Download as PDF, PPTX




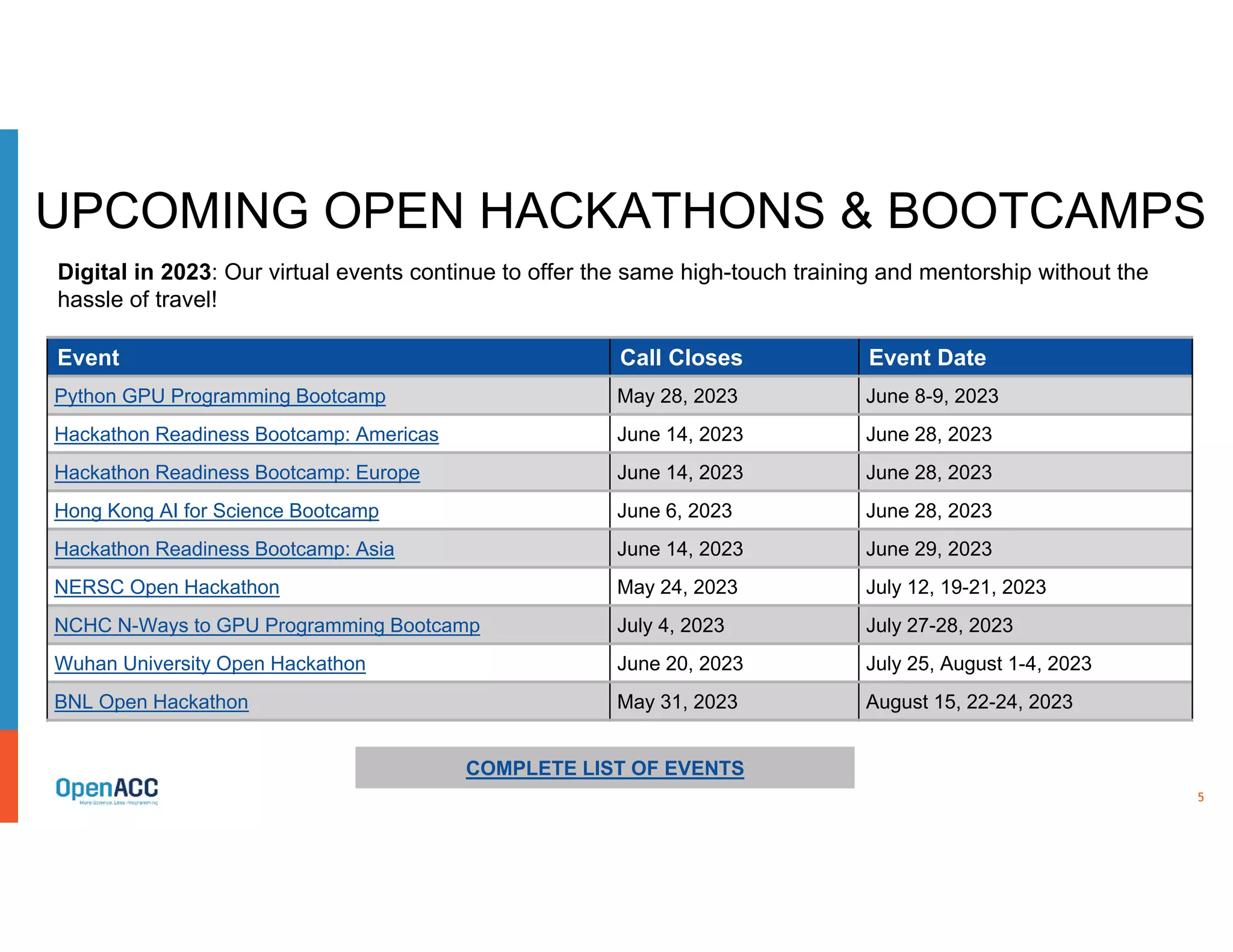








The OpenACC organization focuses on enhancing parallel computing skills within the research and developer community through training and hackathons. Recent activities include successful applications of OpenACC in over 400 scientific applications and the facilitation of various educational bootcamps and hackathons. The document also discusses ongoing collaborative efforts to optimize scientific applications and future developments in high-performance computing using OpenACC.


























































