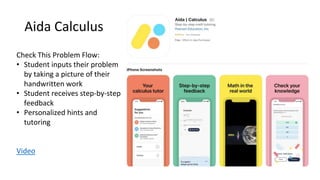
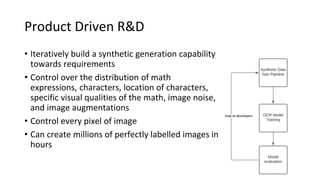
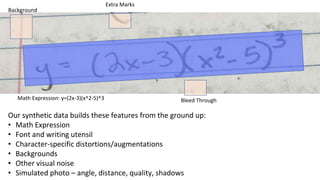
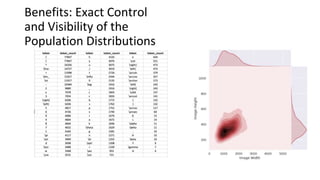
The document discusses the development of AI models for recognizing handwritten math expressions, detailing the process from problem input to feedback for students. It emphasizes the creation of high-quality synthetic datasets for training, allowing for precise control over image characteristics and efficient product development cycles. Additionally, it mentions the open-sourcing of a dataset on Kaggle, comprising 100,000 labeled images to support research and further advancements in this area.