Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
aitc_jp
PDF, PPTX
441 views
2020年1月25日 AITCシニア成果発表会(5) 自分専用アメダス
<<AITCシニア技術者勉強会>> チーム名:自分専用アメダス 概要:雨量を知りたい
Internet
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 11
2
/ 11
3
/ 11
4
/ 11
5
/ 11
6
/ 11
7
/ 11
8
/ 11
9
/ 11
10
/ 11
11
/ 11
More Related Content
PDF
ITフォーラム2025 先端IT活用推進コミュニティ セッション:オープニング・タイムテーブル
by
aitc_jp
PPTX
ITフォーラム2025 先端IT活用推進コミュニティ セッション1:AITCの活動紹介
by
aitc_jp
PPTX
ITフォーラム2025 先端IT活用推進コミュニティ セッション1:AITCの活動紹介
by
aitc_jp
PDF
ITフォーラム2025 先端IT活用推進コミュニティ セッション5:ビジネスXRの転回
by
aitc_jp
PDF
ITフォーラム2025 先端IT活用推進コミュニティ セッション6:「下り坂の雲」の行き先を灯す、これからのITの使い方
by
aitc_jp
PDF
ITフォーラム2025 先端IT活用推進コミュニティ セッション2:オープンラボの取り組み
by
aitc_jp
PDF
ITフォーラム2025 先端IT活用推進コミュニティ セッション3:空気を読む家スタジオの取り組み
by
aitc_jp
PDF
ITフォーラム2025 先端IT活用推進コミュニティ セッション4:コンテキストコンピューティング研究グループの取り組み
by
aitc_jp
ITフォーラム2025 先端IT活用推進コミュニティ セッション:オープニング・タイムテーブル
by
aitc_jp
ITフォーラム2025 先端IT活用推進コミュニティ セッション1:AITCの活動紹介
by
aitc_jp
ITフォーラム2025 先端IT活用推進コミュニティ セッション1:AITCの活動紹介
by
aitc_jp
ITフォーラム2025 先端IT活用推進コミュニティ セッション5:ビジネスXRの転回
by
aitc_jp
ITフォーラム2025 先端IT活用推進コミュニティ セッション6:「下り坂の雲」の行き先を灯す、これからのITの使い方
by
aitc_jp
ITフォーラム2025 先端IT活用推進コミュニティ セッション2:オープンラボの取り組み
by
aitc_jp
ITフォーラム2025 先端IT活用推進コミュニティ セッション3:空気を読む家スタジオの取り組み
by
aitc_jp
ITフォーラム2025 先端IT活用推進コミュニティ セッション4:コンテキストコンピューティング研究グループの取り組み
by
aitc_jp
More from aitc_jp
PDF
2)AIを活用したウェルビーイングを測定
by
aitc_jp
PDF
4)技術視点でウェルビーイングを考える
by
aitc_jp
PDF
3-2)『空気を読む家』とメタバース駆動開発構想
by
aitc_jp
PDF
2022/04/20 AITCオープンラボ第2回「田園都市国家構想とデジタル政策について」
by
aitc_jp
PDF
ITフォーラム2024 AITCセッション(2)
by
aitc_jp
PDF
1)空気を読む家』のこれまでの取り組み
by
aitc_jp
PDF
ITフォーラム2024 AITCセッション
by
aitc_jp
PDF
2)AIを活用したウェルビーイングを測定
by
aitc_jp
PDF
TForum2023_AITC_2.pdf
by
aitc_jp
PDF
2022/07/22 AITC 第4回オープンラボ「メタバース応用編~空間OSのこれまでとこれから~」セッション2 「空間OSと空気を読む家の実証」
by
aitc_jp
PDF
ITフォーラム2024 AITCセッション(3)
by
aitc_jp
PDF
2022/07/22 AITC 第4回オープンラボ「メタバース応用編~空間OSのこれまでとこれから~」セッション1 「空間OSとメタバース」
by
aitc_jp
PDF
ITフォーラム2024 AITCセッション(5)
by
aitc_jp
PDF
3-1)『空気を読む家』とメタバース駆動開発構想 空間OS モノと社会をつなげる
by
aitc_jp
PPTX
ITフォーラム2022 先端IT活用推進コミュニティ(5-1)
by
aitc_jp
PPTX
ITフォーラム2022 先端IT活用推進コミュニティ(5-2)
by
aitc_jp
PDF
5)パネルディスカッション:『空気を読む家』×ウェルビーイング/メタバース・Web3
by
aitc_jp
PPTX
ITフォーラム2022 先端IT活用推進コミュニティ(3-1)
by
aitc_jp
PDF
2022/03/23 AITCオープンラボ第1回「メタ―バース入門」
by
aitc_jp
PDF
ITフォーラム2024 AITCセッション(4)
by
aitc_jp
2)AIを活用したウェルビーイングを測定
by
aitc_jp
4)技術視点でウェルビーイングを考える
by
aitc_jp
3-2)『空気を読む家』とメタバース駆動開発構想
by
aitc_jp
2022/04/20 AITCオープンラボ第2回「田園都市国家構想とデジタル政策について」
by
aitc_jp
ITフォーラム2024 AITCセッション(2)
by
aitc_jp
1)空気を読む家』のこれまでの取り組み
by
aitc_jp
ITフォーラム2024 AITCセッション
by
aitc_jp
2)AIを活用したウェルビーイングを測定
by
aitc_jp
TForum2023_AITC_2.pdf
by
aitc_jp
2022/07/22 AITC 第4回オープンラボ「メタバース応用編~空間OSのこれまでとこれから~」セッション2 「空間OSと空気を読む家の実証」
by
aitc_jp
ITフォーラム2024 AITCセッション(3)
by
aitc_jp
2022/07/22 AITC 第4回オープンラボ「メタバース応用編~空間OSのこれまでとこれから~」セッション1 「空間OSとメタバース」
by
aitc_jp
ITフォーラム2024 AITCセッション(5)
by
aitc_jp
3-1)『空気を読む家』とメタバース駆動開発構想 空間OS モノと社会をつなげる
by
aitc_jp
ITフォーラム2022 先端IT活用推進コミュニティ(5-1)
by
aitc_jp
ITフォーラム2022 先端IT活用推進コミュニティ(5-2)
by
aitc_jp
5)パネルディスカッション:『空気を読む家』×ウェルビーイング/メタバース・Web3
by
aitc_jp
ITフォーラム2022 先端IT活用推進コミュニティ(3-1)
by
aitc_jp
2022/03/23 AITCオープンラボ第1回「メタ―バース入門」
by
aitc_jp
ITフォーラム2024 AITCセッション(4)
by
aitc_jp
2020年1月25日 AITCシニア成果発表会(5) 自分専用アメダス
1.
音による降水強度測定の試み 自分専用のアメダスを作るために・・・ 2020年1月25日 AITC勉強会合同発表会 チーム名:自分専用のアメダス 大和田浩美
2.
転倒ます型雨量計 • 気象庁で使っている雨量計です • 転倒ますにたまった雨水の重さで(降水量が0.5ミリに達すると)転倒します。転倒する 時間間隔から降水強度を求めることができます •
価格.comで「転倒ます型雨量計」で検索をすると、10万円前後の商品がでてきます 写真は気象庁の気象科学館 に展示中の雨量計です。 出典:気象友の会会報No197
3.
雨音から降水強度を求められないでしょうか? • 雨音から雨の降り方の特徴をつかむことができれば可能と思われます • そこで、ラズパイに小さなマイクをつけて雨音(実際はシャワー音)を録音してみました •
そしてラズパイ上で、機械学習により、雨音の周波数解析から「雨なし」、「弱い雨」、 「中くらいの雨」、「強い雨」を分類することを試みました 激しい雨 弱い雨
4.
ラズパイを使った雨量計! 簡単でごめんなさい ラズパイ USBマイク (税込399円) モバイル バッテリー 100円ショップ で購入した入れ 物に収めました ふたの上にシャ ワーをかけて音 を録音します
5.
音を採取しました 弱い雨 中くらいの雨 強い雨 弱 中 強 #!/bin/sh date=`date
“+%Y%m%d%H%M”` amixer sset Mic 62 –c 1 arecord –D plughw:1.0 –f cd –r 16000 rec${date}.wav サンプリング周波数: 16000Hz
6.
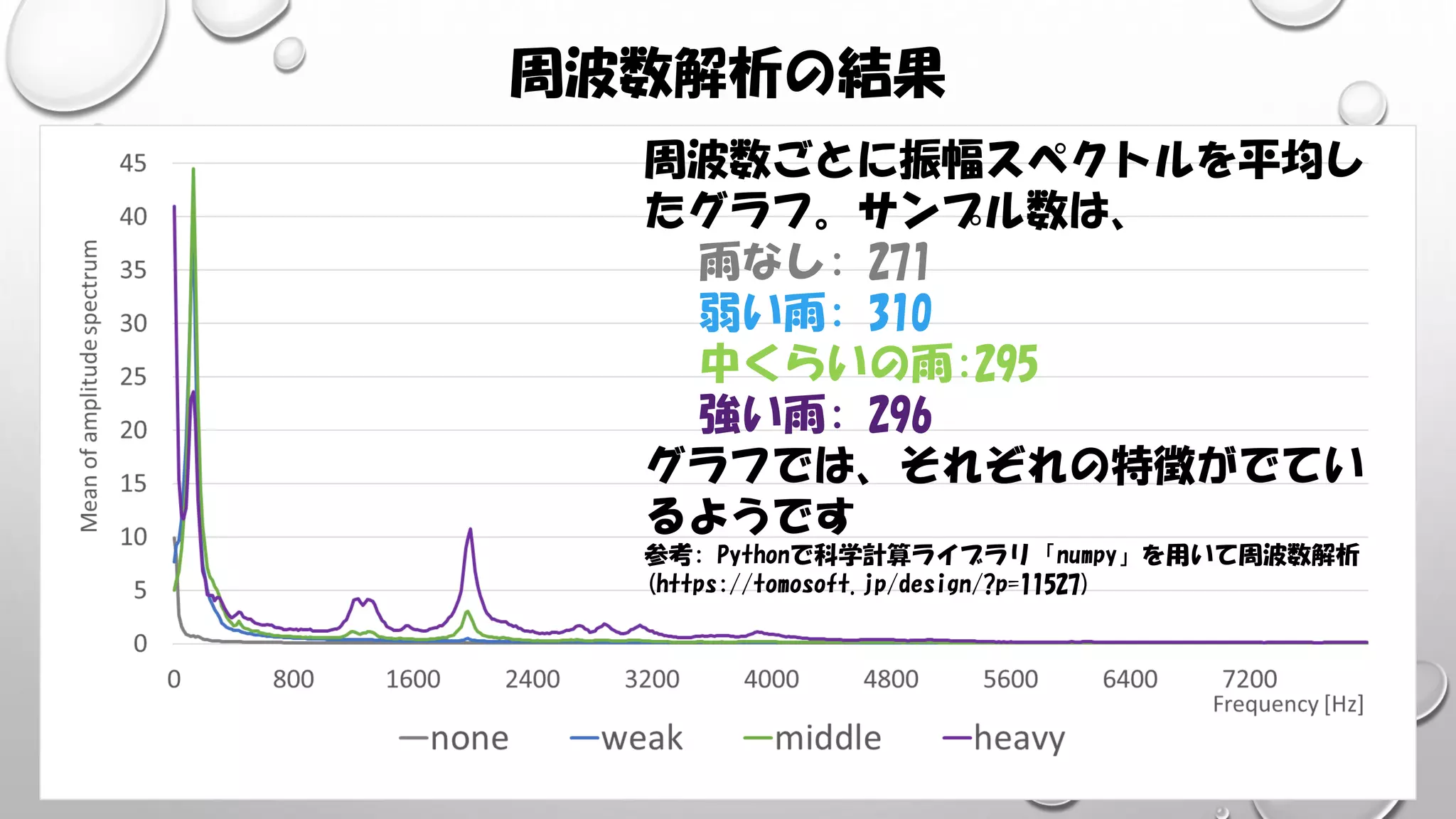
周波数解析の結果 周波数ごとに振幅スペクトルを平均し たグラフ。サンプル数は、 雨なし: 271 弱い雨: 310 中くらいの雨:295 強い雨:
296 グラフでは、それぞれの特徴がでてい るようです 参考: Pythonで科学計算ライブラリ「numpy」を用いて周波数解析 (https://tomosoft.jp/design/?p=11527)
7.
機械学習での判別をしてみました 入力データ ALM列はyで、 雨なし: 0 弱い雨:
1 中くらいの雨:2 強い雨: 3 A~ALL列はxで、各周波数の振幅スペクトル
8.
機械学習での判別をしてみました Pythonのコード import pandas as
pd #pandasをインポート import numpy as np #numpyをインポート from sklearn import model_selection #データ分割のためのmodel_selectionをインポート from keras.models import Sequential #keras.modulesからSequentialをインポート from keras.layers import Dense, Activation #keras.layersからDence,Activationをインポート rain_data = pd.read_csv(“rain_total.csv”,sep=“,”) #全データ読み込み X = rain_data.drop([‘class’],axis=1) #Xとして各周波数ごとの振幅スペクトルを Y = rain_data[‘class’] #Yとして降水強度のクラスを指定する data_train, data_test, label_train, label_test = model_selection.train_test_split(X,Y) #全データをトレーニングデータ(70%)とテストデータ(30%)に分ける #7:3の分割はデフォルト。シャッフルしてから分けてくださる print(len(data_train),len(data_test)) #トレーニングデータの個数を確認 print(len(label_train),len(label_test)) #テストデータの個数を確認
9.
機械学習での判別をしてみました Pythonのコード(続き) model = Sequential()
#シーケンシャルモデルを定義 model.add(Dense(500, input_dim=1000)) #中間層の数500、入力層の数1000 model.add(Activation(‘sigmoid’)) #sigmoidを活性化関数に model.add(Dense(4, input_dim=500)) #出力層の数4 model.add(Activation(‘softmax’)) #softmaxを活性化関数に model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy’]) #optimizerにadamを指定など model.fit(data_train, label_train, nb_epoch=20, batch_size=10) #epoch数20、batch size10で学習 model.metrics_names res = model.evaluate(data_test, label_test, batch_size=1) #テストデータで評価 print(res) #評価結果の確認 print(model.predict(data_test)) #テストデータのXでy’を予測 pre = np.argmax(model.predict(data_test),axis=1) #出力層で一番大きな値をy’とする print(pre) #y’を確認 print(label_test) #テストデータのyを確認 count = 0 for index in range(len(pre)): #各テストデータのyとy’が同じ値なら1として if pre[index] == label_test.values[index]: #正解数をカウントする count = count + 1 print(count,‘/’,len(pre)) #「正解数/全テストデータ数」を確認
10.
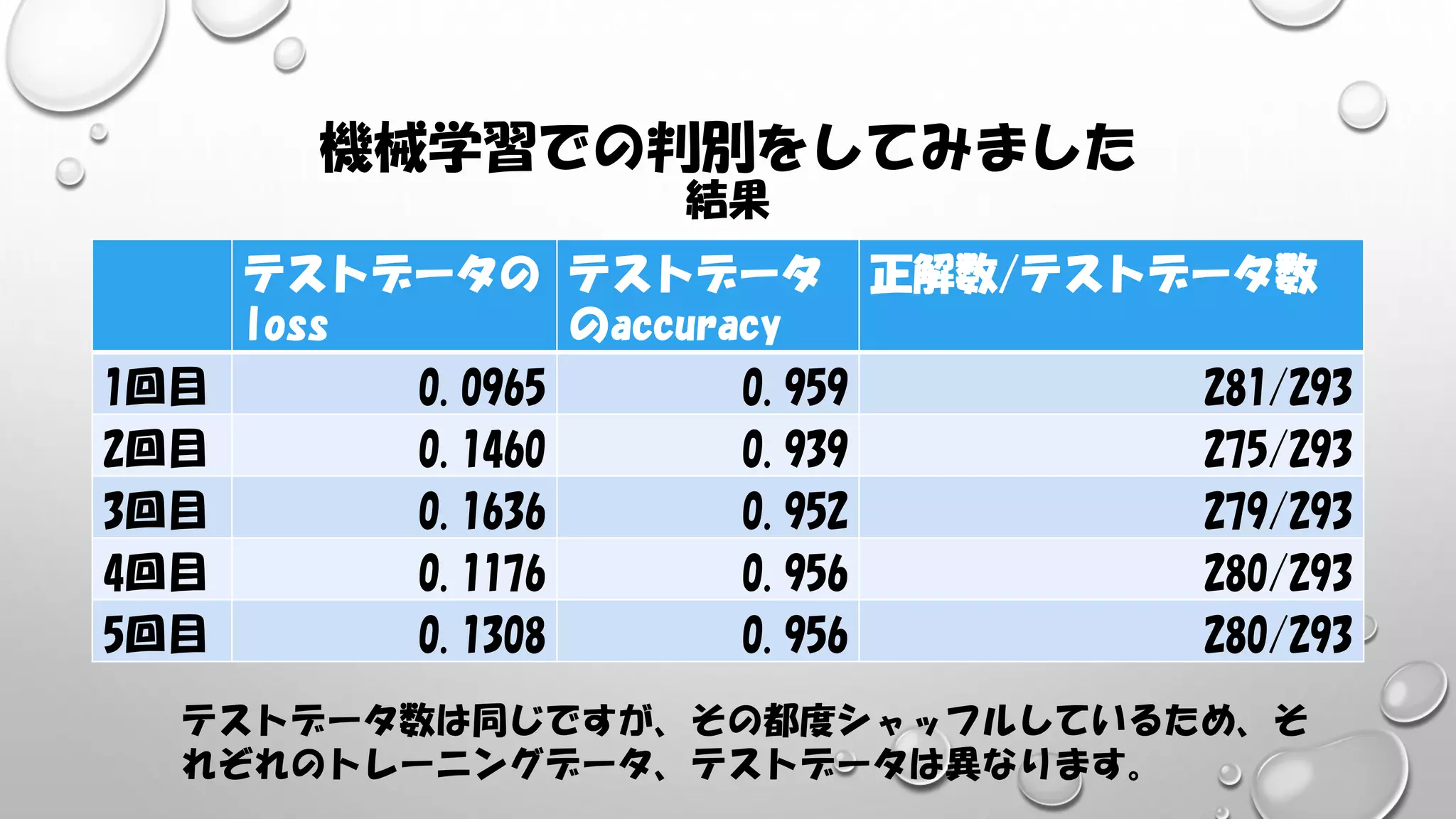
機械学習での判別をしてみました 結果 テストデータの loss テストデータ のaccuracy 正解数/テストデータ数 1回目 0.0965 0.959
281/293 2回目 0.1460 0.939 275/293 3回目 0.1636 0.952 279/293 4回目 0.1176 0.956 280/293 5回目 0.1308 0.956 280/293 テストデータ数は同じですが、その都度シャッフルしているため、そ れぞれのトレーニングデータ、テストデータは異なります。
11.
まとめ • 雨音から降水強度を求める最初の試みとして以下のことを試してみました • USBマイクをつけたラズパイで雨音を録音 •
録音したwavファイルから周波数解析。雨なし、弱い雨、中くらいの雨、強い雨に ついてデータを作成 • 上記データをトレーニングデータとテストデータに分けて機械学習 • 94%以上の正答率が出たので、まったくおかしな試みではないと思いました • ラズパイ起動時に過去のデータセットで機械学習を行い、そのモデルを使ってリアルタ イムに降水強度を推定し、結果を可視化するシステムができれば、自分専用のアメダス も夢ではないかもしれません
Download






![機械学習での判別をしてみました
Pythonのコード
import pandas as pd #pandasをインポート
import numpy as np #numpyをインポート
from sklearn import model_selection #データ分割のためのmodel_selectionをインポート
from keras.models import Sequential #keras.modulesからSequentialをインポート
from keras.layers import Dense, Activation #keras.layersからDence,Activationをインポート
rain_data = pd.read_csv(“rain_total.csv”,sep=“,”) #全データ読み込み
X = rain_data.drop([‘class’],axis=1) #Xとして各周波数ごとの振幅スペクトルを
Y = rain_data[‘class’] #Yとして降水強度のクラスを指定する
data_train, data_test, label_train, label_test = model_selection.train_test_split(X,Y)
#全データをトレーニングデータ(70%)とテストデータ(30%)に分ける
#7:3の分割はデフォルト。シャッフルしてから分けてくださる
print(len(data_train),len(data_test)) #トレーニングデータの個数を確認
print(len(label_train),len(label_test)) #テストデータの個数を確認](https://image.slidesharecdn.com/202001255-200220040302/75/2020-1-25-AITC-5-8-2048.jpg)
![機械学習での判別をしてみました
Pythonのコード(続き)
model = Sequential() #シーケンシャルモデルを定義
model.add(Dense(500, input_dim=1000)) #中間層の数500、入力層の数1000
model.add(Activation(‘sigmoid’)) #sigmoidを活性化関数に
model.add(Dense(4, input_dim=500)) #出力層の数4
model.add(Activation(‘softmax’)) #softmaxを活性化関数に
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy’])
#optimizerにadamを指定など
model.fit(data_train, label_train, nb_epoch=20, batch_size=10) #epoch数20、batch size10で学習
model.metrics_names
res = model.evaluate(data_test, label_test, batch_size=1) #テストデータで評価
print(res) #評価結果の確認
print(model.predict(data_test)) #テストデータのXでy’を予測
pre = np.argmax(model.predict(data_test),axis=1) #出力層で一番大きな値をy’とする
print(pre) #y’を確認
print(label_test) #テストデータのyを確認
count = 0
for index in range(len(pre)): #各テストデータのyとy’が同じ値なら1として
if pre[index] == label_test.values[index]: #正解数をカウントする
count = count + 1
print(count,‘/’,len(pre)) #「正解数/全テストデータ数」を確認](https://image.slidesharecdn.com/202001255-200220040302/75/2020-1-25-AITC-5-9-2048.jpg)