Downloaded 12 times














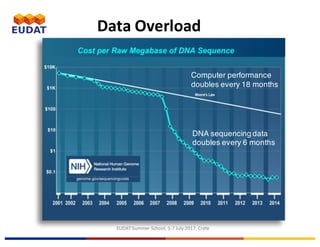
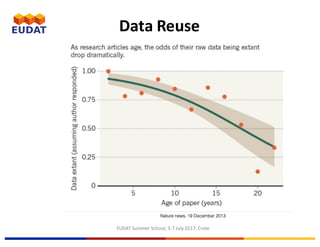




















![EUDAT Summer School, 3-7 July 2017, Crete
EUROPEAN COMMISSION
DIRECTORATE-GENERAL FOR RESEARCH & INNOVATION
Directorate A Policy Development and Coordination
A.6 Data, Open Access and Foresight
SESSION 1: DATA CULTURE, DATA STEWARDSHIP,
PRACTICAL AND POLICY TOOLS
INPUT PAPER
European Open Science Cloud (EOSC) Summit
12 June 2017 | Charlemagne Building | Brussels
RECOGNISING the challenges of data driven research in pursuing excellent science;
GRANTING that the vision of European Open Science Cloud is of a research data commons,
widely inclusive of all disciplines and Member States, sustainable in the long-term, the EC;
PROPOSES that the stakeholders present at this summit commit to share the following intents
and will actively support their implementation in the respective capacities:
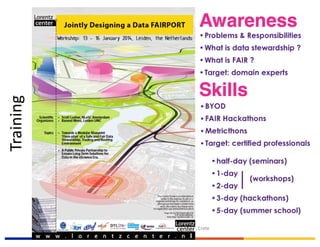
[Common culture of data stewardship]: In recognition of the long-term reuse value for
science and for innovation of much data created by research activities, European science must
be grounded in a common culture of data stewardship, so that research data is recognised as a
significant output of research and is appropriately curated throughout the research lifecycle.
[Open access by-default]: Open access is the default setting for all results of publically funded
research in Europe: this means that publicly-funded research data should be as open as possible
and as closed as necessary (allowing for proportionate limitations only in duly justified cases of](https://image.slidesharecdn.com/20170703fairdataprinciplesschultes-170713144857/85/The-FAIR-Data-Concept-EUDAT-Summer-School-Erik-Schultes-DTLS-41-320.jpg)







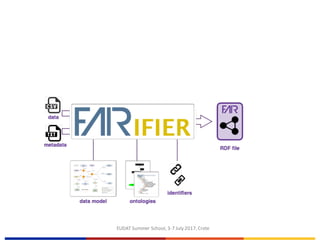
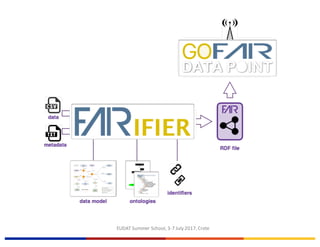
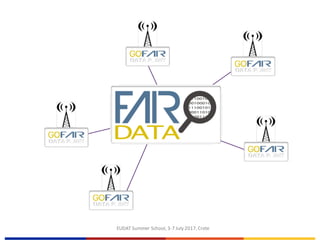
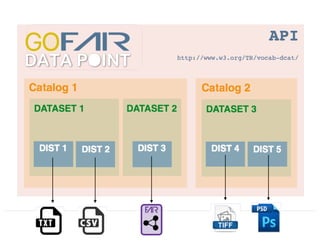

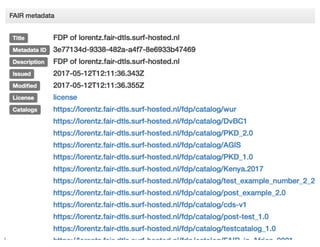





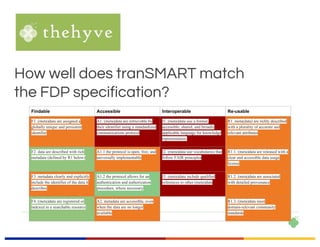
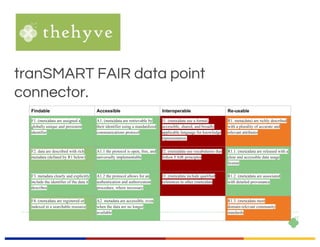





The EUDAT Summer School held from July 3-7, 2017, in Crete focused on data sharing, management, and the importance of adhering to fair data principles in research. Despite existing data sharing policies from organizations like Science, PubMed Central, and the NIH, the document outlines significant challenges faced by researchers, such as access difficulties and inadequate data documentation, leading to frustrations in data reuse. The session emphasized the need for a common culture of data stewardship and ongoing efforts towards open access and sustainable data practices in Europe.














































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







