Downloaded 10 times

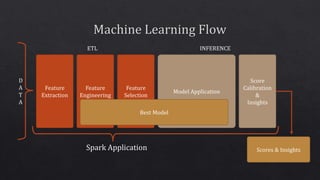
![D
A
T
A
S
E
T
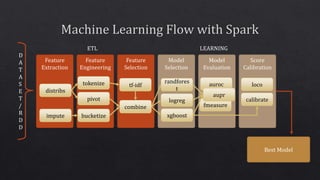
Train
tokenize
pivot
impute
tf-idf
bucketize
combine
distribs
logreg
randfores
t
xgboost
auroc
fmeasure
aupr
calibrate loco
Score
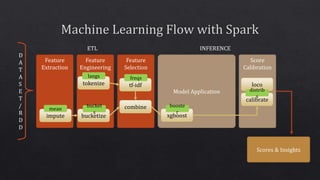
tokenize
impute
tf-idf
bucketize
combine
xgboost
calibrate loco
bucketsmean
freqs
booster
langs
distribs
Train ( Dataset[T] ) => Score ( Dataset[T] ) =>
Dataset[S]](https://image.slidesharecdn.com/makingsparkmlmodelsportable-knowyouroptions-181116054505/85/Making-Spark-ML-Models-Portable-Know-Your-Options-8-320.jpg)


















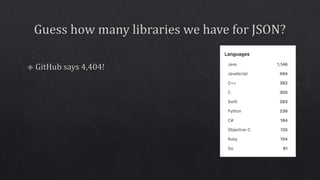
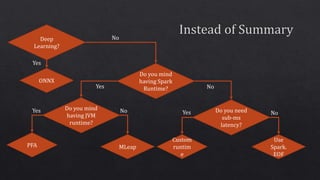





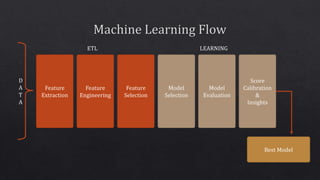
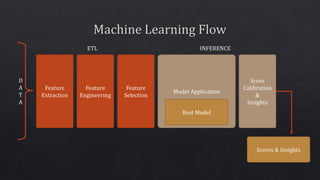
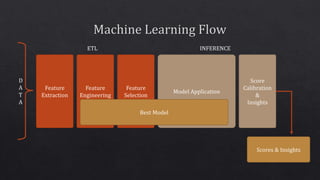
The document discusses various components of the data processing and machine learning pipeline, including feature extraction, engineering, and selection, as well as model evaluation and calibration. It mentions specific techniques like tokenization, imputation, and the use of algorithms such as logistic regression and XGBoost. Additionally, it highlights the importance of runtime environments like Spark and JVM for model implementation.