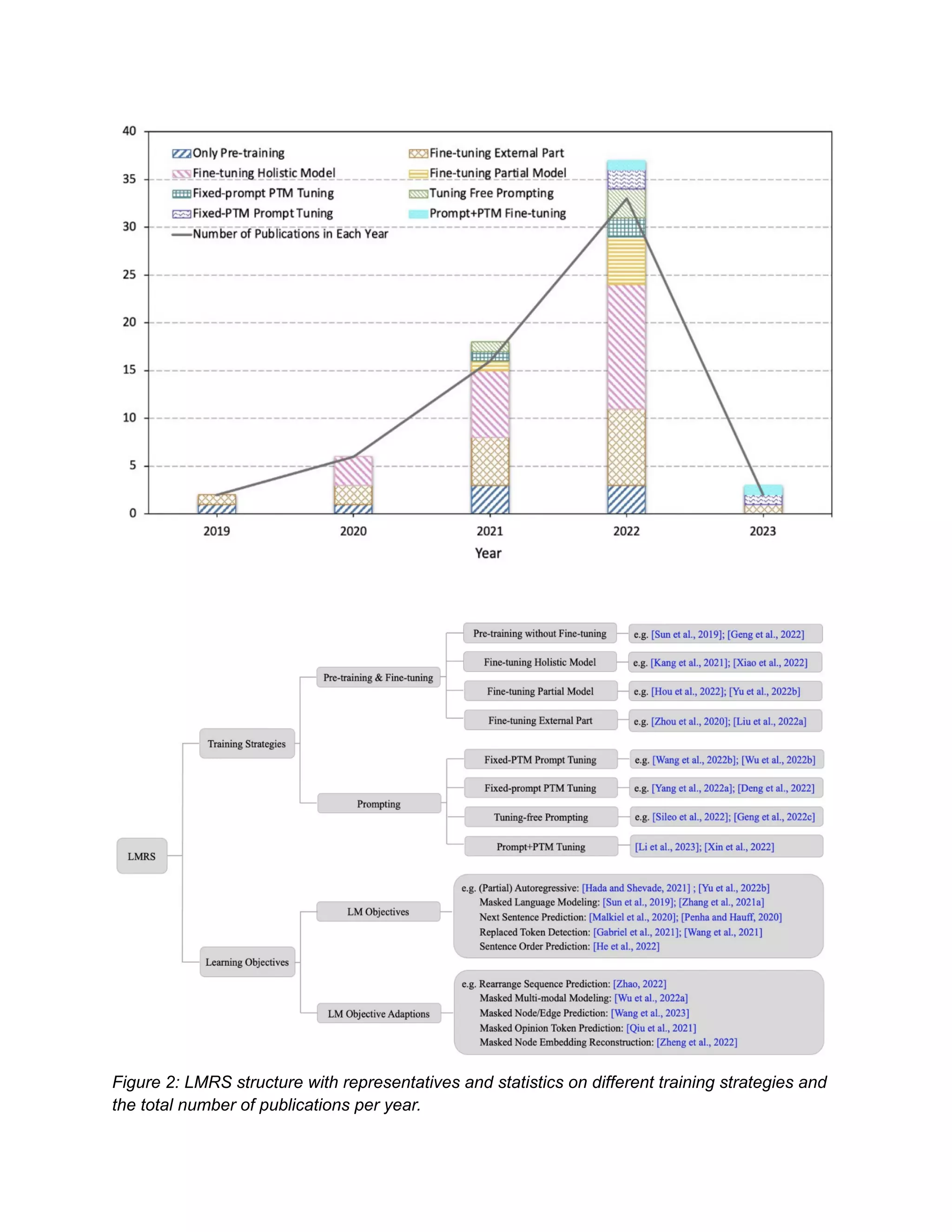
This document summarizes research on adapting pre-trained language models (PLMs) for recommender systems. It proposes a taxonomy to classify PLM-based recommender systems based on their training strategies (pre-train and fine-tune vs prompting) and input data types. The document outlines different training objectives used in language models and how they can be adapted for recommendations. It analyzes representative works that apply various training strategies and objectives to different data types for recommendation tasks. Finally, it discusses open issues and future research directions in this area.





![Masked Language Modelling (MLM) Taking a sequence of textual sentence as input, MLM first
masks a token or multi-tokens with a special token such as [MASK]. Then the model is trained
to predict the masked tokens taking the rest of the tokens as context.
Next Sentence Prediction (NSP) It is a binary classification loss for predicting whether two
segments follow each other in the original text.Another variation of the NSP is the Sentence
Order Prediction (SOP)
Replaced Token Detection(RTD) It is used to predict whether a token is replaced given its
surrounding context.](https://image.slidesharecdn.com/llmparadigmadaptationsinrecommendersystems-230522131228-79b2a745/75/LLM-Paradigm-Adaptations-in-Recommender-Systems-pdf-7-2048.jpg)
![Formulating Training with Data Types
To associate different training strategies and objectives with different types of input data, in
Table 1, we summarize representative research works in this domain and list their training
paradigms according to various training inputs for different recommendation tasks. The listed
training strategies and objectives are carefully selected and are typical in existing work. For the
page limit, we only selected part of recent research on LMRS.
Conclusion
Despite the effectiveness of LM training paradigms has been verified in various
recommendation tasks, there are still several challenges that could be the direction of future
research.
Here are some areas we could invest in the future.
● Language bias and fact-consistency in language generation tasks of recommendation
● Knowledge transmission and injection for downstream recommendations.
● Scalability of pre-training mechanism in recommendation.
● Privacy issue and ethical state.
References
[Bao et al., 2020] Hangbo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Yang, Xiaodong Liu, Yu
Wang, Jianfeng Gao, Songhao Piao, Ming Zhou, et al. Unilmv2: Pseudo- masked language
models for unified language model pretraining. In ICML, pages 642–652, 2020.
[Brown et al., 2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan,
Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al.
Language models are few-shot learners. NeurIPS, 33:1877–1901, 2020.
[Chen et al., 2021] Lei Chen, Fajie Yuan, Jiaxi Yang, Xiangnan He, Chengming Li, and Min
Yang. User-specific adaptive fine-tuning for cross-domain recommendations. TKDE, 2021.](https://image.slidesharecdn.com/llmparadigmadaptationsinrecommendersystems-230522131228-79b2a745/75/LLM-Paradigm-Adaptations-in-Recommender-Systems-pdf-8-2048.jpg)
![[Deng et al., 2022] Yang Deng, Wenxuan Zhang, Weiwen Xu, Wenqiang Lei, Tat-Seng Chua,
and Wai Lam. A unified multi-task learning framework for multi-goal conversational
recommender systems. TOIS, 2022.
[Devlin et al., 2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert:
Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT,
pages 4171–4186, 2019](https://image.slidesharecdn.com/llmparadigmadaptationsinrecommendersystems-230522131228-79b2a745/75/LLM-Paradigm-Adaptations-in-Recommender-Systems-pdf-9-2048.jpg)























![[DSC Adria 23]Tin_Ferkovic_Multi_Task_Learning_in_Transformer_Based_Architect...](https://cdn.slidesharecdn.com/ss_thumbnails/03tinferkovicmultitasklearningintransformerbasedarchitecturesfornlp-230530182120-1f3f4a5b-thumbnail.jpg?width=640&height=640&fit=bounds)









![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













