Download to read offline




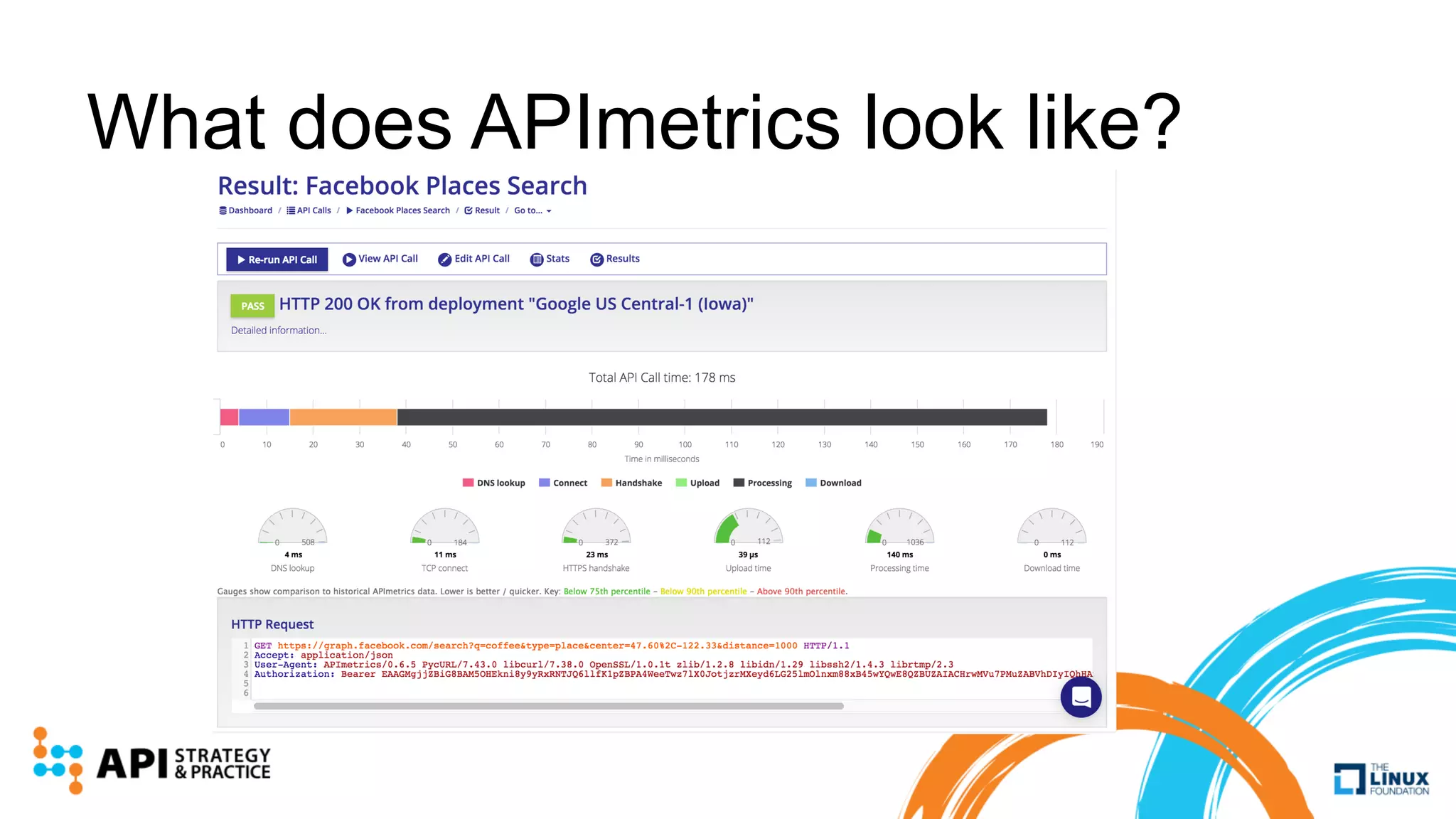







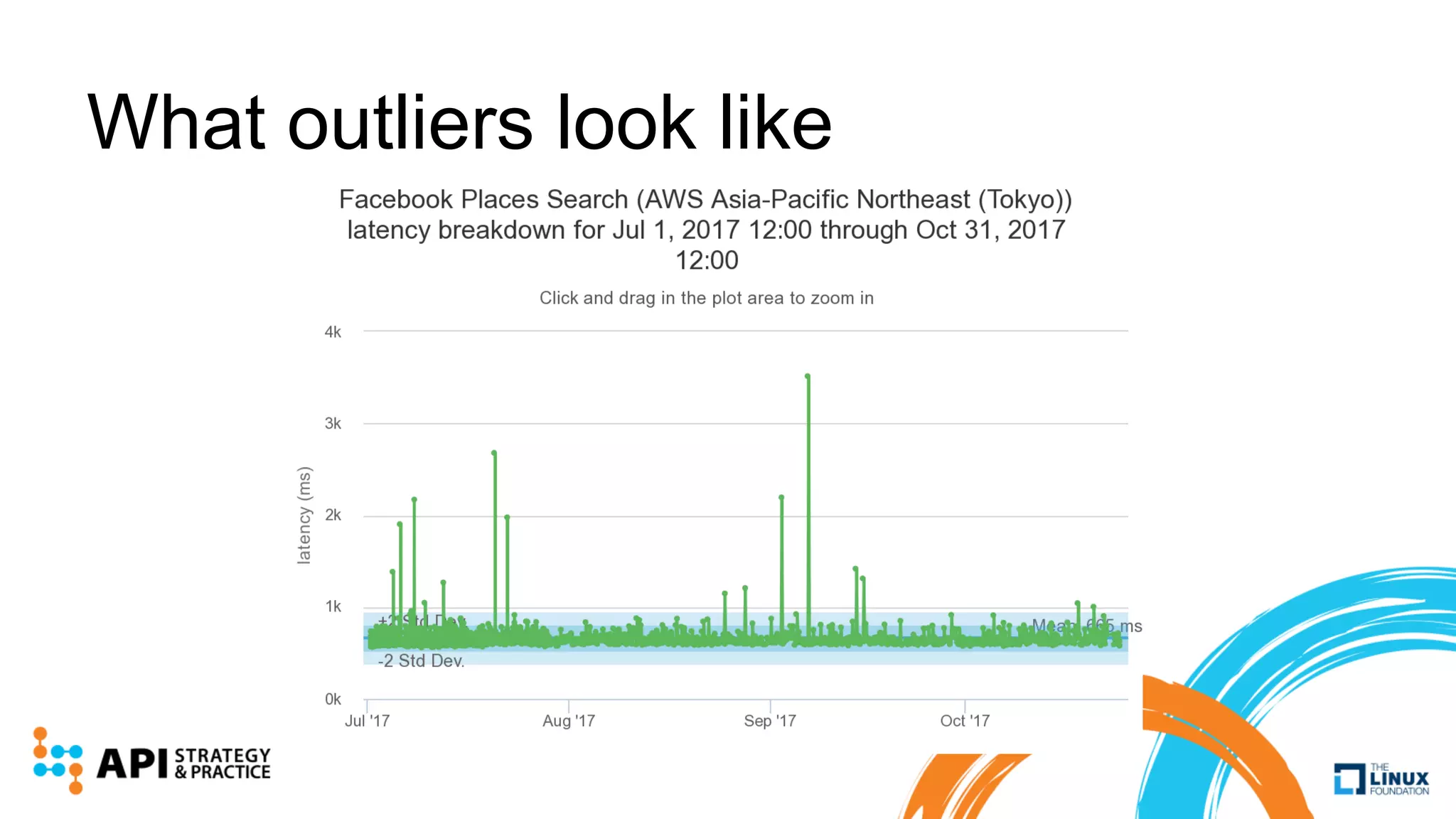

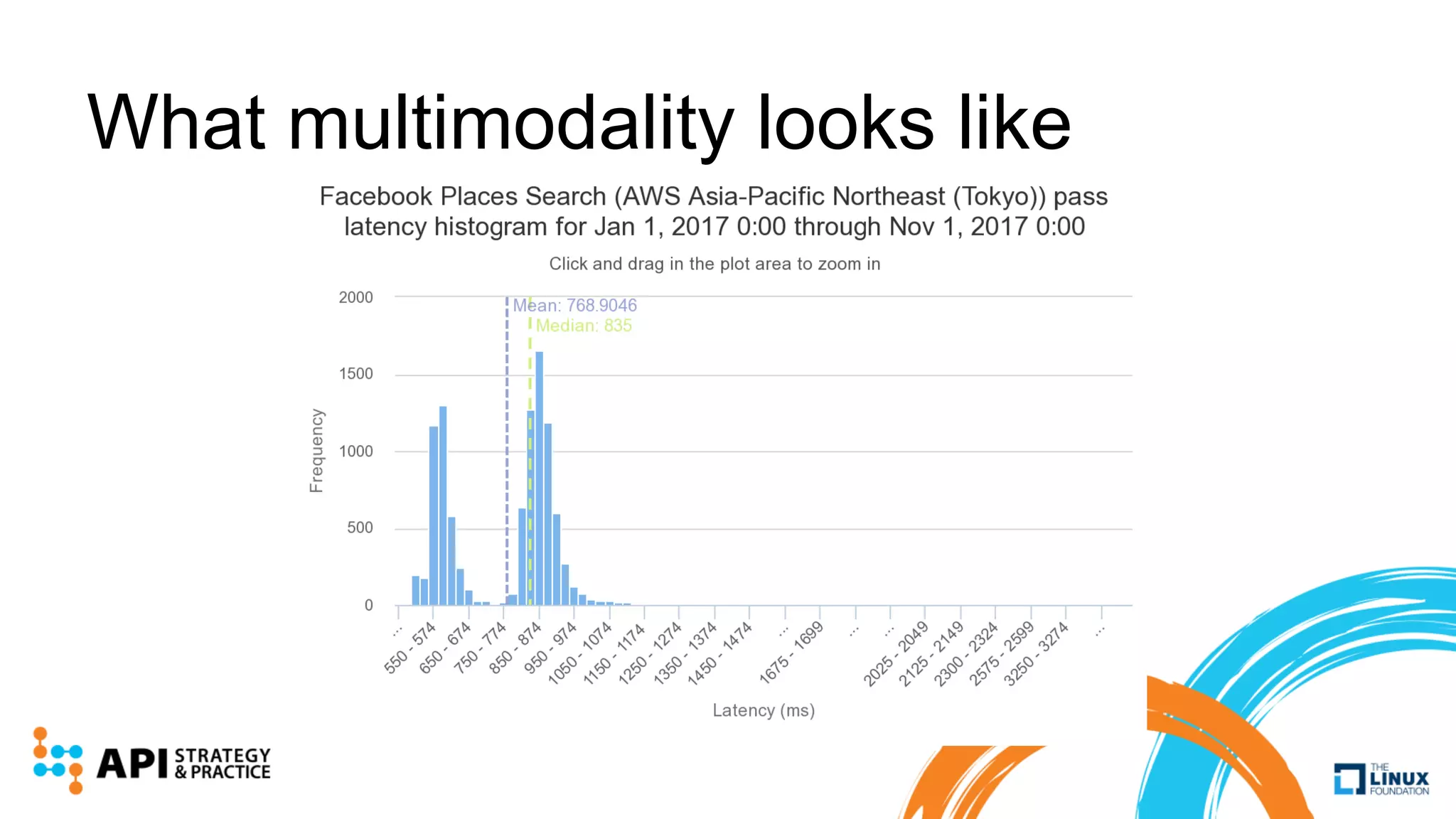

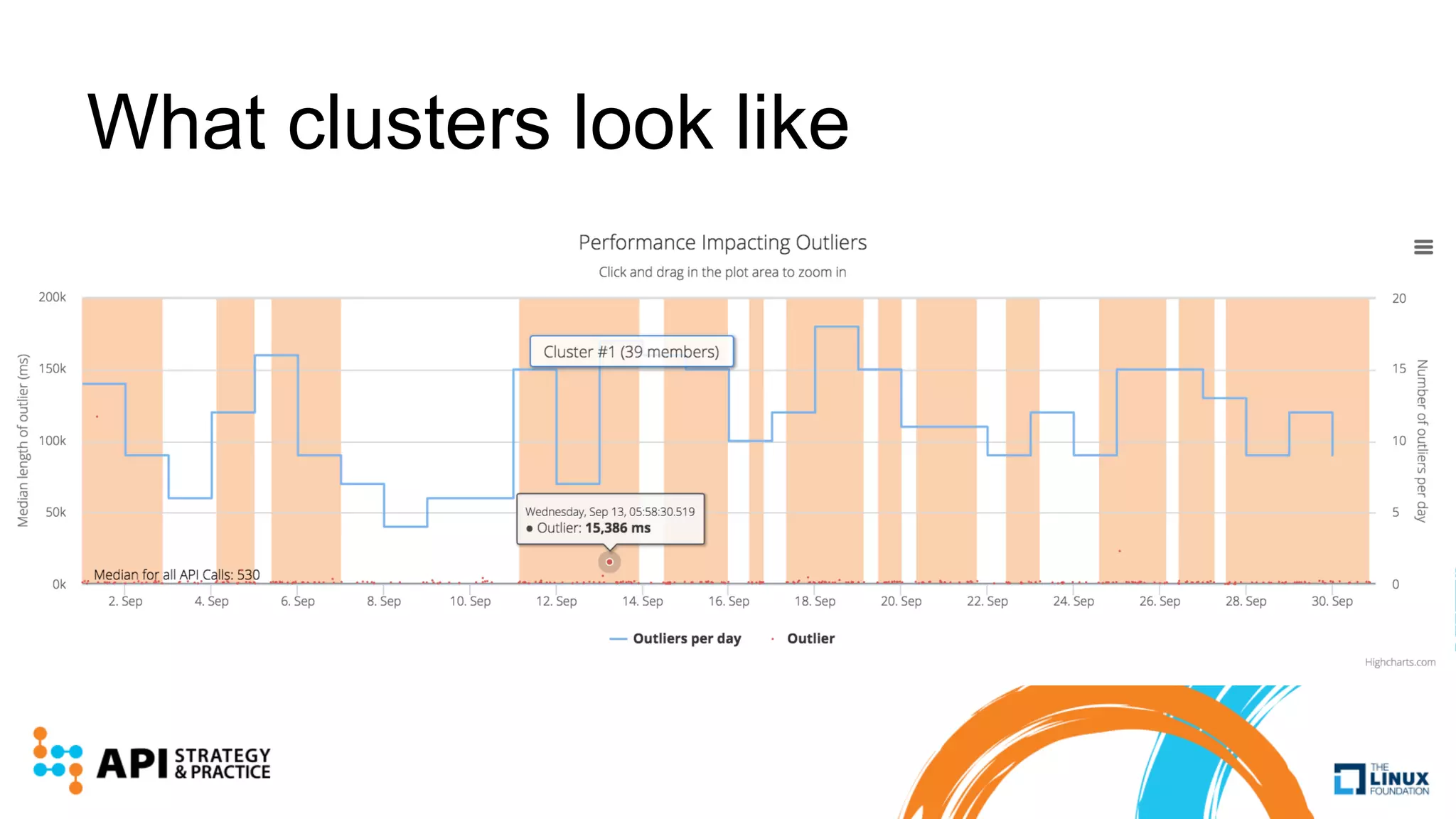



Apimetrics is a Seattle-based startup providing API performance and quality monitoring through synthetic tests and real-user feedback, operating on major cloud platforms. The system combines a vast dataset with machine learning techniques to produce CASC scores for easy comparison of API performance. Future developments include advanced outlier detection and the exploration of deep learning for enhanced analysis of API behaviors.























































































