Downloaded 19 times

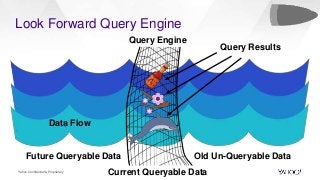
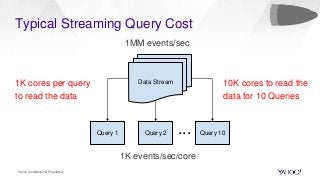
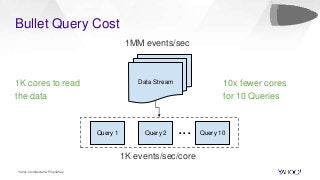





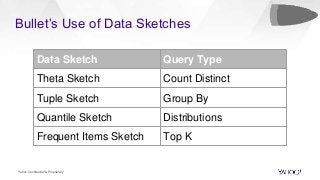
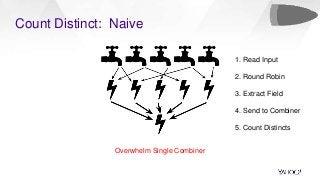
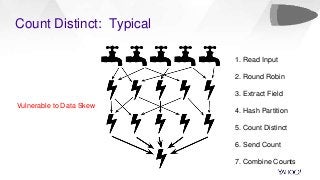
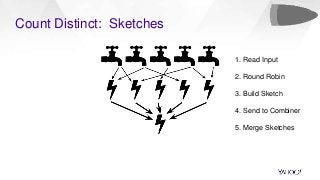

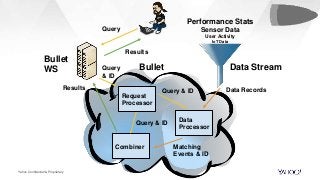
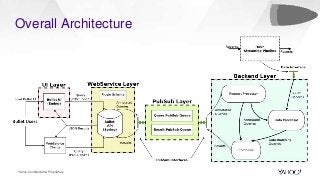
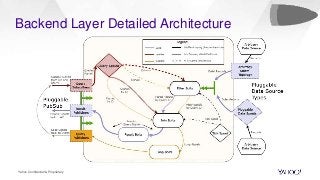




In this talk, we will present how we dealt with the challenges of implementing intractable aggregations such as counting distincts, finding top K items, or getting percentiles of an unknown distribution (such as the 99th percentile) and more on arbitrary streaming data. Handling this challenge while also implementing various windowing mechanisms (tumbling, hopping, sliding etc) for obtaining the results of these aggregations is a pretty hefty task. Throwing this challenge onto a system that operates with no persistence layer on arbitrary, very high volume data streams in today’s IoT world seems like an impossible problem. We will address how we solved all this using DataSketches in a simple and elegant manner in our streaming query engine called Bullet. We will compare our different approaches, show why we settled on using DataSketches, and what the tradeoffs were. Bullet is an open-sourced, lightweight, scalable, multi-tenant query system that lets you query any data flowing through a streaming system without having to store it. Bullet can run arbitrary queries against an unbounded set of data that arrives after the query is submitted. (Bullet queries look forward in time.) These queries can filter, project, and aggregate data in transit. Bullet is also platform- and framework-agnostic. Almost all the layers in Bullet can be mixed and matched with different implementations using our core abstractions such as Storm, Spark, etc. for the backend layer, Kafka or another messaging queue for the PubSub layer and so on. We will explain our motivation for creating Bullet, the new architecture of Bullet, and how DataSketches fits into it. Finally, we will also do a demo of our latest changes to Bullet on a real, high-volume dataset at use in production. Bullet documentation: https://yahoo.github.io/bullet-docs DataSketches documentation: https://datasketches.github.io Speakers Akshai Sarma, Yahoo, Principal Software Engineer Michael Natkovish, Yahoo, Director Engineering














































