1. Due to the volume of datastoredinHadoop clustersthere mightbe aneedforcompressionbasedon
companyneeds. The followingcomparisonaimsatsummarizingsome optionsandtheirtrade-offs.
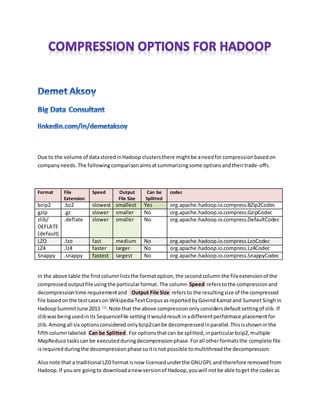
Format File
Extension
Speed Output
File Size
Can be
Splitted
codec
bzip2 .bz2 slowest smallest Yes org.apache.hadoop.io.compress.BZip2Codec
gzip .gz slower smaller No org.apache.hadoop.io.compress.GzipCodec
zlib/
DEFLATE
(default)
.deflate slower smaller No org.apache.hadoop.io.compress.DefaultCodec
LZO .lzo fast medium No org.apache.hadoop.io.compress.LzoCodec
LZ4 .lz4 faster larger No org.apache.hadoop.io.compress.Lz4Codec
Snappy .snappy fastest largest No org.apache.hadoop.io.compress.SnappyCodec
In the above table the firstcolumnliststhe format option,the second column the fileextensionof the
compressed outputfileusingthe particularformat.The column Speed referstothe compressionand
decompressiontime requirementand Output File Size refersto the resultingsize of the compressed
file basedonthe testcaseson WikipediaTextCorpusasreportedbyGovindKamatand Sumeet Singhin
HadoopSummitJune 2013 (1)
.Note that the above compressiononlyconsidersdefaultsettingof zlib.If
zlibwasbeingusedinits SequenceFile settingitwouldresult inadifferentperformace placementfor
zlib. Amongall six optionsconsidered onlybzip2canbe decompressedinparallel.Thisisshownin the
fifthcolumnlabeled Can be Splitted.For optionsthatcan be splitted,inparticularbzip2,multiple
MapReduce taskscan be executedduringdecompressionphase.Forall otherformatsthe complete file
isrequired duringthe decompressionphasesoitisnot possible tomultithreadthe decompression.
Alsonote that a traditional LZOformatisnow licensedunderthe GNUGPL and therefore removedfrom
Hadoop. If youare goingto downloadanew versionof Hadoop,youwill notbe able toget the codecas
2. part of yourdownload.Therefore the codecshouldbe downloadedseparatelyandenabledmanually
and thenyouwill be able touse it as before.LZOisstill supportedwithinthe code base if you wantto
continue usingit.
It ispossible touse differentcompressiontechniquesatdifferentphasesof MapReduce since the
requirementsof eachphase showsvariations.Itispossible touse compression/decompressiononlyata
particularphase.Forinstance,duringShuffleandSortphase compressioncanbe quite useful toreduce
the networktransferlatency. FastercodecsasLZO,LZ4 or Snappycan be preferred inthisphase toavoid
additional CPUoverheadduringcompression/decompression.Incontrastduringthe initial Mapphase it
ispossible toinvestinslowercodecssuchas bzip2or zlibwithSequenceFile settingtomake use of
parallelismatthisstage.Duringthe Reduce phase gzipcan be used fordata interchange forchained
jobs.It ispossible touse bzip2as well duringthe reduce phase asafastercodec. Compressionduring
Reduce phase helpsreduce storage requirementsforarchival dataand improve write speeds.
The decisiononwhetherto applycompressionforanyphase of the MapReduce jobisa decisionthat
can be made basedon the trade-offsbetweenreducedstorage,networktransferloadandthe
additional CPUoverheadrunningthe compressioncodec.Forbasictaskswhere data transferoverheads
are significantlylarger,the clientswouldbenefitlargelyoncompressionaslongas the CPU overheadon
the commoditymachinesdonotresultinan additional overhead.
Please note thatHadoopjobsare data intensive andbasedonthe clients’hardware,e.g.,racksversus
commoditymachine clusters,optical networkconnectionversusall the waytooldfashionedRS232
connections, decisionsoncompressioncanbe made asa general solutionora particularjobbased
solution.
(1)
GovindKamatand SumeetSingh,CompressionOptionsInHadoop – A Tale of Tradeoffs,
HadoopSummit,SanJose,June 2013, http://www.slideshare.net/Hadoop_Summit/kamat-
singh-june27425pmroom210cv2