Downloaded 60 times











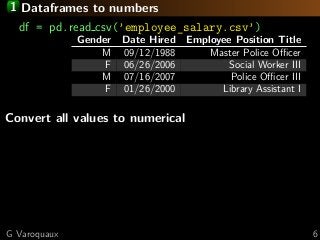
![1 Dataframes to numbers
df = pd.read csv(’employee_salary.csv’)
Gender Date Hired Employee Position Title
M 09/12/1988 Master Police Officer
F 06/26/2006 Social Worker III
M 07/16/2007 Police Officer III
F 01/26/2000 Library Assistant I
Convert all values to numerical
Gender: One-hot encode
one hot enc = sklearn. preprocessing .OneHotEncoder()
one hot enc. fit transform (df[[’Gender’]])
Gender (M) Gender (F) ...
1 0
0 1
1 0
0 1G Varoquaux 6](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-13-320.jpg?cb=1562841952)
![1 Dataframes to numbers
df = pd.read csv(’employee_salary.csv’)
Gender Date Hired Employee Position Title
M 09/12/1988 Master Police Officer
F 06/26/2006 Social Worker III
M 07/16/2007 Police Officer III
F 01/26/2000 Library Assistant I
Convert all values to numerical
Gender: One-hot encode
Date: use pandas’ datetime support
d a t e s = pd. t o d a t e t i m e ( df [’Date First Hired ’])
# the values hold the data in secs
d a t e s . v a l u e s . a s t y p e (float)
G Varoquaux 6](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-14-320.jpg?cb=1562841952)
![1 Transformers: fit & transform
Separating fitting from transforming
Avoids data leakage
Can be used in a Pipeline and cross val score
One-hot encoder
one hot enc. fit (df[[’Gender’]])
X = one hot enc.transform(df[[’Gender’]])
1) store which categories are present
2) encode the data accordingly
Better than pd.get dummies because columns are defined
from train set, and do not change with test set
G Varoquaux 7](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-15-320.jpg?cb=1562841952)
![1 Transformers: fit & transform
Separating fitting from transforming
Avoids data leakage
Can be used in a Pipeline and cross val score
For dates: FunctionTransformer
def date2num ( d a t e s t r ):
out = pd. t o d a t e t i m e ( d a t e s t r ). v a l u e s .
a s t y p e (np.float)
return out . r e s h a p e ((-1, 1)) # 2D output
d a t e t r a n s = p r e p r o c e s s i n g . F u n c t i o n T r a n s f o r m e r (
func =date2num , v a l i d a t e = F a l s e )
X = d a t e t r a n s . t r a n s f o r m ( df [’Date First Hired ’]
G Varoquaux 7](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-16-320.jpg?cb=1562841952)
![1 ColumnTransformer: assembling
Applies different transformers to columns
These can be complex pipelines
c o l u m n t r a n s = compose . m a k e c o l u m n t r a n s f o r m e r (
( one hot enc , [’Gender ’, ’Employee
Position Title ’]),
( d a t e t r a n s , ’Date First Hired ’),
)
X = c o l u m n t r a n s . f i t t r a n s f o r m ( df )
From DataFrame to array with heteroge-
neous preprocessing & feature engineering
G Varoquaux 8](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-17-320.jpg?cb=1562841952)
![1 ColumnTransformer: assembling
Applies different transformers to columns
These can be complex pipelines
c o l u m n t r a n s = compose . m a k e c o l u m n t r a n s f o r m e r (
( one hot enc , [’Gender ’, ’Employee
Position Title ’]),
( d a t e t r a n s , ’Date First Hired ’),
)
X = c o l u m n t r a n s . f i t t r a n s f o r m ( df )
From DataFrame to array with heteroge-
neous preprocessing & feature engineering
Benefit: model selection on dataframe
model = make pipeline(column trans,
HistGradientBoostingClassifier)
scores = cross val score(model, df, y)
G Varoquaux 8](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-18-320.jpg?cb=1562841952)
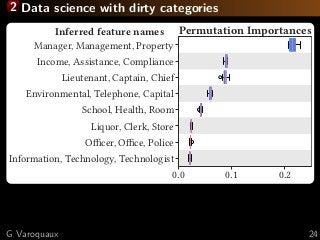
![2 Encoding dirty categories
PhD word of Patricio Cerda [Cerda... 2018]
Employee Position Title
Master Police Officer
Social Worker IV
Police Officer III
Police Aide
Electrician I
Bus Operator
Bus Operator
Social Worker III
Library Assistant I
Library Assistant I](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-19-320.jpg?cb=1562841952)



![2 Adding similarities to one-hot encoding
One-hot encoding
London Londres Paris
Londres 0 1 0
London 1 0 0
Paris 0 0 1
X ∈ Rn×p
new categories?
link categories?
Similarity encoding [Cerda... 2018]
London Londres Paris
Londres 0.3 1.0 0.0
London 1.0 0.3 0.0
Paris 0.0 0.0 1.0
string distance(Londres, London)
G Varoquaux 13](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-25-320.jpg?cb=1562841952)

![2 Other approach: TargetEncoder [Micci-Barreca 2001]
Represent each category by the average target y
For example Police Officer III
→ average salary of policy officer III
40000 60000 80000 100000 120000 140000
y: Employee salary
Crossing Guard
Liquor Store Clerk I
Library Aide
Police Cadet
Public Safety Reporting Aide I
Administrative Specialist II
Management and Budget Specialist III
Manager III
Manager I
Manager II
G Varoquaux 16](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-28-320.jpg?cb=1562841952)
![2 Other approach: TargetEncoder [Micci-Barreca 2001]
Represent each category by the average target y
For example Police Officer III
→ average salary of policy officer III
40000 60000 80000 100000 120000 140000
y: Employee salary
Crossing Guard
Liquor Store Clerk I
Library Aide
Police Cadet
Public Safety Reporting Aide I
Administrative Specialist II
Management and Budget Specialist III
Manager III
Manager I
Manager IIEmbedding closeby categories with the same
y can help building a simple decision function.
G Varoquaux 16](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-29-320.jpg?cb=1562841952)
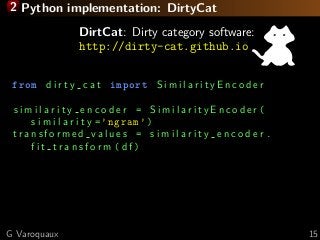
![2 Other approach: TargetEncoder [Micci-Barreca 2001]
Represent each category by the average target y
For example Police Officer III
→ average salary of policy officer III
DirtCat: Dirty category software:
http://dirty-cat.github.io
from d i r t y c a t import TargetEncoder
t a r g e t e n c o d e r = TargetEncoder ()
t r a n s f o r m e d v a l u e s = t a r g e t e n c o d e r .
f i t t r a n s f o r m ( df )
G Varoquaux 16](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-30-320.jpg?cb=1562841952)
![2 Experimental results: prediction performance
Average rank on 7 datasets
Linear model Gradient-boosted trees
One-hot encoding 4.7 6.0
Target encoding 5.3 4.3
Similarity encoding
Jaro-Winkler 3.4 3.6
Levenshtein 3.1 3.0
3-gram 1.1 1.9
Best: similarity encoding with 3-gram similarity
[Cerda... 2018]
Also, gradient-boosted
trees work much better
G Varoquaux 17](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-31-320.jpg?cb=1562841952)
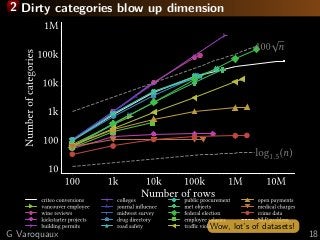
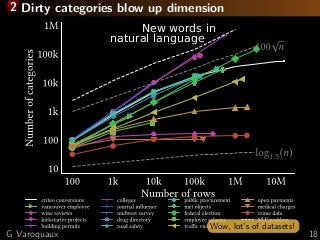
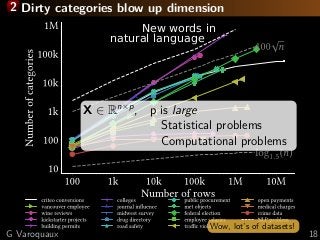


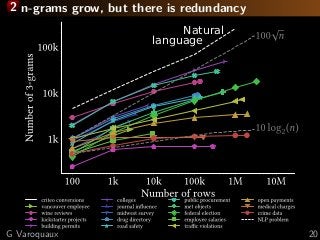
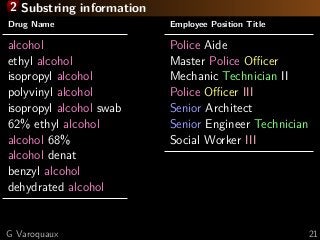
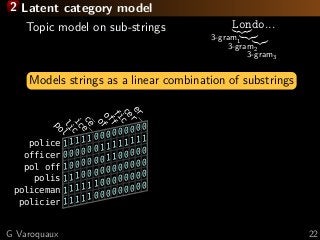
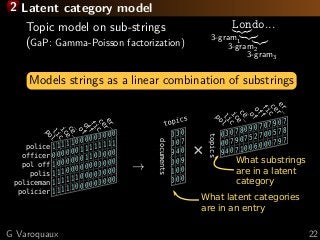


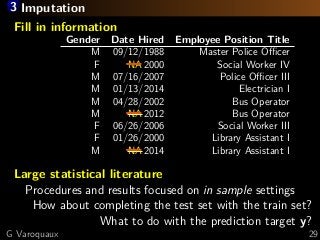
![3 Learning with missing values
[Josse... 2019]
Gender Date Hired Employee Position Title
M 09/12/1988 Master Police Officer
F NA Social Worker IV
M 07/16/2007 Police Officer III
F 02/05/2007 Police Aide
M 01/13/2014 Electrician I
M 04/28/2002 Bus Operator
M NA Bus Operator
F 06/26/2006 Social Worker III
F 01/26/2000 Library Assistant I
M NA Library Assistant I
G Varoquaux 25](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-44-320.jpg?cb=1562841952)


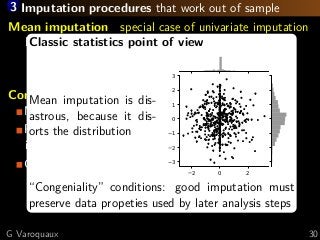
![3 Classic statistics points of view
Model a) a complete data-generating process
Model b) a random process occluding entries
Missing at random situation (MAR)
for non-observed values, the probability of missingness
does not depend on this non-observed value.
Proper definition in [Josse... 2019]
Theorem [Rubin 1976], in MAR, maximizing likelihood for
observed data while ignoring (marginalizing) the unob-
served values gives maximum likelihood of model a).
G Varoquaux 27](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-47-320.jpg?cb=1562841952)
![3 Classic statistics points of view
Model a) a complete data-generating process
Model b) a random process occluding entries
Missing at random situation (MAR)
for non-observed values, the probability of missingness
does not depend on this non-observed value.
Proper definition in [Josse... 2019]
Theorem [Rubin 1976], in MAR, maximizing likelihood for
observed data while ignoring (marginalizing) the unob-
served values gives maximum likelihood of model a).
Missing Completely at random situation (MCAR)
Missingnes is independent from data
Missing Not at Random situation (MNAR)
Missingnes not ignorable
G Varoquaux 27](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-48-320.jpg?cb=1562841952)
![3 Classic statistics points of view
Model a) a complete data-generating process
Model b) a random process occluding entries
Missing at random situation (MAR)
for non-observed values, the probability of missingness
does not depend on this non-observed value.
Proper definition in [Josse... 2019]
Theorem [Rubin 1976], in MAR, maximizing likelihood for
observed data while ignoring (marginalizing) the unob-
served values gives maximum likelihood of model a).
Missing Completely at random situation (MCAR)
Missingnes is independent from data
Missing Not at Random situation (MNAR)
Missingnes not ignorable
2 0 2
2
0
2
Complete
2 0 2
2
0
2
MCAR
2 0
3
2
1
0
MNAR
G Varoquaux 27](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-49-320.jpg?cb=1562841952)
![3 Classic statistics points of view
Model a) a complete data-generating process
Model b) a random process occluding entries
Missing at random situation (MAR)
for non-observed values, the probability of missingness
does not depend on this non-observed value.
Proper definition in [Josse... 2019]
Theorem [Rubin 1976], in MAR, maximizing likelihood for
observed data while ignoring (marginalizing) the unob-
served values gives maximum likelihood of model a).
Missing Completely at random situation (MCAR)
Missingnes is independent from data
Missing Not at Random situation (MNAR)
Missingnes not ignorable
2 0 2
2
0
2
Complete
2 0 2
2
0
2
MCAR
2 0
3
2
1
0
MNAR
But
There isn’t always an unobserved value
Age of spouse of singles?
We are not trying to maximize likelihoods
G Varoquaux 27](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-50-320.jpg?cb=1562841952)



![3 Imputation for supervised learning
Theorem [Josse... 2019]
For a powerful learner (universally consistent)
imputing both train and test with the mean of
train is consistent
ie it converges to the best possible prediction
Intuition
The learner “recognizes” imputed entries and
compensates at test time
G Varoquaux 31](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-56-320.jpg?cb=1562841952)
![3 Imputation for supervised learning
Theorem [Josse... 2019]
For a powerful learner (universally consistent)
imputing both train and test with the mean of
train is consistent
ie it converges to the best possible prediction
Intuition
The learner “recognizes” imputed entries and
compensates at test time
Simulation: MCAR + Gradient boosting
102 103 104
Sample size
0.65
0.70
0.75
0.80
r2score
Mean
Iterative
Convergence
0.725 0.750 0.775
r2 score
Iterative
Mean
Small small size
Notebook: github – @nprost / supervised missing
Conclusions:
IterativeImputer is useful for small sample sizes
G Varoquaux 31](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-57-320.jpg?cb=1562841952)
![3 Imputation is not enough
Pathological case [Josse... 2019]
y depends only on wether data is missing or not
eg tax fraud detection
theory: MNAR = “Missing Not At Random”
Imputing makes prediction impossible
Solution
Add a missingness indicator: extra feature to predict
...SimpleImpute(add indicator=True)
...IterativeImputer(add indicator=True)
G Varoquaux 32](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-58-320.jpg?cb=1562841952)
![3 Imputation is not enough
Pathological case [Josse... 2019]
y depends only on wether data is missing or not
eg tax fraud detection
theory: MNAR = “Missing Not At Random”
Imputing makes prediction impossible
Solution
Add a missingness indicator: extra feature to predict
...SimpleImpute(add indicator=True)
...IterativeImputer(add indicator=True)
Simulation: y depends indirectly on missingness
censoring in the data
102 103 104
Sample size
0.75
0.80
0.85
0.90
0.95
r2score
Mean
Mean+
indicator
Iterative
Iterative+
indicator
Convergence
0.8 0.9
r2 score
Iterative+
indicator
Iterative
Mean+
indicator
Mean
Small small size
Notebook: github – @nprost / supervised missing
Adding a mask is crucial
Iterative imputation can be detrimental
G Varoquaux 32](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-59-320.jpg?cb=1562841952)


![@GaelVaroquaux
Learning on dirty data
Prepare data via ColumnTransformer
Use HistGradientBoosting
Dirty categories
Give us your dirty data
Similarity encoding
Dirty category software:
http://dirty-cat.github.io
Supervised learning with missing data
Mean imputation + missing indicator
Much more results in [Josse... 2019]
http://project.inria.fr/dirtydata
On going research](https://image.slidesharecdn.com/slides-190711103449/85/Machine-learning-on-non-curated-data-62-320.jpg?cb=1562841952)



Industry surveys [1] reveal that the number one hassle of data scientists is cleaning the data to analyze it. Textbook statistical modeling is sufficient for noisy signals, but errors of a discrete nature break standard tools of machine learning. I will discuss how to easily run machine learning on data tables with two common dirty-data problems: missing values and non-normalized entries. On both problems, I will show how to run standard machine-learning tools such as scikit-learn in the presence of such errors. The talk will be didactic and will discuss simple software solutions. It will build on the latest improvements to scikit-learn for preprocessing and missing values and the DirtyCat package [2] for non normalized entries. I will also summarize theoretical analyses in recent machine learning publications. This talk targets data practitioners. Its goal are to help data scientists to be more efficient analysing data with such errors and understanding their impacts. With missing values, I will use simple arguments and examples to outline how to obtain asymptotically good predictions [3]. Two components are key: imputation and adding an indicator of missingness. I will explain theoretical guidelines for these, and I will show how to implement these ideas in practice, with scikit-learn as a learner, or as a preprocesser. For non-normalized categories, I will show that using their string representations to “vectorize” them, creating vectorial representations gives a simple but powerful solution that can be plugged in standard statistical analysis tools [4]. [1] Kaggle, the state of ML and data science 2017 https://www.kaggle.com/surveys/2017 [2] https://dirty-cat.github.io/stable/ [3] Josse Julie, Prost Nicolas, Scornet Erwan, and Varoquaux Gaël (2019). “On the consistency of supervised learning with missing values”. https://arxiv.org/abs/1902.06931 [4] Cerda Patricio, Varoquaux Gaël, and Kégl Balázs. "Similarity encoding for learning with dirty categorical variables." Machine Learning 107.8-10 (2018): 1477 https://arxiv.org/abs/1806.00979