
Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Similar to Aryaan_CV
Similar to Aryaan_CV (20)
Aryaan_CV
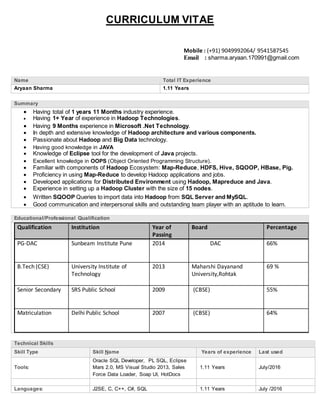
- 1. CURRICULUM VITAE Mobile : (+91) 9049992064/ 9541587545 Email : sharma.aryaan.170991@gmail.com Summary Having total of 1 years 11 Months industry experience. Having 1+ Year of experience in Hadoop Technologies. Having 9 Months experience in Microsoft .Net Technology. In depth and extensive knowledge of Hadoop architecture and various components. Passionate about Hadoop and Big Data technology. Having good knowledge in JAVA Knowledge of Eclipse tool for the development of Java projects. Excellent knowledge in OOPS (Object Oriented Programming Structure). Familiar with components of Hadoop Ecosystem: Map-Reduce, HDFS, Hive, SQOOP, HBase, Pig. Proficiency in using Map-Reduce to develop Hadoop applications and jobs. Developed applications for Distributed Environment using Hadoop, Mapreduce and Java. Experience in setting up a Hadoop Cluster with the size of 15 nodes. Written SQOOP Queries to import data into Hadoop from SQL Server and MySQL. Good communication and interpersonal skills and outstanding team player with an aptitude to learn. Educational/Professional Qualification Qualification Institution Year of Passing Board Percentage PG-DAC Sunbeam Institute Pune 2014 DAC 66% B.Tech (CSE) University Institute of Technology 2013 Maharshi Dayanand University,Rohtak 69 % Senior Secondary SRS Public School 2009 (CBSE) 55% Matriculation Delhi Public School 2007 (CBSE) 64% Technical Skills Skill Type Skill Name Years of experience Last used Tools: Oracle SQL Developer, PL SQL, Eclipse Mars 2.0, MS Visual Studio 2013, Sales Force Data Loader, Soap UI, HotDocs 1.11 Years July/2016 Languages: J2SE, C, C++, C#, SQL 1.11 Years July /2016 Name Total IT Experience Aryaan Sharma 1.11 Years
- 2. Feameworks /Technologies : Hadoop 2.0, Hive, Sqoop, Pig, HBase, Spark, MapReduce, Asp.Net, MVC 5.0, JavaScript, JQuery, AngularJS 1.11 Years July /2016 Operating System Ubuntu , Cassandra, Windows 10, Windows 8, Windows7, Windows XP, Windows Server 2008 R2 1.11 Years July /2016 Employment History Organization Name Organization Location & Address Tenure (MM/YY) Designation Start Date End Date Digital Group InfoTech Pvt. Ltd Hinjewadi, Pune September 10, 2014 Till Date Software Engineer Project Details Project 1: Project Name * Verizon Network Client name* Verizon, Network Providers in the US Project Description* Verizon is one of the major network providers in the US offering a wide variety of plans for consumers. This involves storing millions of callers' records, providing real time access to call records and billing information to the customers. Traditional storage systems would not be able to scale to the load. Since the data is really large, manual analysis is not possible. For the handling of such large data and for providing analytics, Hadoop is used. Technologies Used * Hadoop, HDFS, Hive, HBase, Zookeeper, Oozie, Hadoop Distribution of Cloudera, Java (jdk1.6), Oracle, Spark, Sqoop. Team Size* 5 Duration* On Going •Responsibilities :- 1. Responsible for gathering requirements from the business partners. 2. Application development using Hadoop tools like Map-Reduce, Hive, Pig, HBase, oozie, 3. Cluster Monitoring and Troubleshooting, manage and review data backups and log •Zookeeper and Sqoop:- 1. Collected the log data from web servers and integrated into HDFS using Sqoop. 2. Developed a process for Sqooping data from multiple sources like SQL Serve. •Oracle :- 1. Developed Oozie workflow's for executing Sqoop and Hive actions. 2. Worked on Hadoop cluster which ranged from 8-10 nodes during pre-production stage and it was sometimes extended up to 15 nodes during production 3. Responsible for Cluster maintenance, adding and removing cluster nodes. •Files : - 1. Managing and scheduling Jobs on a Hadoop cluster. 2. Involved in defining job flows, managing and reviewing log files. 3. Installed Oozie workflow engine to run multiple Map Reduce, Hive HQL and Pig • Jobs : - 1. Responsible to manage data coming from different sources. 2. Data manupulation used the NOSQL (Hbase)
- 3. 3. Developed Hive scripts for performing transformation logic and also loading Project 2: Project Name * ADS- Arrow Data Services Client name* CT Corporation System(“CT)”, a Wolters Kluwer Company, USA Project Description* As the name Suggest, ADS is a service based Application which is developed for providing Service End Points to “CT” on going Applications. In this project we have used Service Stack as Feamework as it provides more features than Web API. Technologies Used * Asp.Net, Web API, Service Stack, SQL Team Size* 3 Duration* 4 Months Responsibilities* Development Unit Testing Data Base Project 3: Project Name * CT BLM Client name* CT Corporation System(“CT)”, a Wolters Kluwer Company, USA Project Description* BLMS is an application for business customers who wants to manage their business licenses. Application is a flexible reporting functionality that would allow internal users to view CTA Business License data. The following are the requirements which will be built in this application View License-Location License Fee History License History License Documents License Compliance Events information License Group Advance Search for licenses and quick views Technologies Used * ASP.Net, MVC, Angular JS, Web API, SQL Team Size* 12 Duration* 1 Months Responsibilities* UI Design Development Unit Testing( Client Side as well as Server Side) Data Base Project 4: Project Name * Knowledge Express Redesign Client name* CT Corporation System(“CT)”, a Wolters Kluwer Company, USA Project Description* Knowledge Express (KE) is a tool that assists employees in filing and retrieving documents. It has existed in some form since CT has been providing "on-demand" services. As of today, KE has the most information and robust search ability options than it has ever had. Knowledge Express is primarily an internal information database designed to maintain statutory and verified administrative policy information needed to assist Service Teams with filing
- 4. requirements for the various entity types supported by CT. You will find business entity filing requirements including charts, news and filing office schedule information, registered agent information, fees pertaining to filings covered within KE, completion and execution instructions, special agency information and UCC and Fulfilment information Technologies Used * ASP.Net, MVC, Angular JS, Web API, Salesforce, SQL Team Size* 9 Duration* 4 Months Responsibilities* UI Design Development Unit Testing Data Base Personal Details: Father’s Name Ashwani Sharma Date of Birth 17-09-1991 Sex Male Place of Birth Rohtak Nationality Indian Marital Status Single Passport Details (Mention if applicable) Valid Passport (Y/N) G6953228 Valid Through 11/02/2018 Declaration I confirm that the information provided by me in this application form is accurate and correct. Signature Aryaan Sharma Date July 04, 2016 Place Hinjewadi Pune