Downloaded 16 times



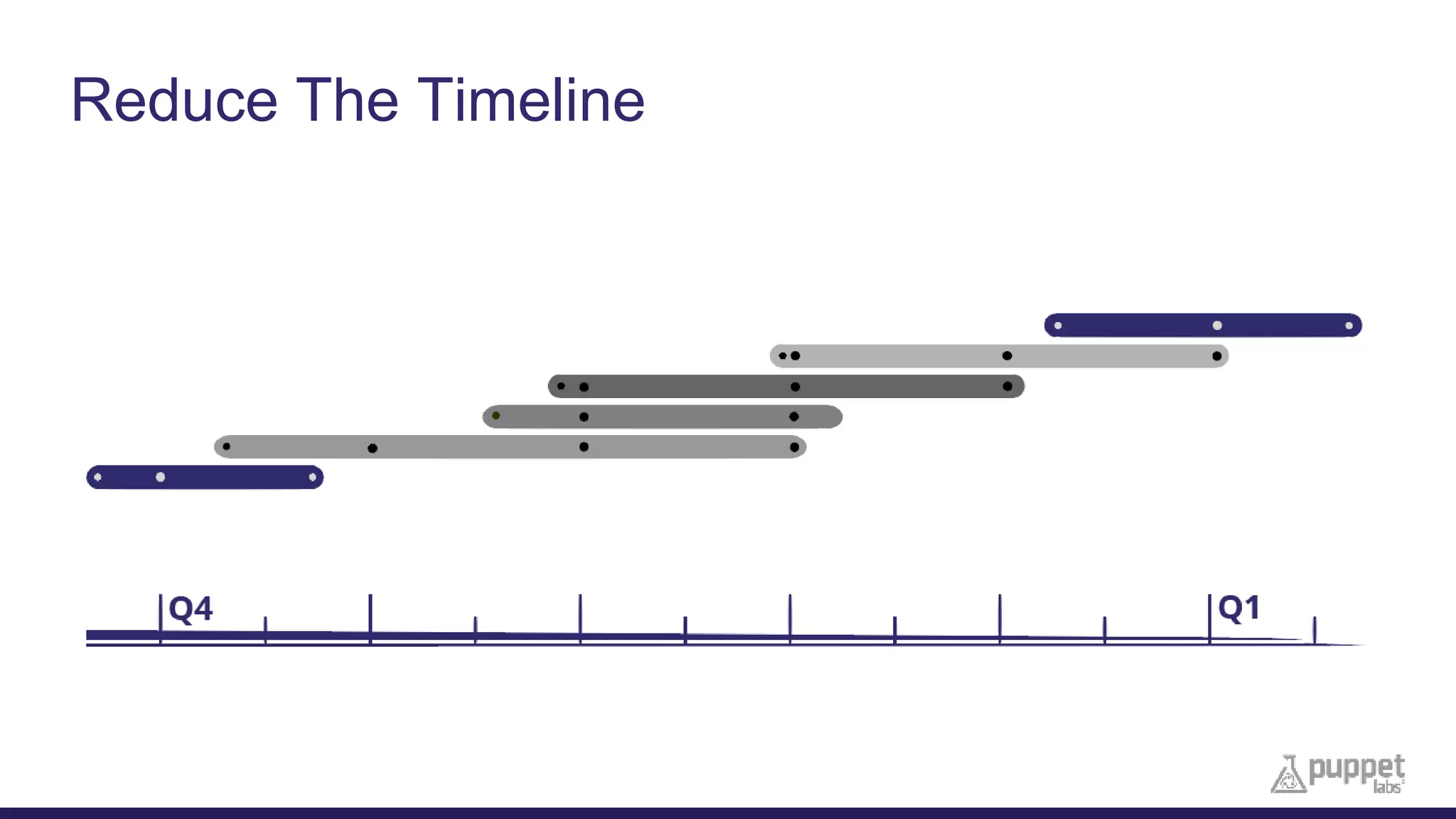









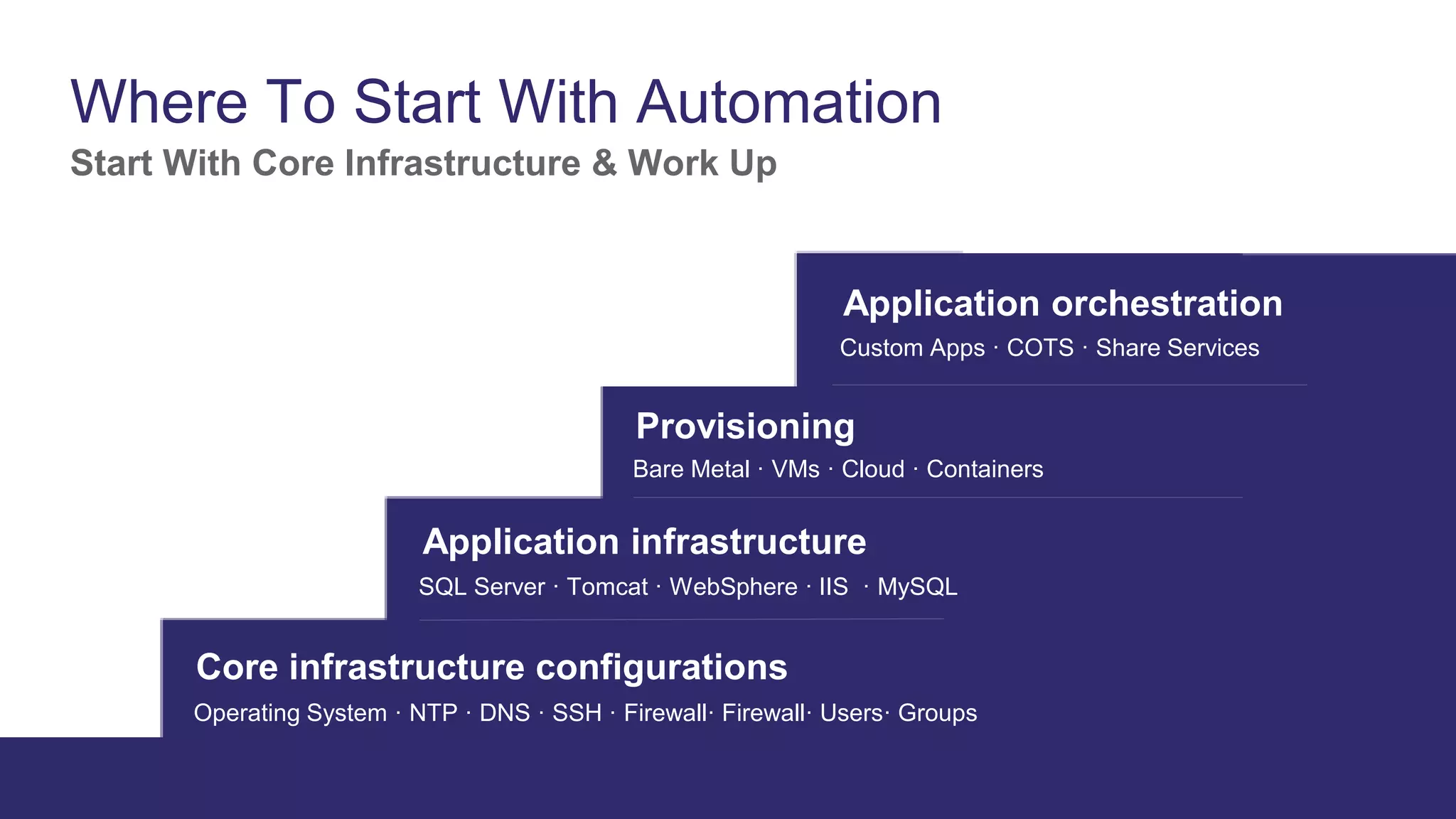
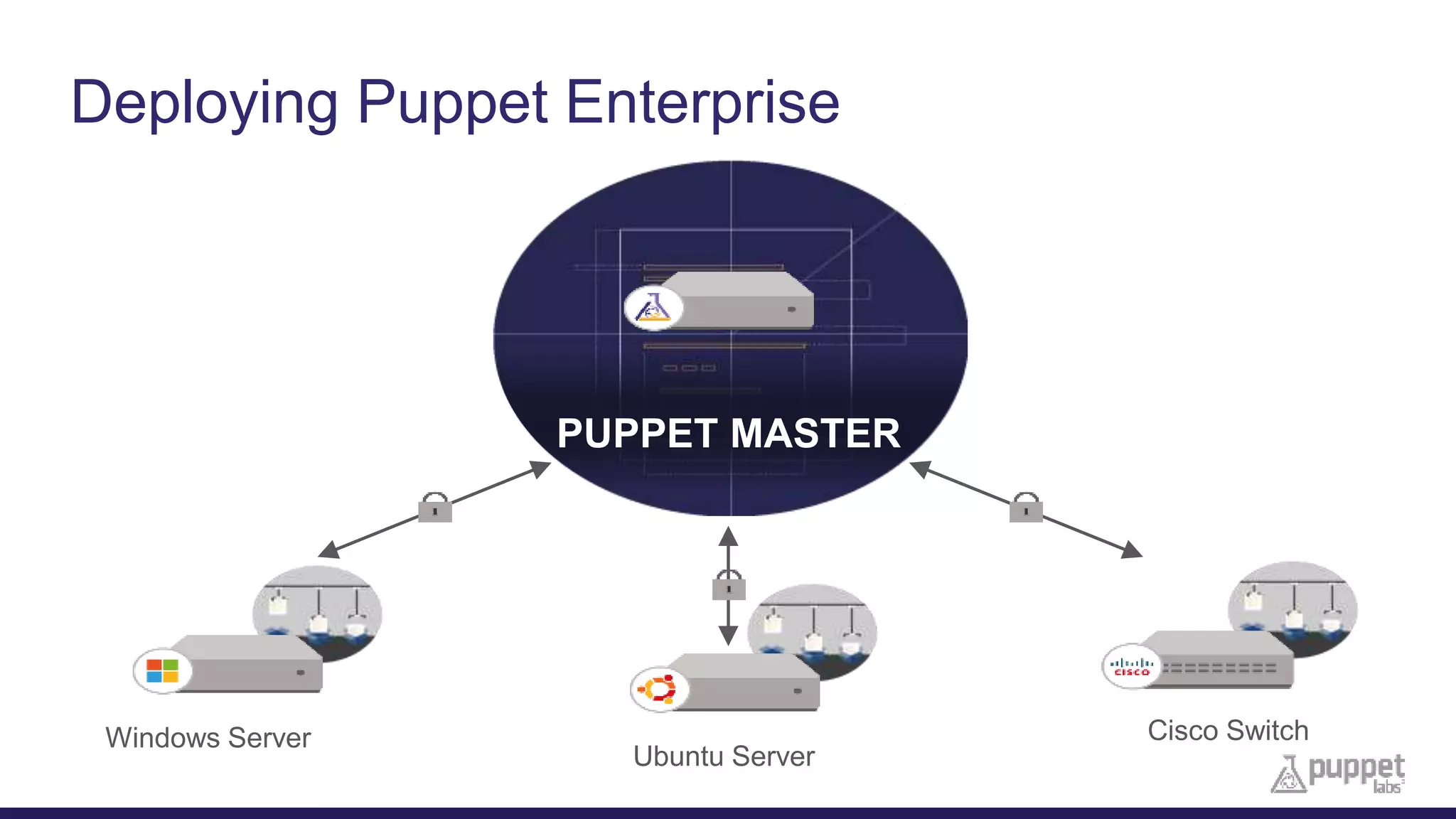



This document provides an agenda for a presentation on automating IT infrastructure with Puppet Enterprise. The presentation will include an introduction of the presenters, a discussion of why automation is needed to reduce timelines and manual processes, a demo of Puppet Enterprise, and a Q&A session. The document outlines challenges such as slow deployments and firefighting that Puppet Enterprise addresses through automating provisioning, configuration and management across infrastructure layers and the lifecycle from initial setup to decommissioning.






















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















