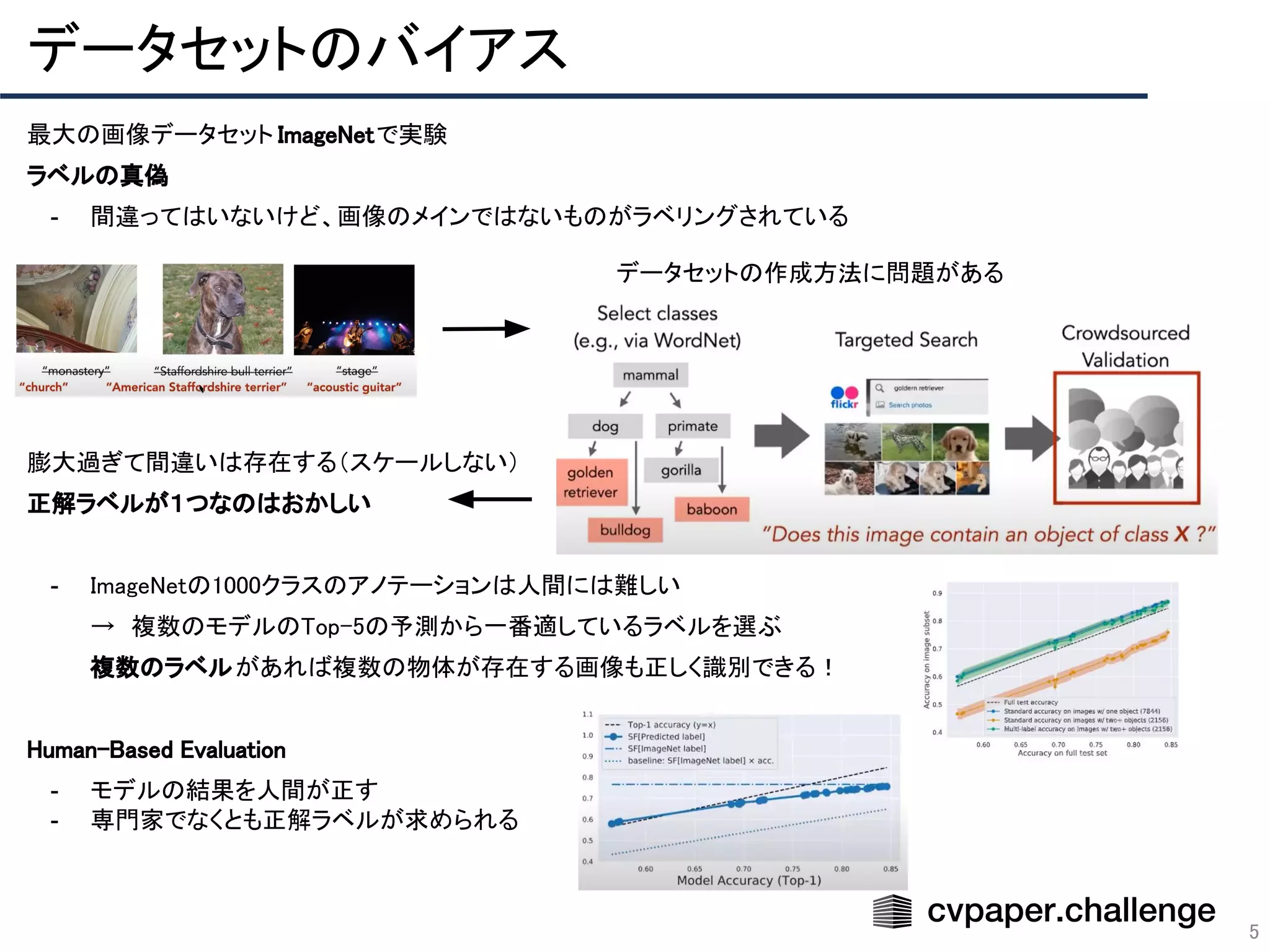




「CVPR 2020 網羅的サーベイ」により作成された Adversarial Learning エリアのメタサーベイ資料です。 CVPR 2020 網羅的サーベイ: http://xpaperchallenge.org/cv/survey/cvpr2020_summaries/listall/ cvpaper.challengeはコンピュータビジョン分野の今を映し、トレンドを創り出す挑戦です。論文サマリ作成・アイディア考案・議論・実装・論文投稿に取り組み、凡ゆる知識を共有します。2020の目標は「トップ会議に30+本投稿」することです。 http://xpaperchallenge.org/cv/










![[全脳アーキテクチャ若手の会45回カジュアルトーク]敵対的サンプル](https://cdn.slidesharecdn.com/ss_thumbnails/20191129ltadversarialexamplefukuchiv2-191130064242-thumbnail.jpg?width=640&height=640&fit=bounds)















![[NeurIPS2018論文読み会] Adversarial vulnerability for any classifier](https://cdn.slidesharecdn.com/ss_thumbnails/neurips2018yomikai-181221060712-thumbnail.jpg?width=640&height=640&fit=bounds)






