Download as PDF, PPTX

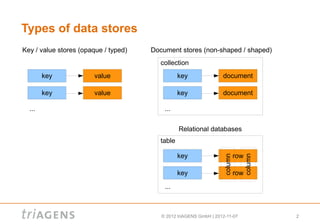

![Key / value stores (typed)
Keys are mapped to values
Values have simple type information attached
Type information is stored per value
Values can still be heterogenous
key type value
key type value
Example values:
number: 25 => numeric, store can do something with it
list: [ 1, 2, 3 ] => list, store can do something with it
© 2012 triAGENS GmbH | 2012-11-07 4](https://image.slidesharecdn.com/jansteemannnosqlcolumndb-121130023353-phpapp01/85/Introduction-to-column-oriented-databases-4-320.jpg)














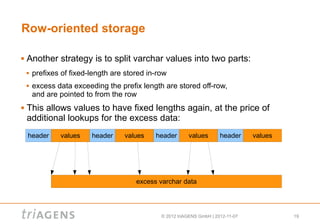


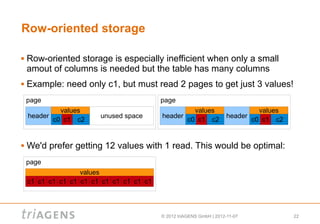













Column-oriented databases store data by column rather than by row. This allows fast retrieval of entire columns of data with one read operation. Column-oriented databases are well-suited for analytical queries that retrieve many rows but only a few columns, as only the needed columns are read from disk. Row-oriented databases are better for transactional queries that retrieve or update individual rows. The type of data storage - row-oriented or column-oriented - depends on the types of queries that will be run against the data.

![Data Models [DATABASE SYSTEMS: Design, Implementation, and Management]](https://cdn.slidesharecdn.com/ss_thumbnails/coronelpptch02-datamodels-190903105908-thumbnail.jpg?width=640&height=640&fit=bounds)

































































