Downloaded 124 times








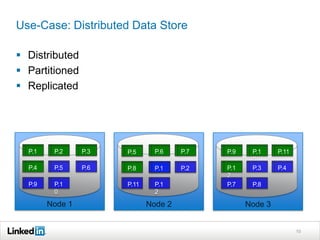
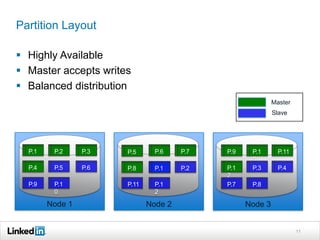
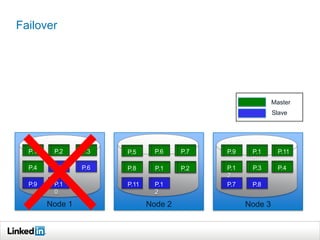
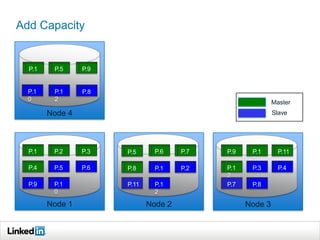


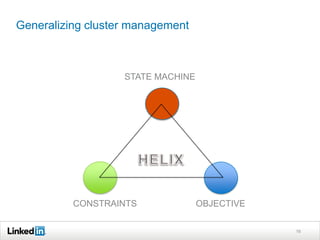

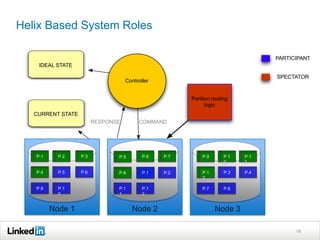
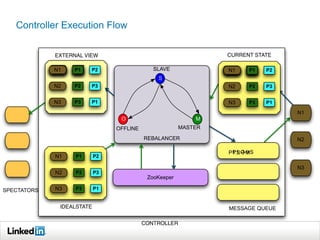
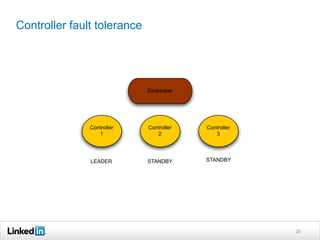
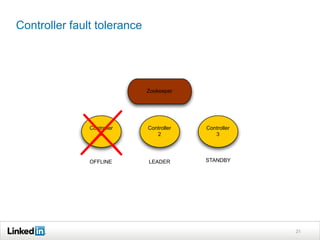
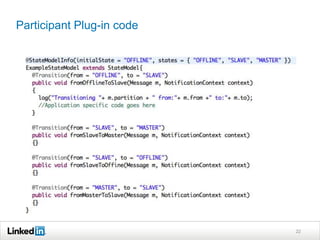



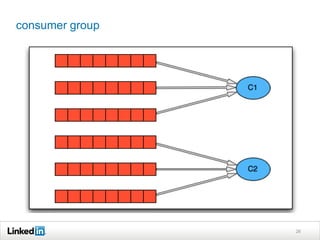
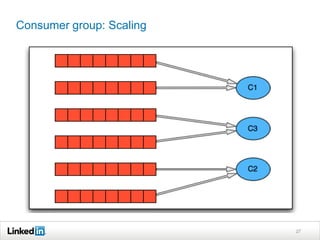
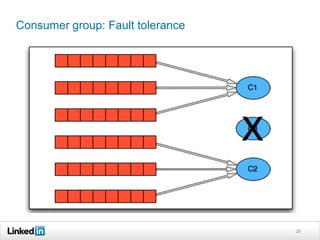
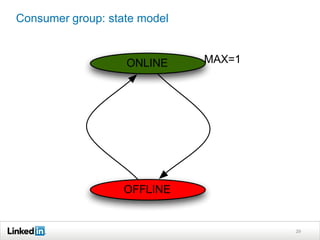






Helix is a cluster management framework from LinkedIn that allows for distributed systems to handle issues like scaling, failover, and bootstrapping through declarative state models and partitioning. It provides abstractions that make building distributed systems easier by handling common cluster management problems. Helix uses a controller to manage participants and make global cluster decisions based on ideal and current states while keeping fault tolerance. It has been used at LinkedIn for systems like distributed data stores and consumer groups.








































![Distributed Stream Processing in the real [Perl] world](https://cdn.slidesharecdn.com/ss_thumbnails/yapcasia2012streamprocessing-120928213350-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)

















