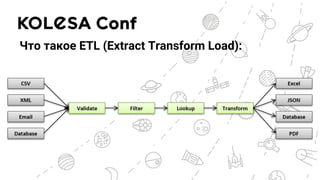
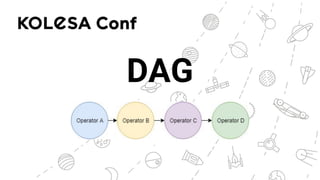
Документ обсуждает применение ETL-процессов на Python, включая использование решений, таких как Apache Airflow и Luigi для создания идемпотентных дата пайплайнов. Он описывает основные проблемы ETL-процессов и их эволюцию, а также дает примеры кода для реализации задач с использованием этих инструментов. Также рассматриваются альтернативы для управления потоками данных, такие как Apache NiFi и Prefect.