Downloaded 14 times


























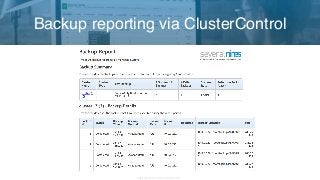

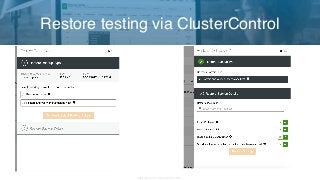





Having a solid and tested backup strategy is one of the most important aspects of database administration. If a database crashed and there was no way to recover it, any resulting data loss could have very negative impacts on a business. Whether you’re a SysAdmin, DBA or DevOps professional operating MySQL, MariaDB or Galera clusters in production, you’d want to make sure your backups are scheduled, executed and regularly tested. As with most things, there are multiple ways to take backups, but which method best fits your company’s specific needs? And how do you implement point in time recovery (amongst other things)? In this webinar, Krzysztof Książek, Senior Support Engineer at Severalnines, discusses backup strategies and best practices for MySQL, MariaDB and Galera clusters; including a live demo on how to do this with ClusterControl. AGENDA Logical and Physical Backup methods Tools - mysqldump - mydumper - xtrabackup - snapshots Best practices & example setups - On premises / private datacenter - Amazon Web Services Automating & managing backups with ClusterControl SPEAKER Krzysztof Książek, Senior Support Engineer at Severalnines, is a MySQL DBA with experience managing complex database environments for companies like Zendesk, Chegg, Pinterest and Flipboard.



































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)