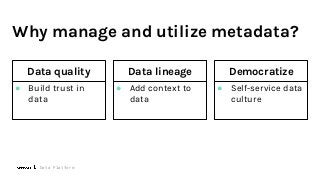
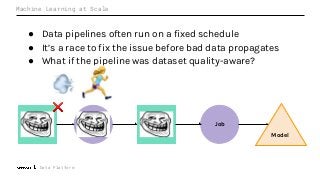
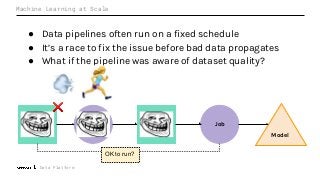
The term data quality is used to describe the correctness, reliability, and usability of datasets. Data scientists and business analysts often determine the quality of a dataset by its trustworthiness and completeness. But what information might be needed to differentiate between good vs bad data? How quickly can data quality issues be identified and explored? More importantly, how can metadata enable data scientists to make better sense of the high volume of data within their organization from a variety of data sources?
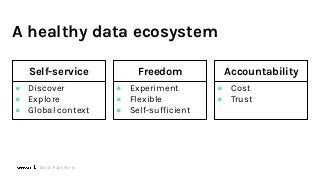
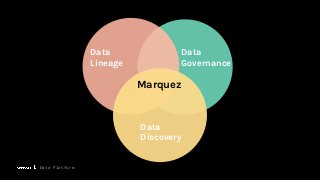
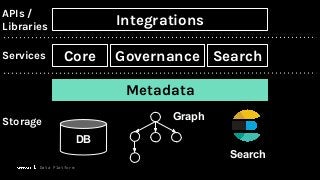
To maximize the usefulness of datasets for data-intensive applications, it is critical that metadata is collected, maintained, and shared across the organization. The investment in metadata enables: Data lineage, Data governance, and Data discovery.
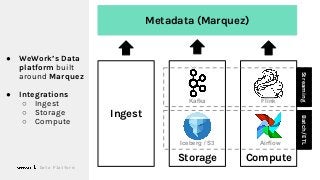
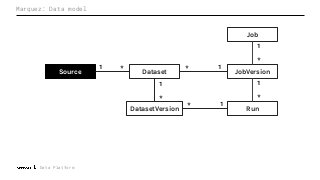
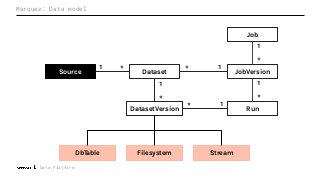
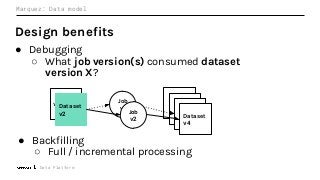
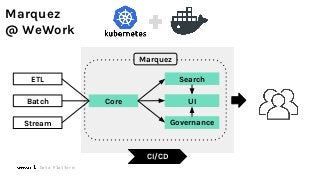
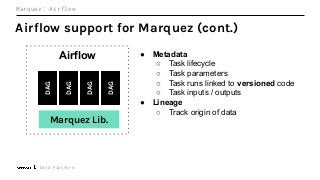
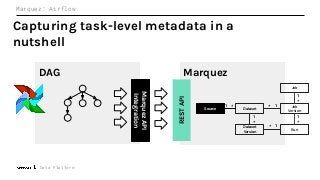
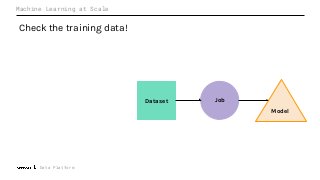
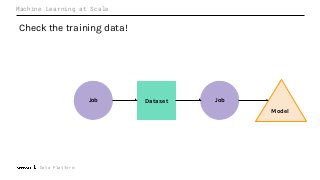
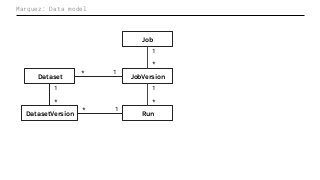
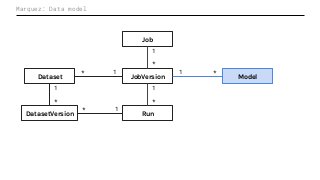
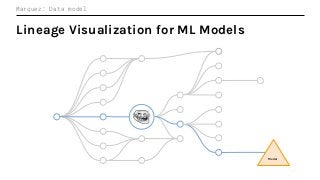
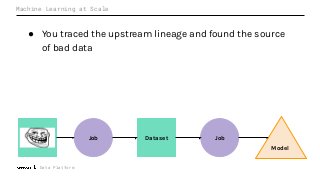
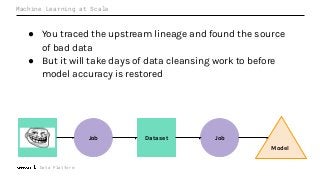
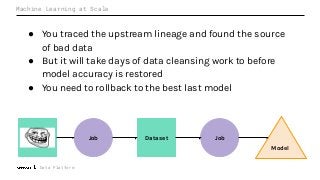
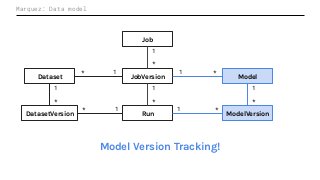
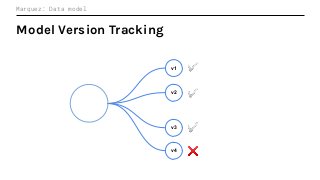
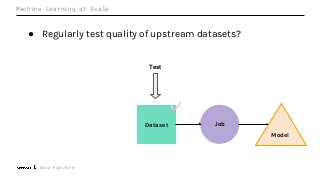
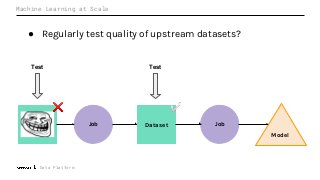
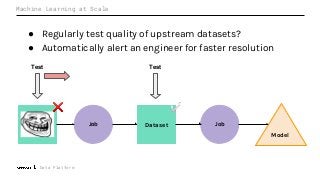
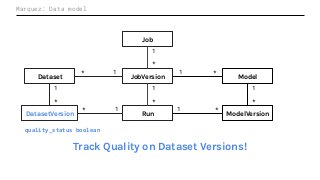
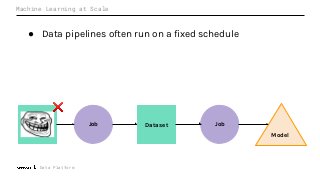
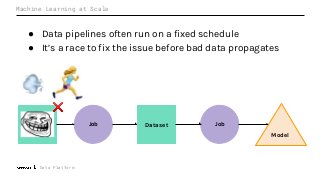
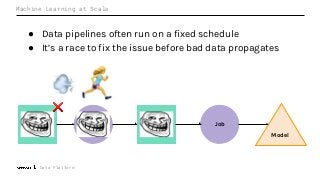
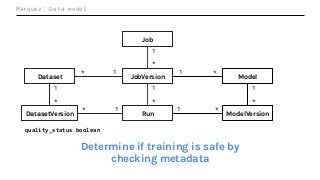
Machine Learning (ML) jobs, just another type of data-intensive application, would benefit from metadata as well. But unlike most software projects which use established tools for maintaining quality, ML projects have fewer safeguards to prevent defects. Marquez helps fill the tooling gap available for ML jobs by tracking the relationships between training jobs, input datasets, and ML models. Marquez also links the different variations of training jobs which can grow wildly due to experimentation and hyperparameter optimization. Data lineage tracking in Marquez also reveals unexpected changes in upstream data dependencies which can harm model performance and be time consuming to debug.
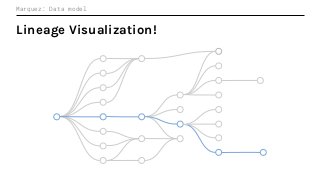
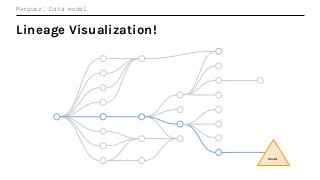
In this talk, we introduce Marquez: an open source metadata service for the collection, aggregation, and visualization of a data ecosystem’s metadata. We will demonstrate how metadata management with Marquez helps maintain high model performance and prevent quality issues.

























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

























