Download as PDF, PPTX



















![Vector Space Model [Salton and McGill, 1983]
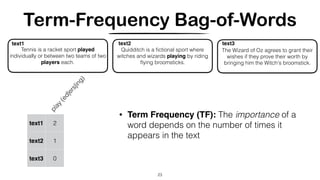
• A document is represented by a high-dimensional vector in the
space of words
• A basic vocabulary of “words” or “terms” is chosen, and, for each
document in the corpus, a count is formed of the number of
occurrences of each word.
• After suitable normalization, this term frequency count is
compared to an inverse document frequency count, which
measures the number of occurrences of a word in the entire
corpus (generally on a log scale, and again suitably normalized).
• The end result is a term-by-document matrix X whose columns
contain the tf-idf values for each of the documents in the corpus.
• Thus the tf-idf scheme reduces documents of arbitrary length to
fixed-length lists of numbers.
26
…
0 5 ..
0 2 2 ..
4 1 0 ..
…
term-by-document
matrix
doc1 doc2 doc3
1
0
4](https://image.slidesharecdn.com/crosslingual-similarity-191120215653/85/Cross-lingual-Similarity-26-320.jpg)






![1
4
0
concept-space (k dimensional)
terms
documents
terms
dims
dims
dims
dims
documents
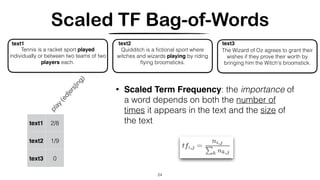
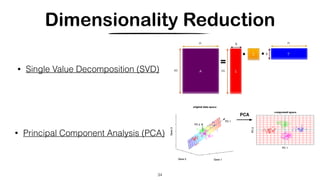
Latent Semantic Analysis (LSA/LSI) [Deerwester et. al, 1990]
• Map documents (and terms) to a low-dimensional representation by
SVD
35
Hard to interpret
Dimensionality Reduction
* it can capture some aspects of basic linguistic notions such as synonymy and polysemy](https://image.slidesharecdn.com/crosslingual-similarity-191120215653/85/Cross-lingual-Similarity-35-320.jpg)
![1
4
0
terms
documents
terms
topics
topics
documents
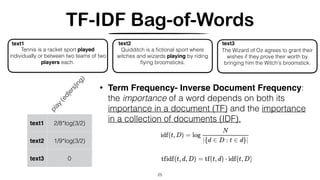
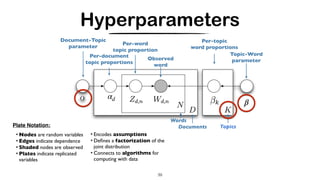
probabilistic LSA/LSI [Hofmann, 1999]
• Each word is generated from a single topic, and different words in a document may be
generated from different topics.
• Each document (bag-of-words) is DESCRIBED as a list of mixing proportions for these topics
36
No generative model at the level of documents -> No Inference (given an unseen texts, we cannot determine which topics it belongs to)
Mixture Components as representation of “topics”](https://image.slidesharecdn.com/crosslingual-similarity-191120215653/85/Cross-lingual-Similarity-36-320.jpg)
![1
4
0
terms
documents
terms
topics
topics
documents
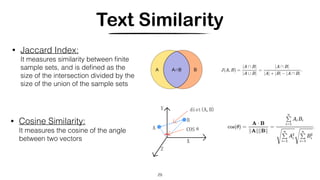
Latent Dirichlet Allocation (LDA) [Blei et. al, 2003]
37
• Each word is generated from a single topic, and different words in a document may be
generated from different topics.
• Each document (bag-of-words) is GENERATED from a mixture of topics
Generative model of terms and documents
Parameters do not grow with the size of the training corpus](https://image.slidesharecdn.com/crosslingual-similarity-191120215653/85/Cross-lingual-Similarity-37-320.jpg)

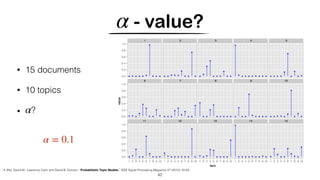
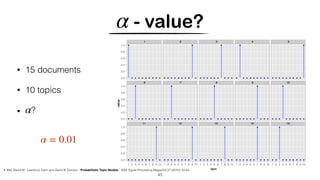


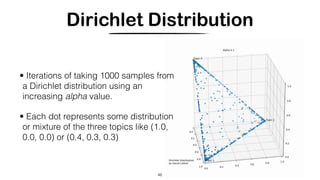







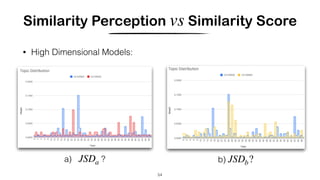
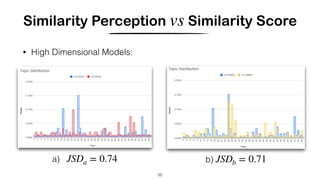
![Hashing Topic Distributions [Badenes-Olmedo et. al, 2019]
56
Hash methods based on hierarchical set of topics:
Badenes-Omedo, C., Redondo-García, J. L., & Corcho, O. (2019).
Large-Scale Semantic Exploration of Scientific Literature using Topic-based Hashing Algorithms. Semantic Web Journal.](https://image.slidesharecdn.com/crosslingual-similarity-191120215653/85/Cross-lingual-Similarity-56-320.jpg)
![Topic-based Approximate Nearest Neighbour [Badenes-Olmedo et. al, 2019]
57
{(t6),(t5)}
{(t6),(t2)}
{(t5),(t4)}
{(t4),(t5)}
{(t2),(t3)}{(t4),(t2)}
L0
L1
L0 L1](https://image.slidesharecdn.com/crosslingual-similarity-191120215653/85/Cross-lingual-Similarity-57-320.jpg)











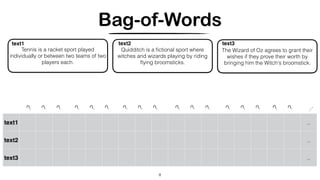
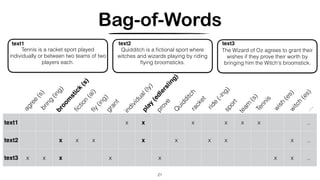
1. The document discusses various techniques for representing and comparing texts, including tokenization, removing stopwords, stemming, n-gram analysis, and bag-of-words modeling using term frequency and TF-IDF. 2. It provides examples applying these techniques to calculate the similarity between three sample texts using n-gram analysis and cosine similarity calculations. 3. The techniques are used to build vector representations of documents that can be compared to determine similarity and enable applications like document retrieval and multi-lingual analysis.

































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)














