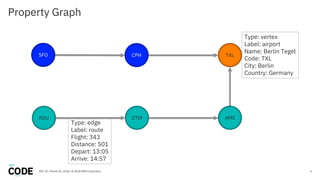
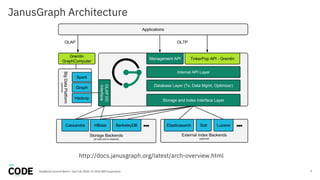
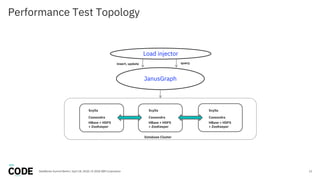
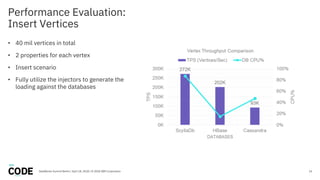
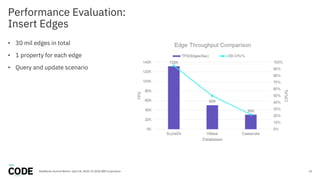
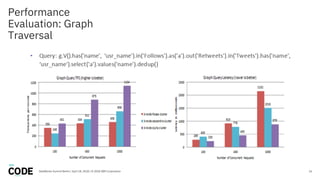
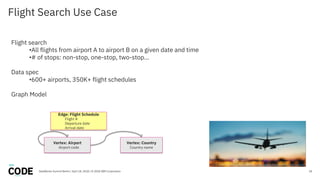
The document discusses the use of graph databases, specifically JanusGraph and Apache TinkerPop, in airline reservation systems. It covers performance evaluation, data model design, and challenges faced while managing large graph datasets. The presentation shares insights from a dataworks summit regarding the architecture, testing setups, and best practices for optimizing graph database performance.





![Gremlin: Graph Traversal
Language
7
What is the shortest path to Berlin?
DataWorks Summit Berlin / April 18, 2018 / © 2018 IBM Corporation
Apache TinkerPop
https://tinkerpop.apache.org
> g.V(rdu).
repeat( out('route').simplePath() ).
until( has('code’, TXL') ).
limit(5).
path().by('code').
toList()
==> [RDU, JFK, TXL]
==> [RDU, LAX, TXL]
==> [RDU, MIA, TXL]
==> [RDU, YYZ, TXL]
==> [RDU, SFO, TXL]](https://image.slidesharecdn.com/airline-180418135633/85/Airline-Reservations-and-Routing-A-Graph-Use-Case-7-320.jpg)




























































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)













![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
