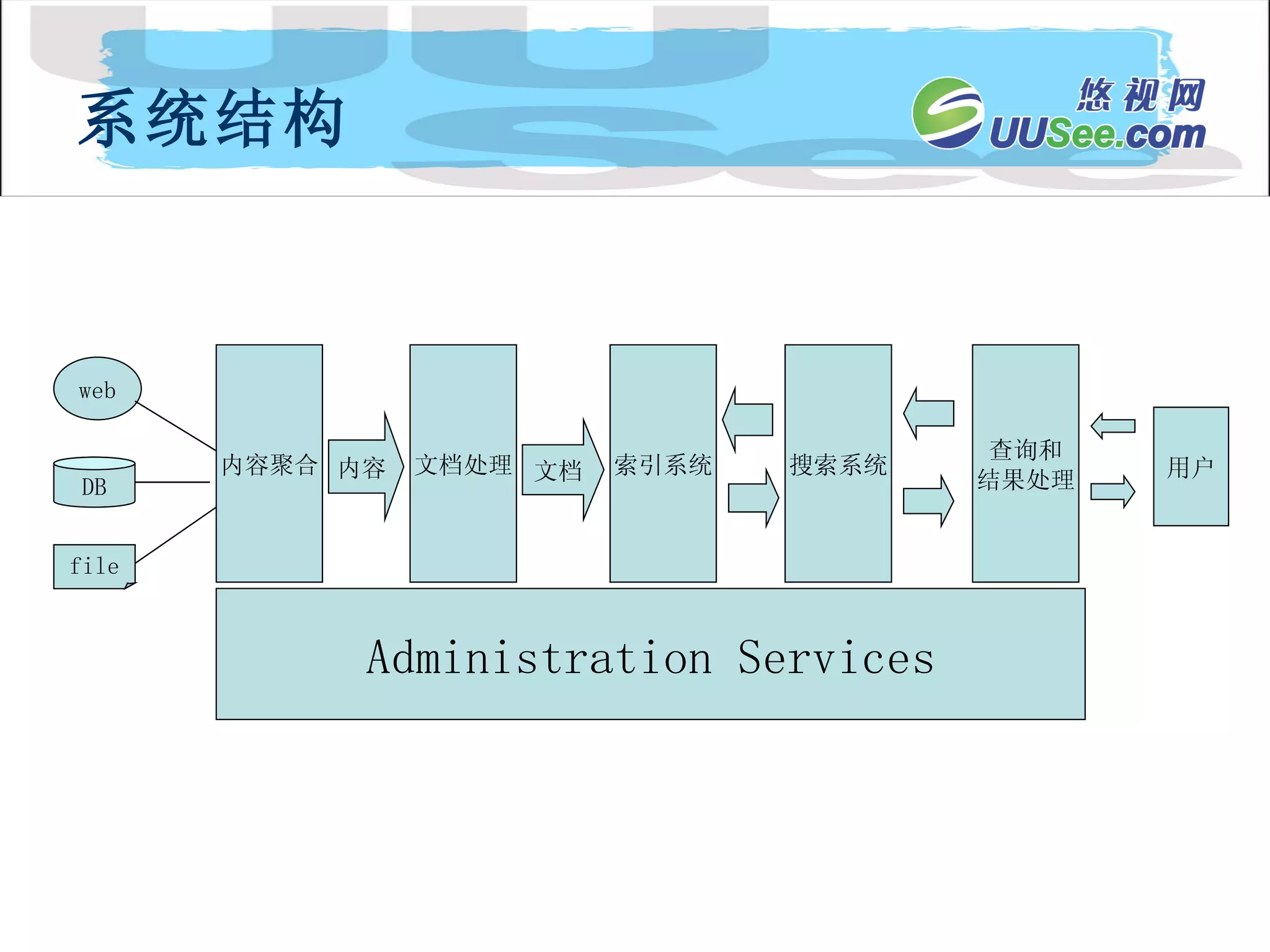
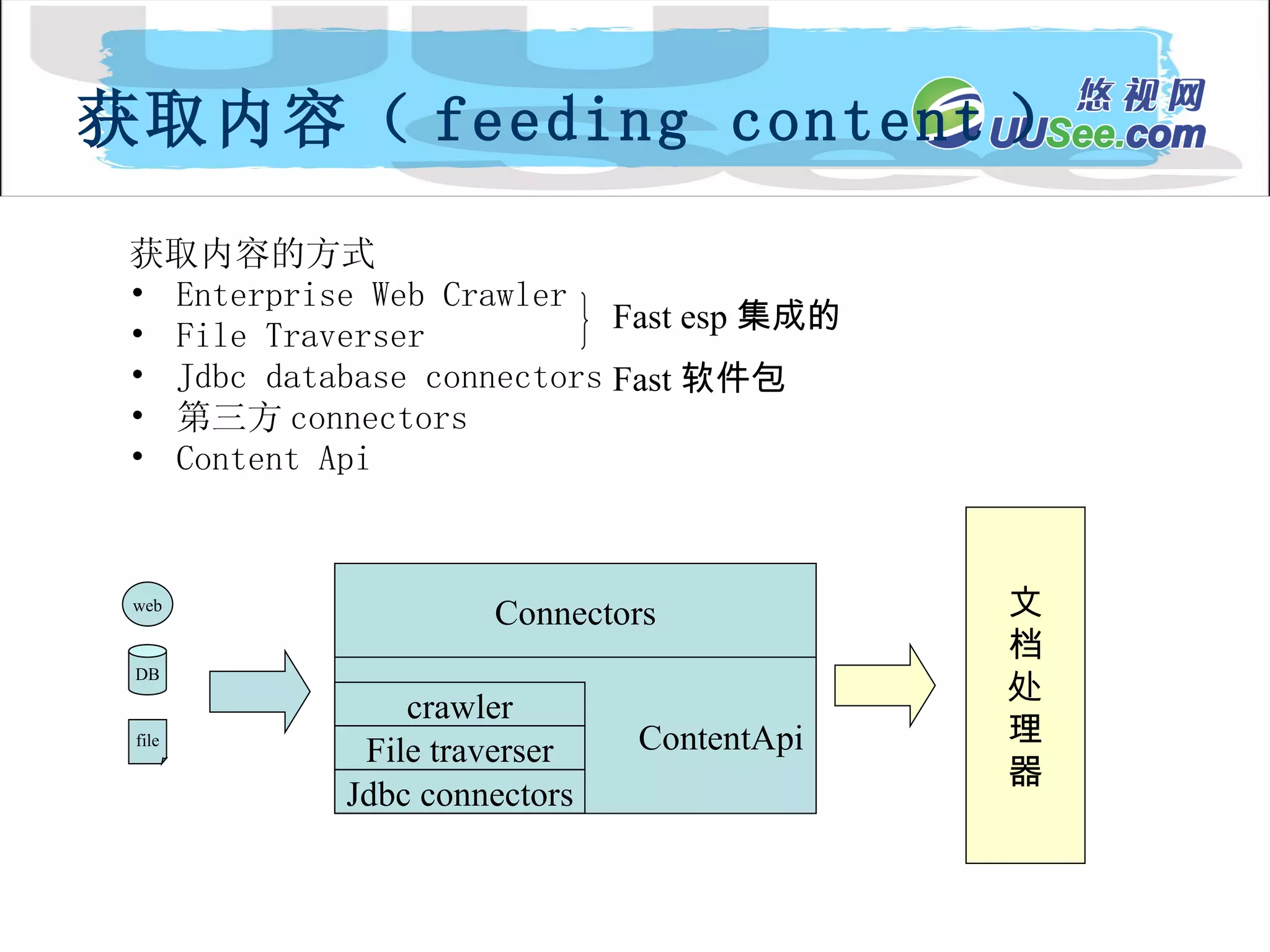
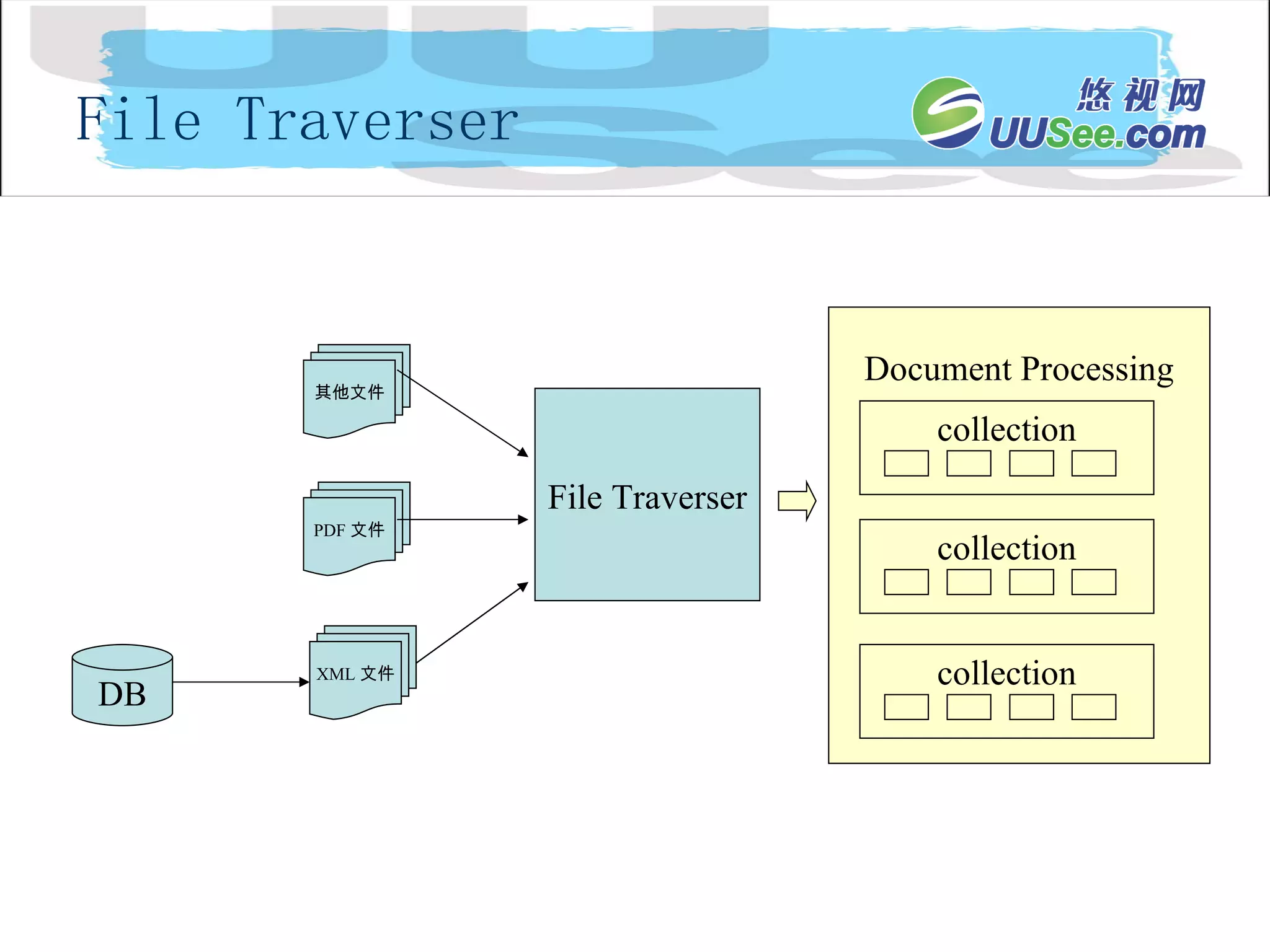
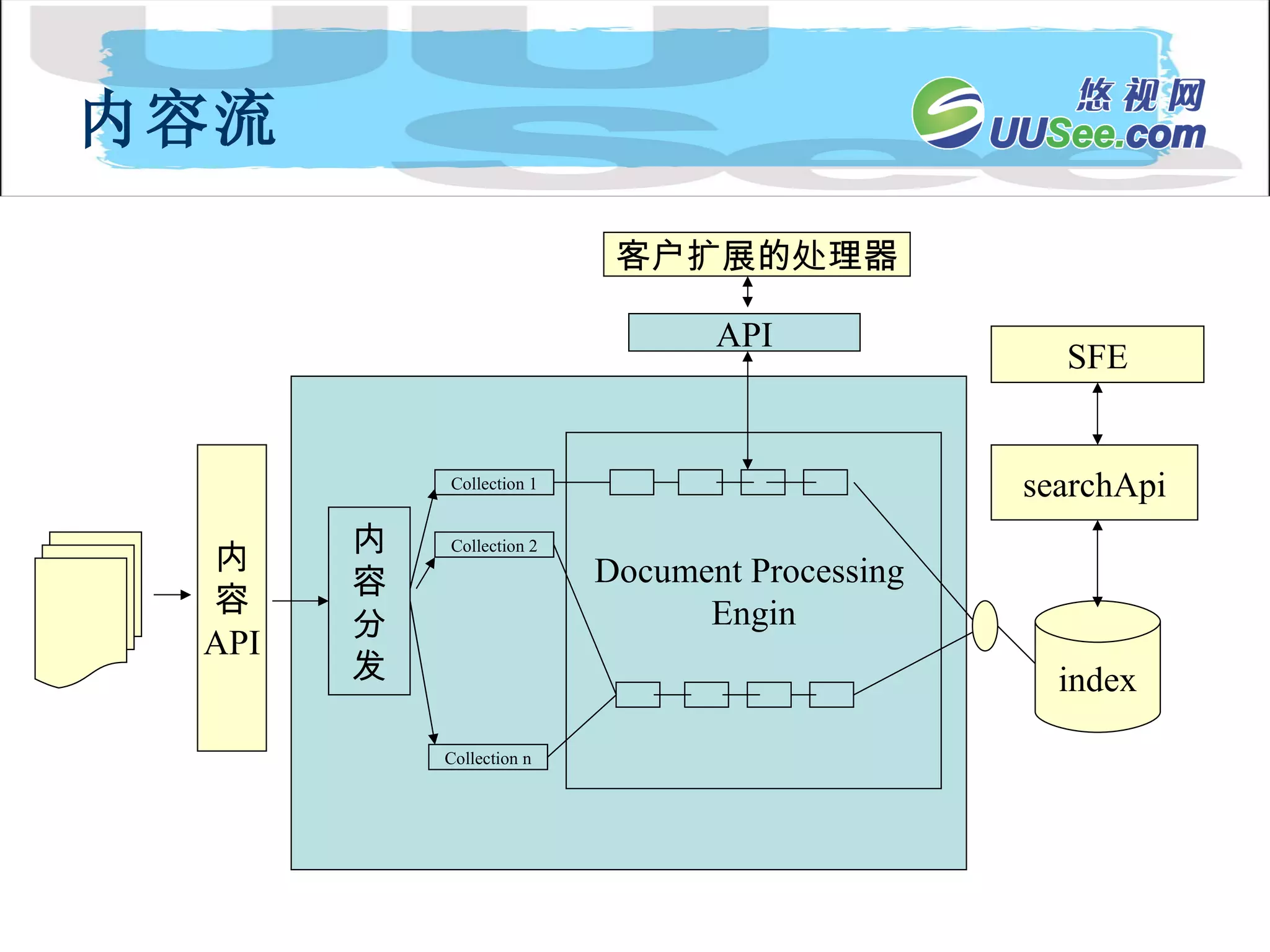
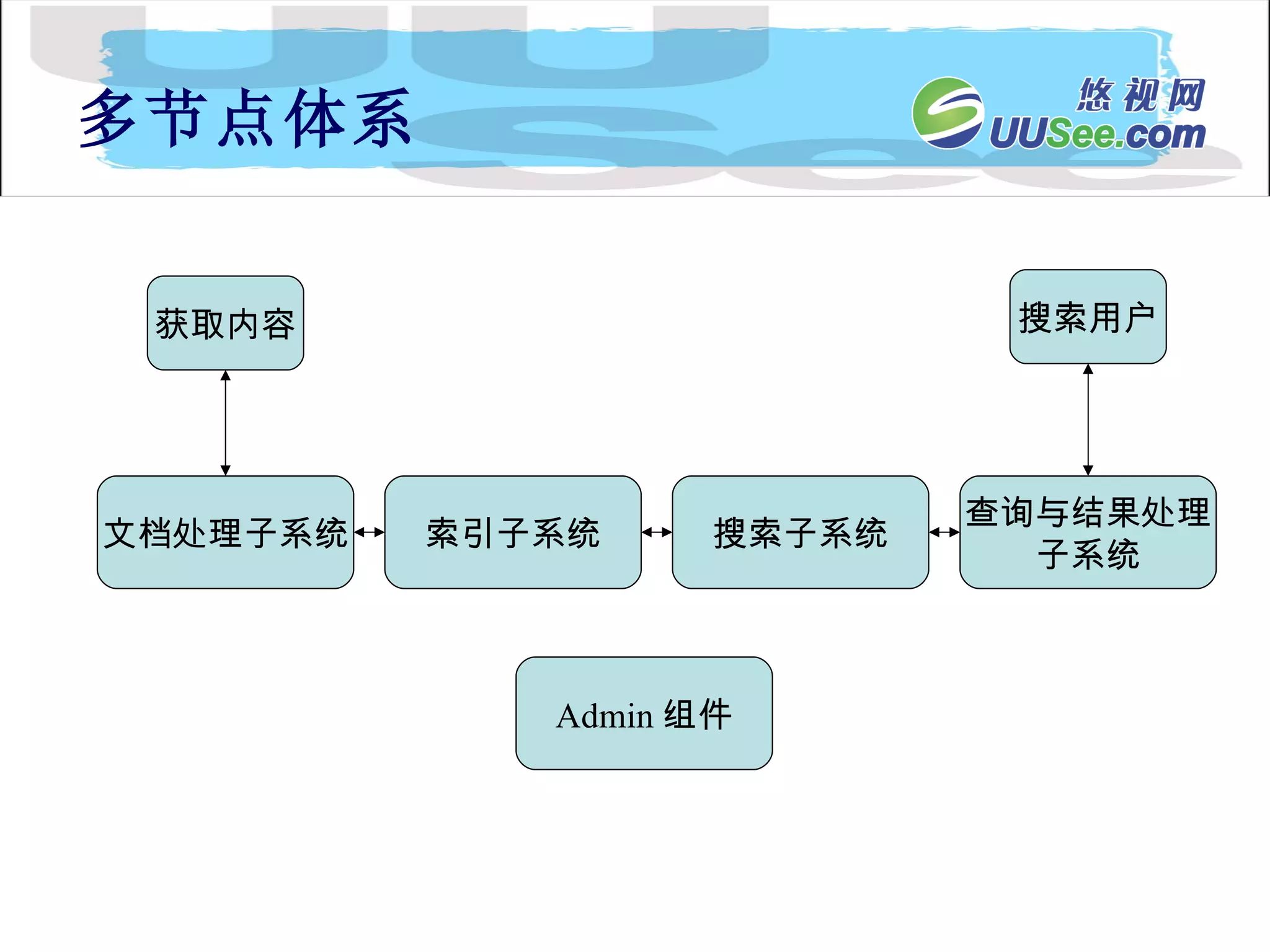
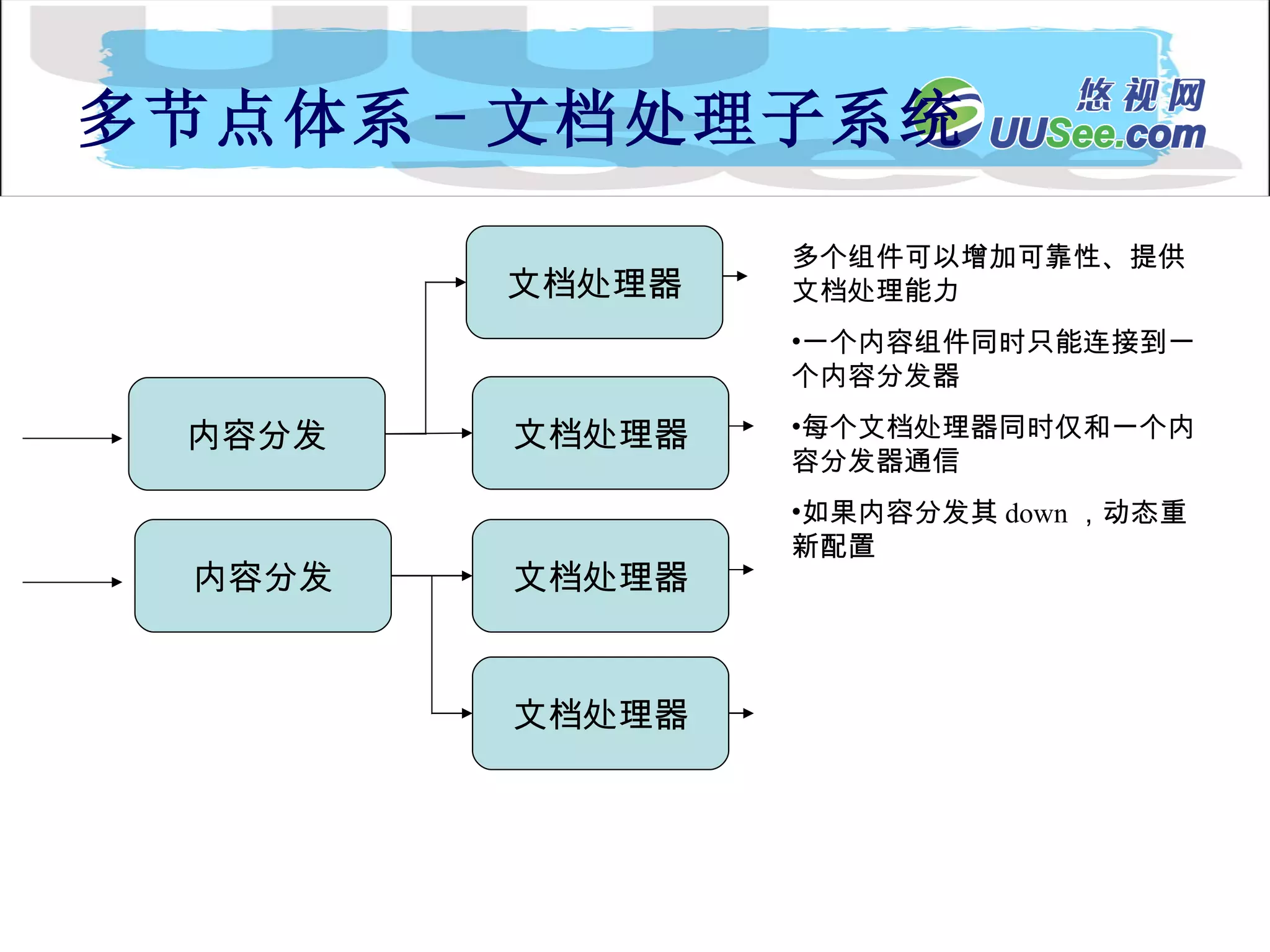
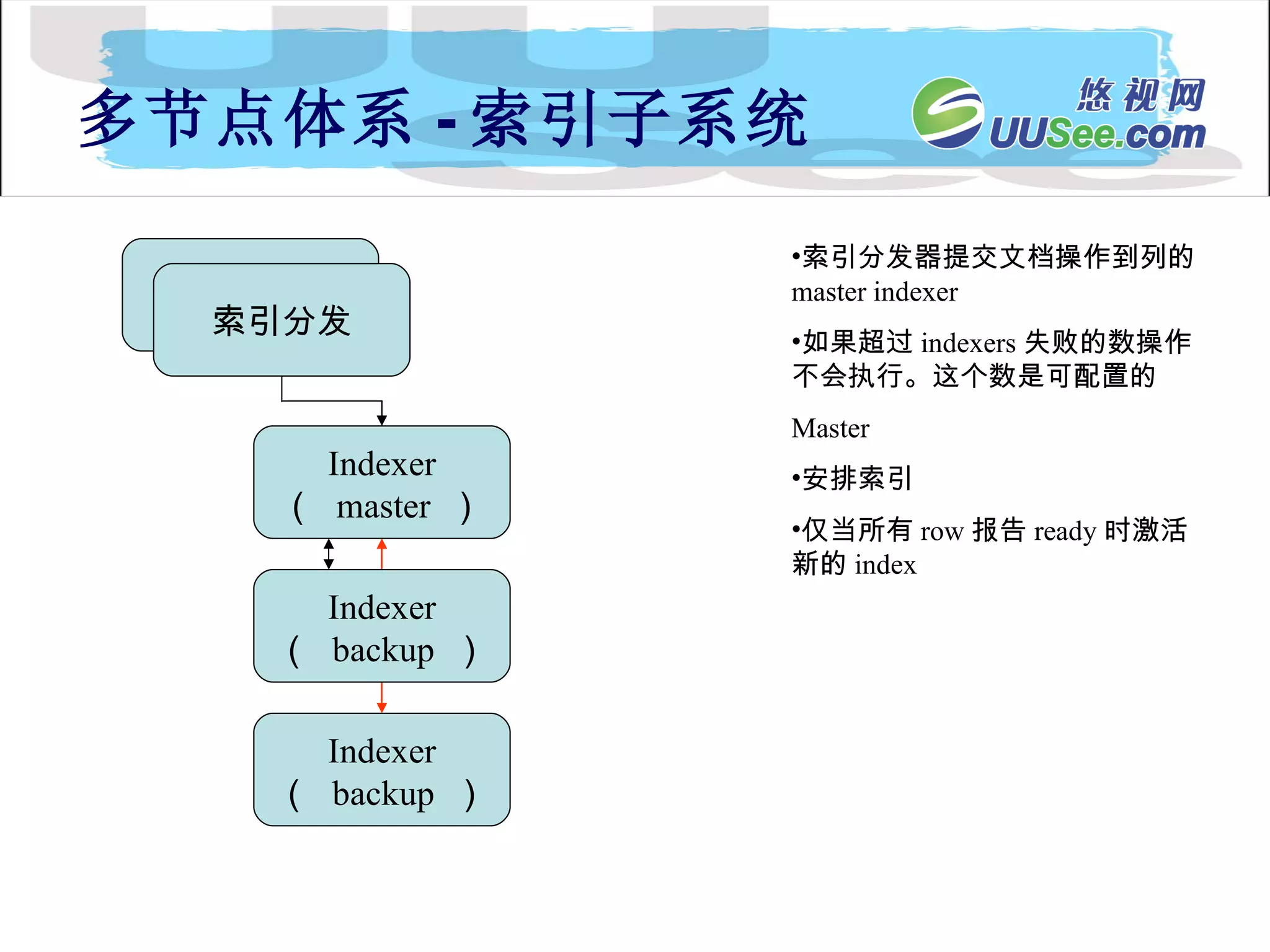
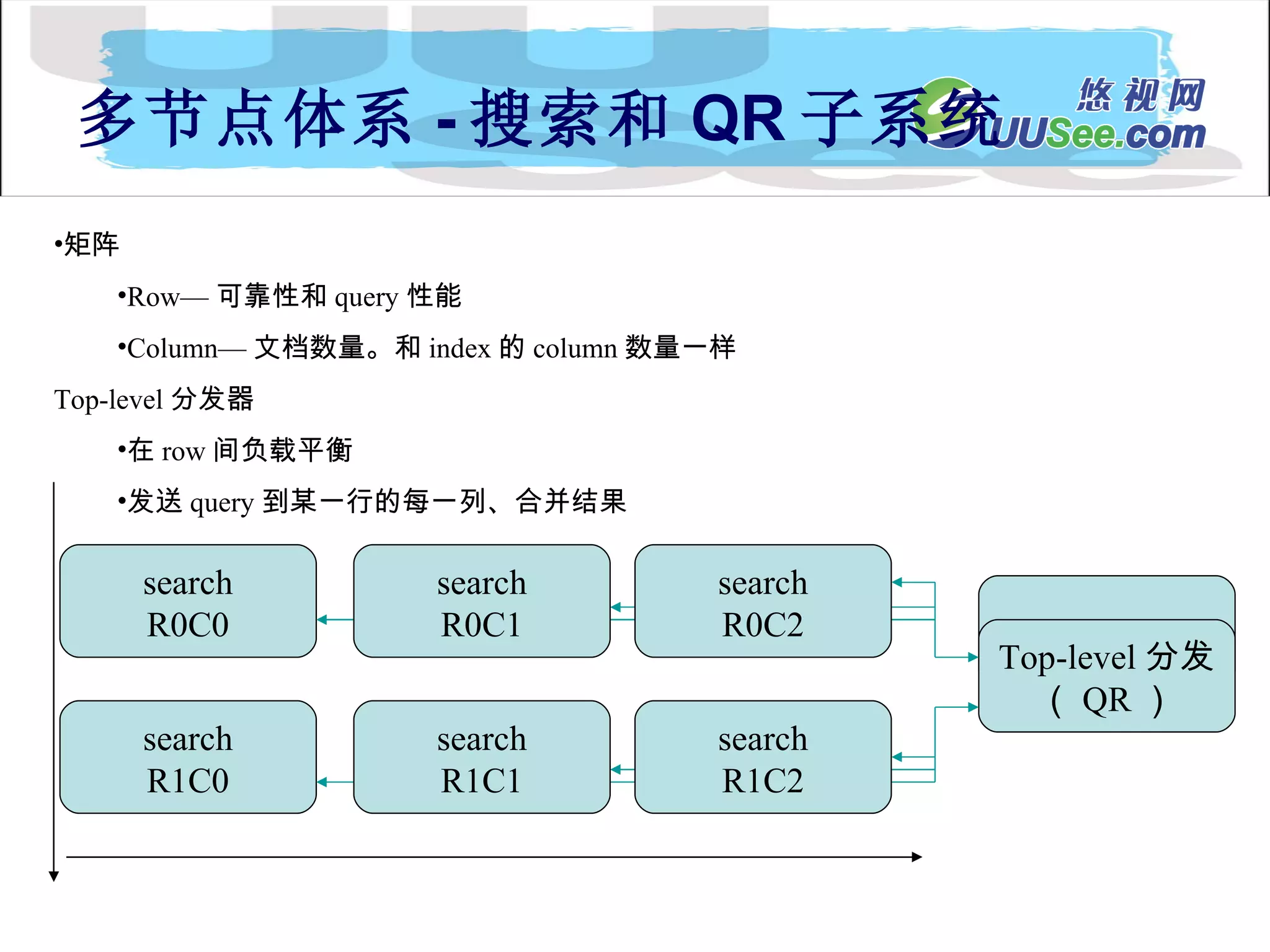
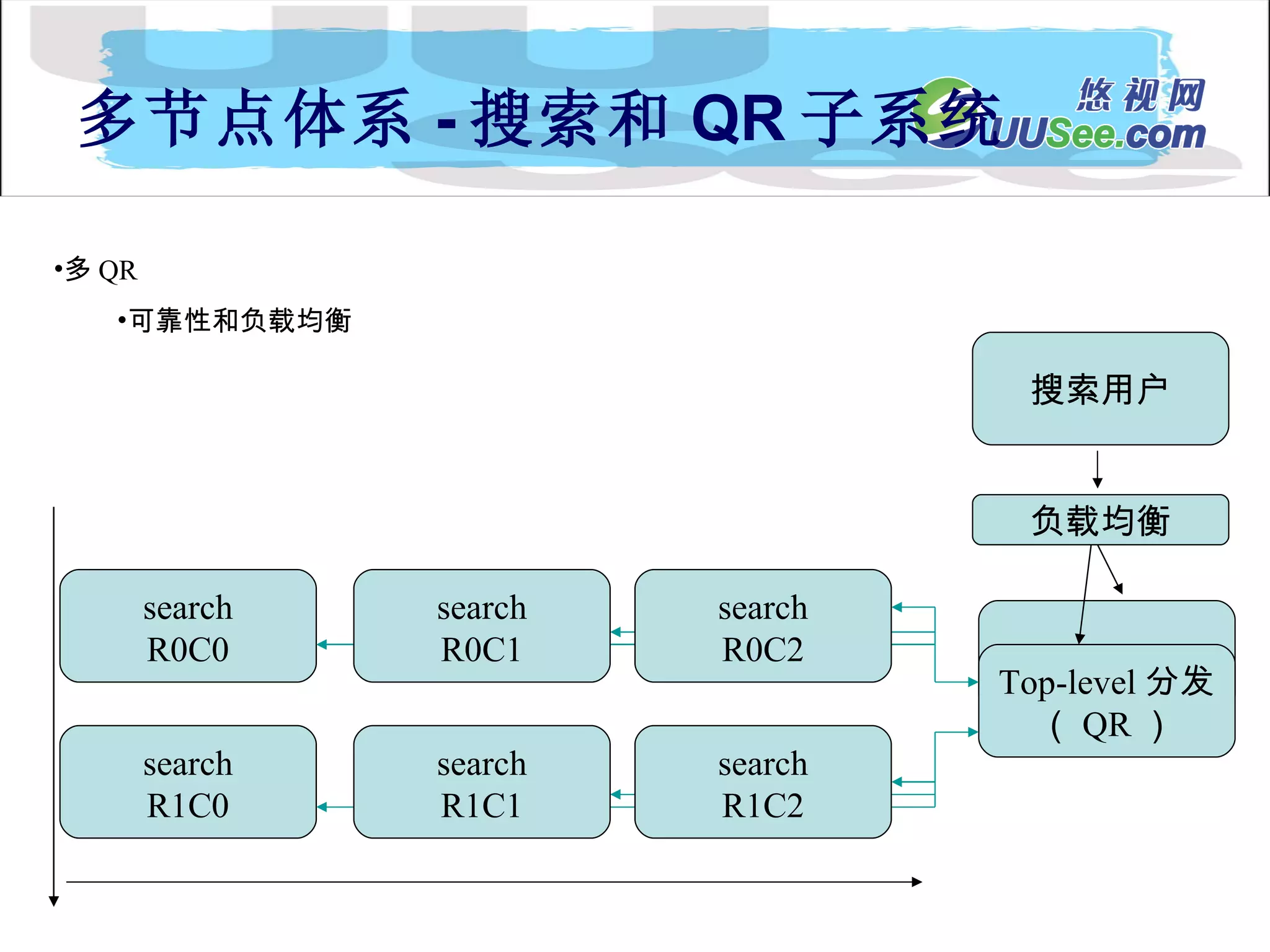
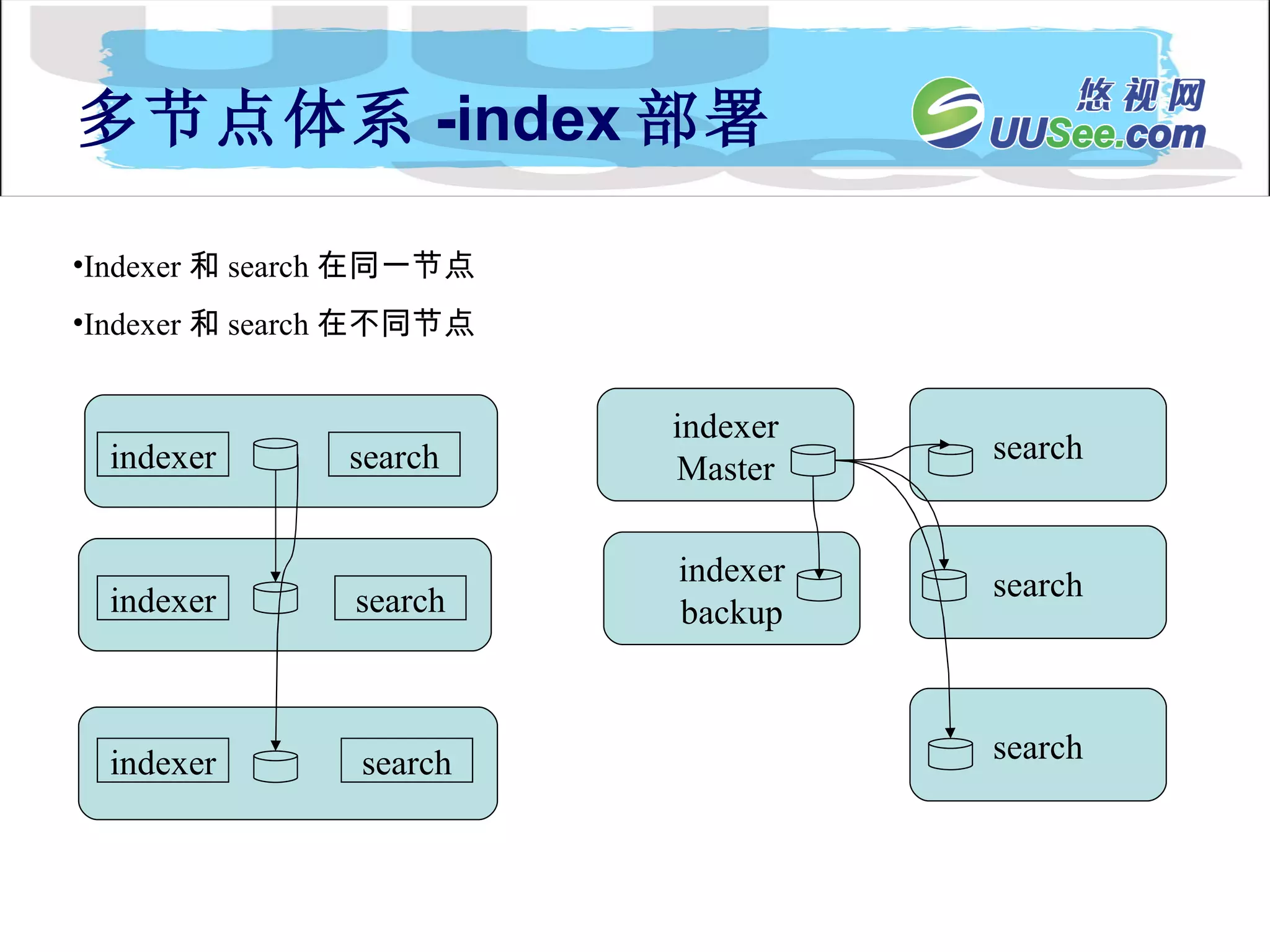
内容流 Document Processing Engin Collection 1 内 容 API 内 容 分 发 index searchApi SFE Collection n Collection 2 API 客户扩展的处理器
18.
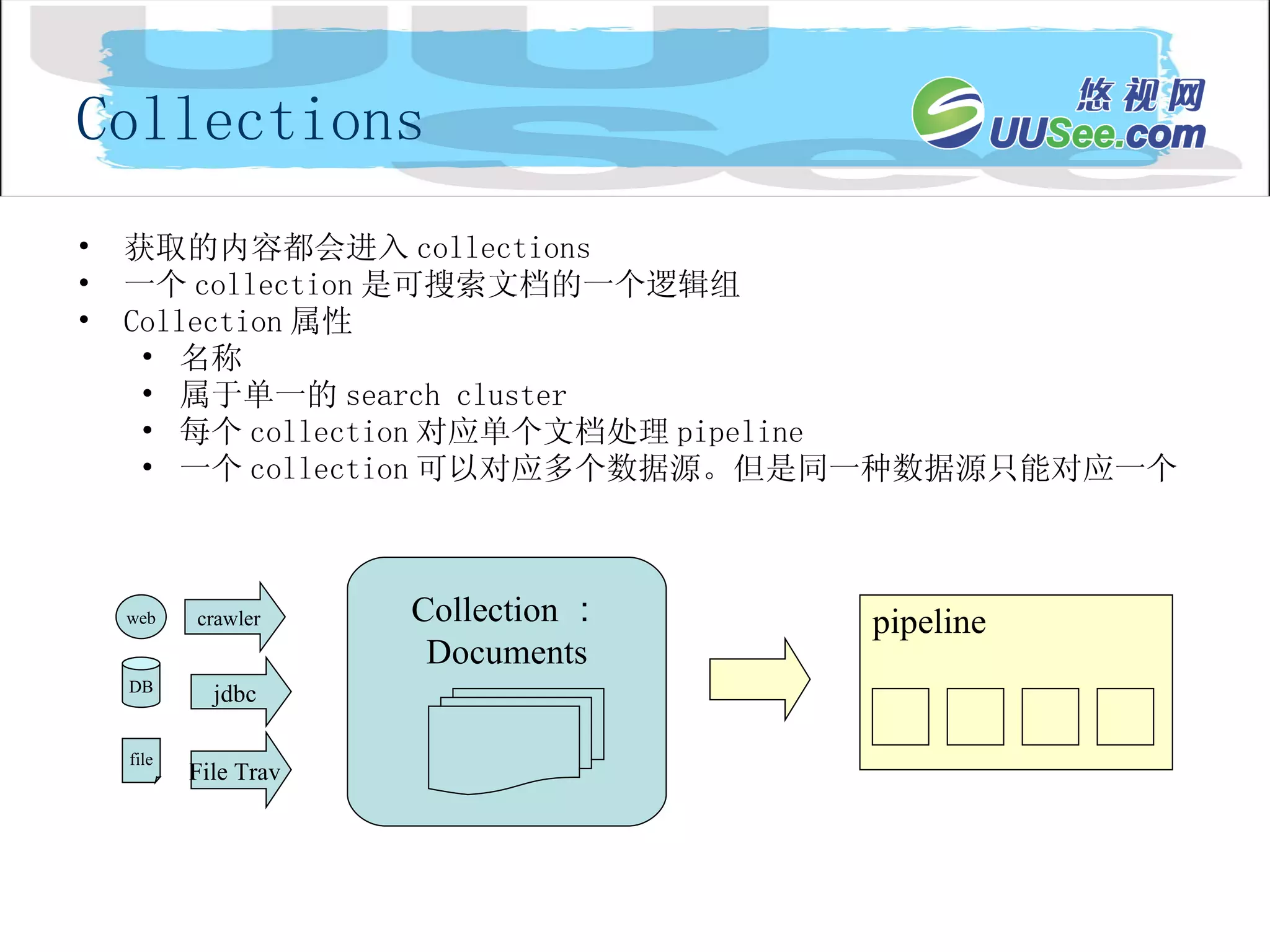
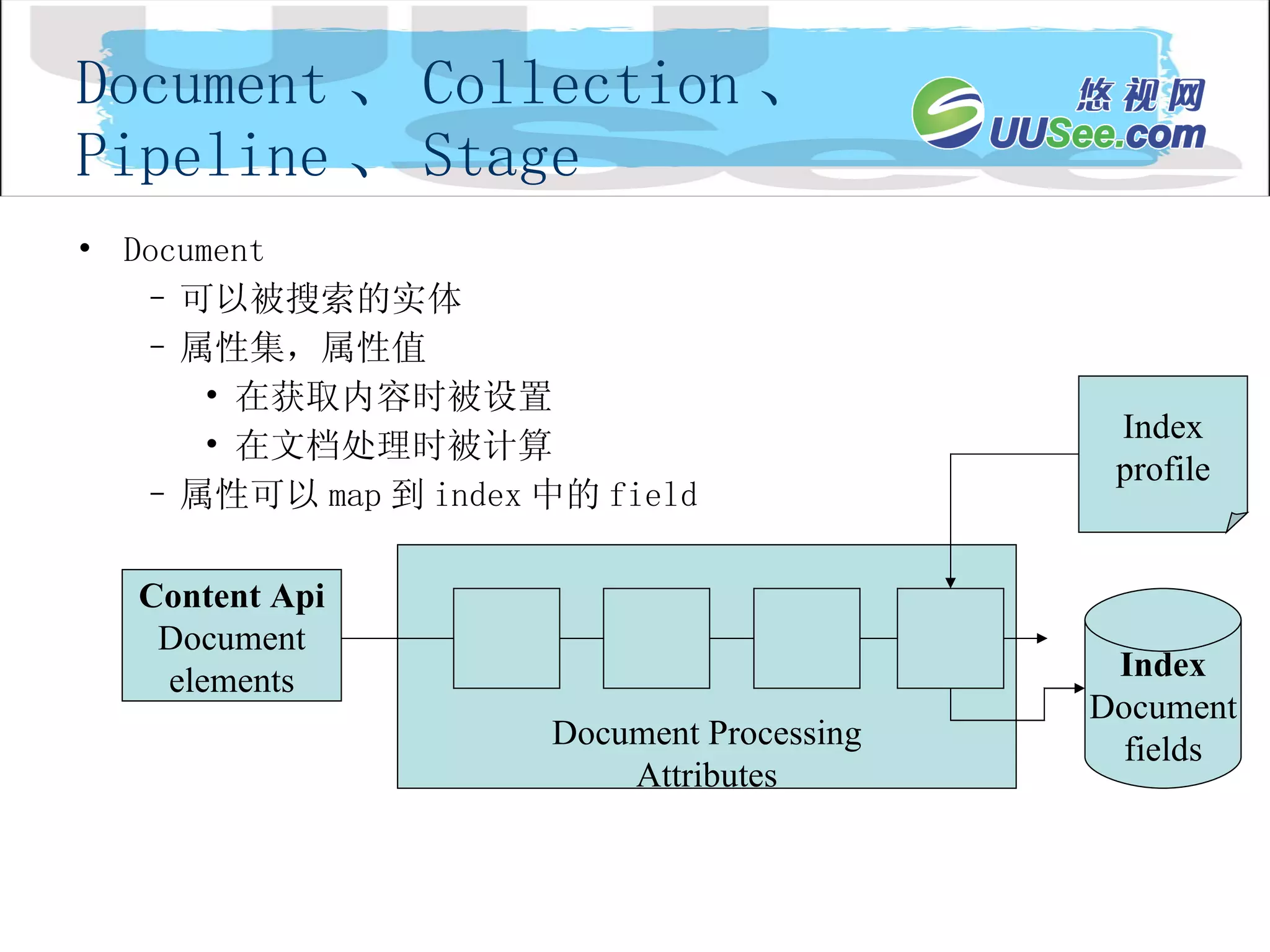
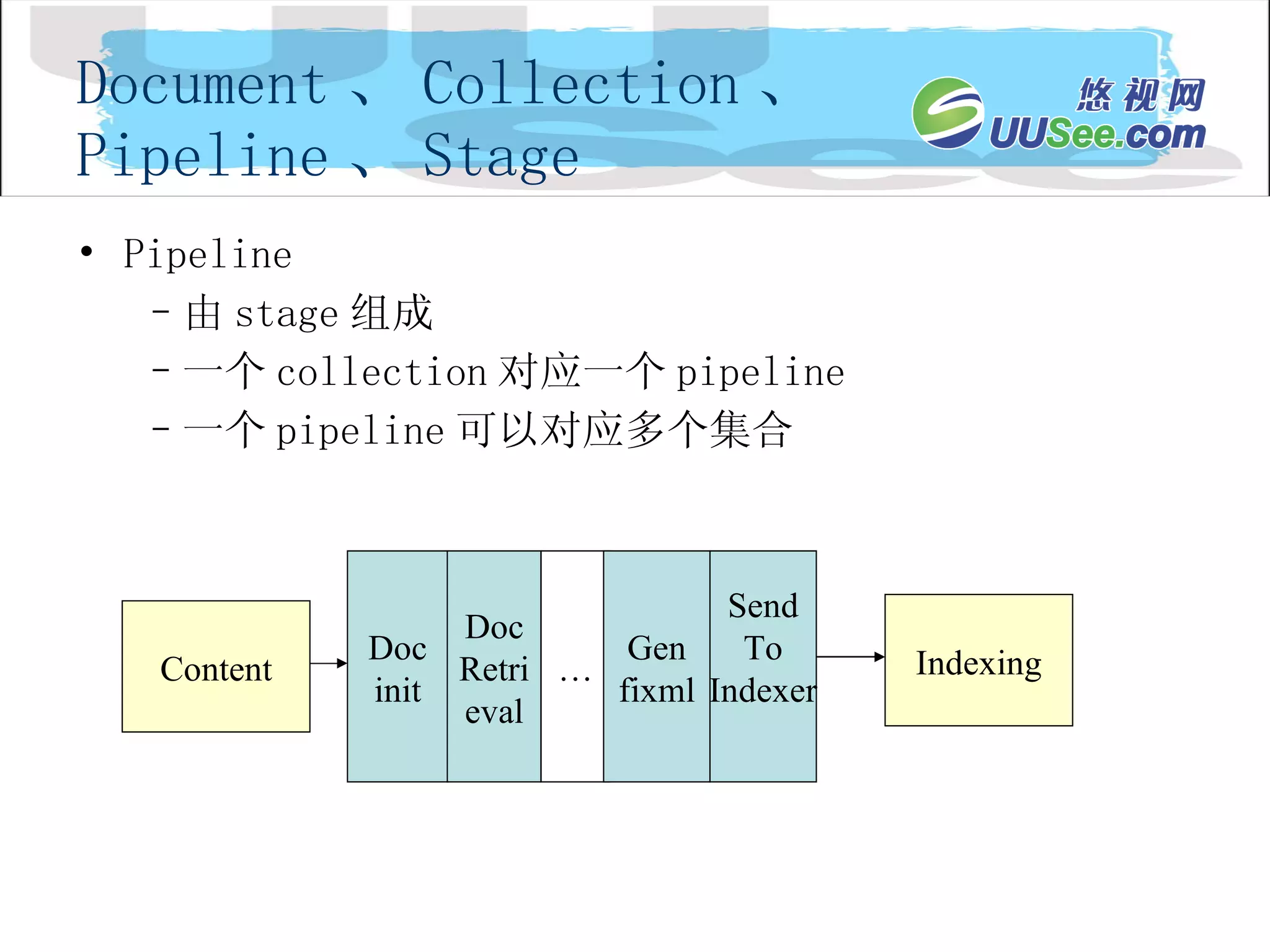
Document 、 Collection、 Pipeline 、 Stage Document 可以被搜索的实体 属性集,属性值 在获取内容时被设置 在文档处理时被计算 属性可以 map 到 index 中的 field Document Processing Attributes Content Api Document elements Index Document fields Index profile
Fields Field 的属性Linguistics Searching Sorting Result display Type:string/int32/uint32/geo/float/double/datetime 例子 <field name=“title” fullsort=“yes” tokenize=“auto|delimiters” lemmatize=“yes”> <vectorize default=“10:0”> </field> <field name=“size”type=“int32”fullsort=“yes”/> 文档处理相关
27.
Scope field 对应结构化的xml 文档。等级结构 . Type:text 例子 Input: <book> <chapter> <id type=“int32”>1</id> <heading>act 1</heading> <sentence>sen1</sentence> <sentence>sen2</sentence> </chapter> </book> 文档处理器 map 到 xml field : xml: book : (string) chapter:(string) id:1(type=int32) heading:”act1”(string) sentence:”sen1”(string) sentence:”sen2”(string) 文档处理相关
28.
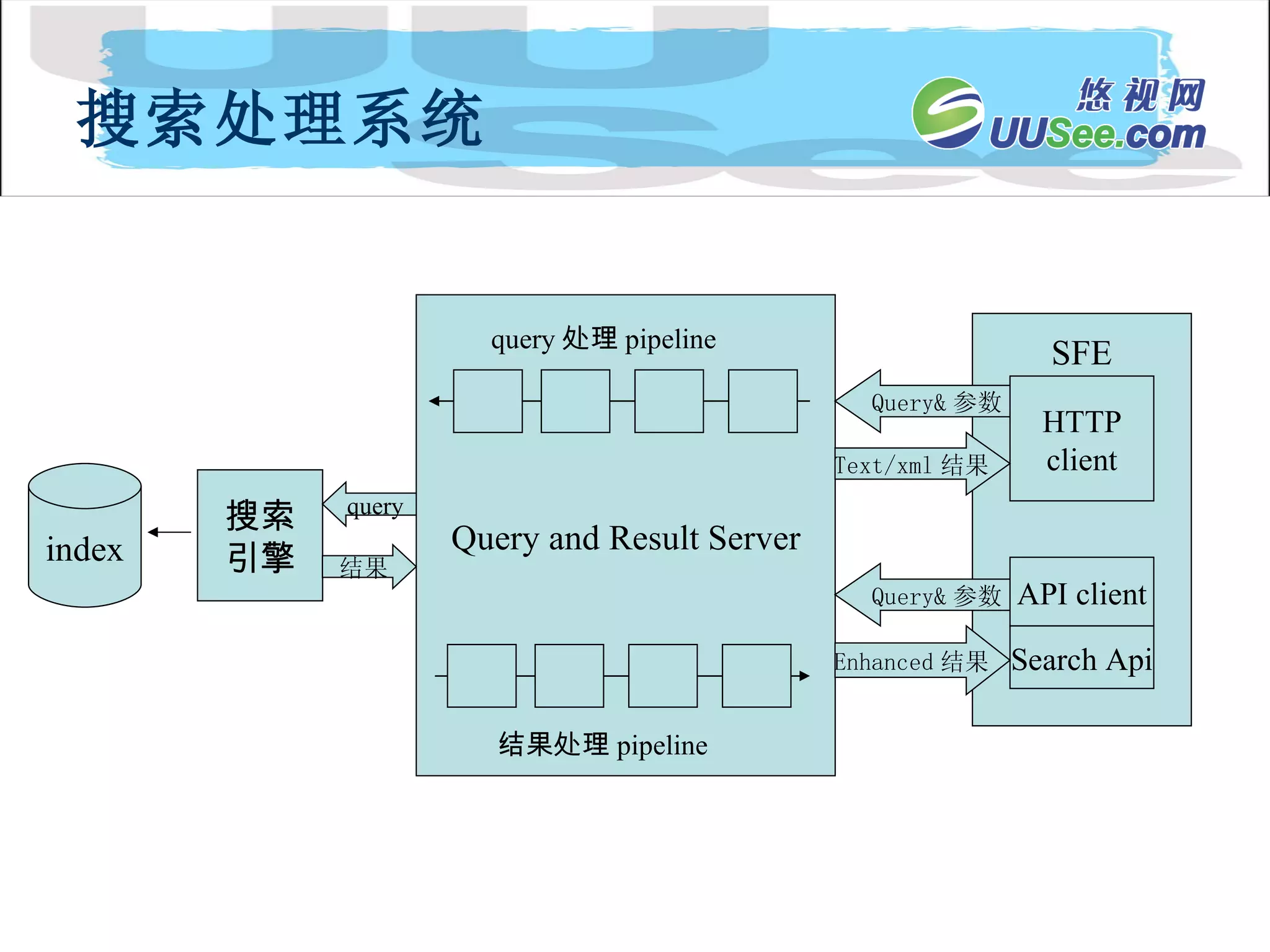
搜索处理系统 index 搜索引擎 SFE Search Api Query and Result Server query 结果 Query& 参数 Query& 参数 HTTP client Text/xml 结果 Enhanced 结果 API client 结果处理 pipeline query 处理 pipeline
相关术语 ( RelevancyTerminology ) For muli-term queries:the shorter the distance between query terms in a document,the higher the document’s rank value Proximity Importance of matching a query in a given document field Context Importance of geographical distance between a document’s associated latitude/longitude and a target location specified in a query Geo Assigned importance of a document , independent of the query Quality Importance of a document determined by the links to it from other documents Authority Age of a document compared to the time when the query is issued Freshness 描述 术语
36.
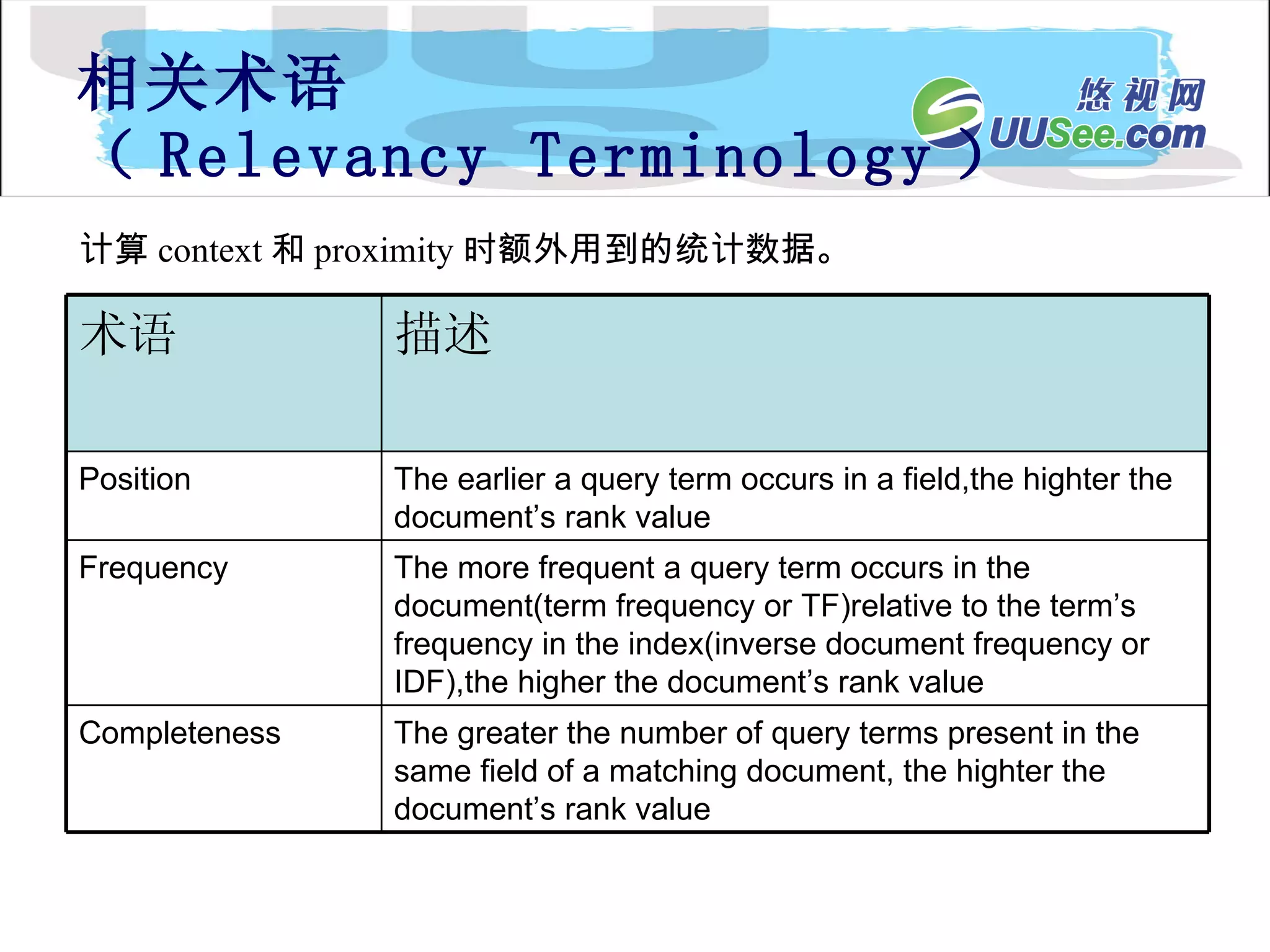
相关术语 ( RelevancyTerminology ) 计算 context 和 proximity 时额外用到的统计数据。 The greater the number of query terms present in the same field of a matching document, the highter the document’s rank value Completeness The more frequent a query term occurs in the document(term frequency or TF)relative to the term’s frequency in the index(inverse document frequency or IDF),the higher the document’s rank value Frequency The earlier a query term occurs in a field,the highter the document’s rank value Position 描述 术语
37.
相关算法 ( RelevancyFormula ) R(d,q)=S(d)+F(d,T)+D(d,q) R=query q 在 document d 中的 rank 值 S=document d 的静态 rank 值,与 query 无关 F=freshness of document d at time t D=dynamic rank
相关算法 ( RelevancyFormula ) R(d,q)=S(d)+F(d,T)+D(d,q) (w_freshness/100)*fn(time scale,document age) w_freshness freshness 的权重 Document age = current time – document time 单位:分钟
40.
相关算法 ( RelevancyFormula ) R(d,q)=S(d)+F(d,T)+D(d,q) 单 term 的 query (Fn(FO)+fn(NO)+W_authority/100*fn(ExtNO)+single_boost*W_context/100*sum(W_fieldN/100)) /fn(num_matching_docs) Fn(FO)-- 基础是 query term 在文档中第一次出现的位置 fn(NO)-- 基础是 query term 在文档中出现的次数 W_authority—authority 的权重 fn(ExtNO)— 在 authority 相关的 field 中出现的次数 single_boost— 单 term 时的 boost 系数 W_context---context 的权重 W_fieldN---context 中 field 的权重 fn(num_matching_docs)— 在单个搜索节点, term 在 document 中出现的总数
多节点体系 -admin 子系统Name service 和 License Manager 可以 fault tolerant 。 存在单点故障 其他组件不支持 fault tolerant CORBA Name Service License Manager Resource Service Log Transformer Log Server Config server Cache Manager Admin Server Relbench Storage service Web server
62.
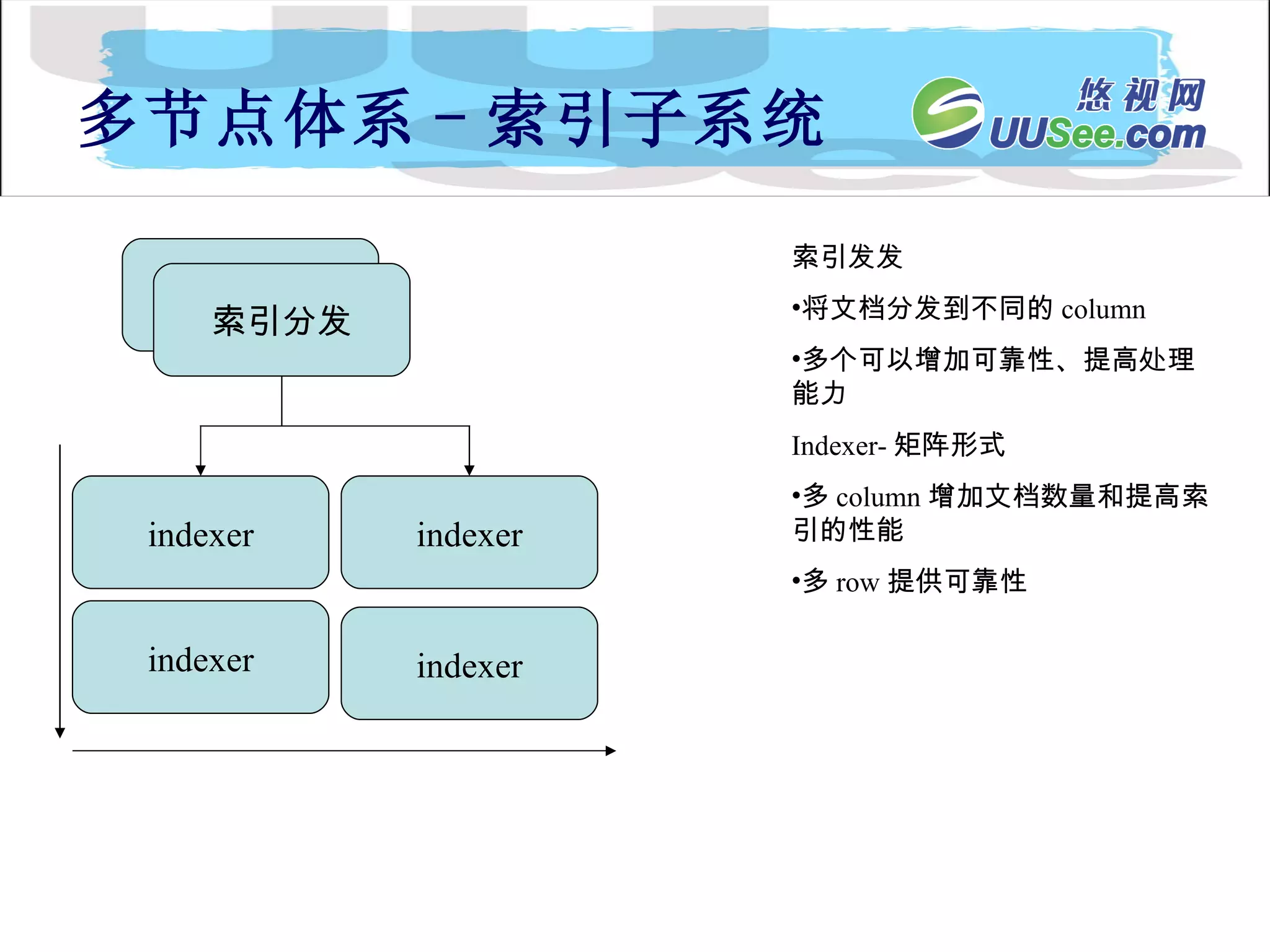
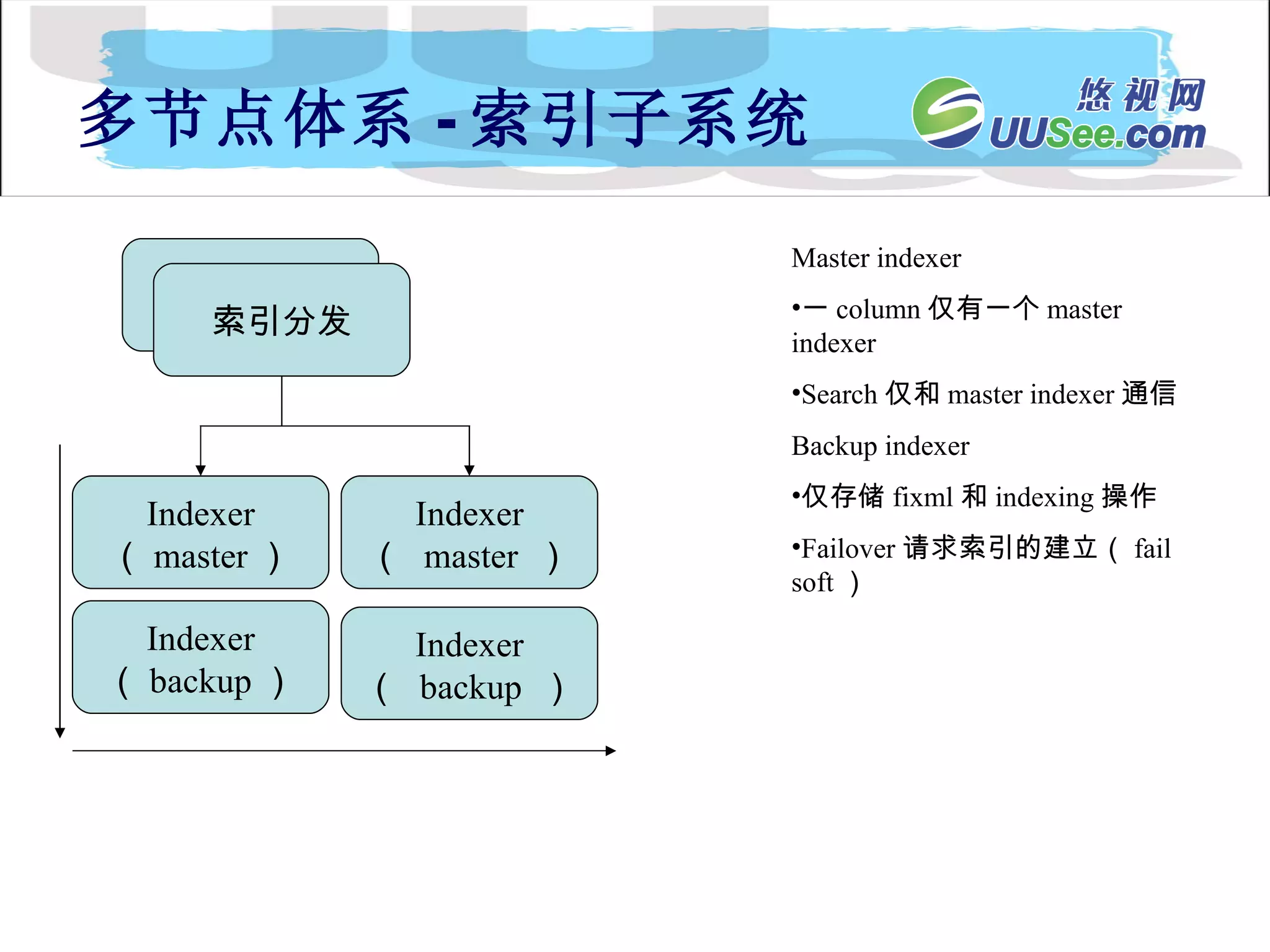
Index Partitions 机制每个 indexer 或 search 节点使用多个 indexing 的 partitions 每个 partition 容纳了索引的文档 Partitions are mirrored to permit incremental indexing and continuous search Content 被 index 进入最小的 partition Content 被合并到比较高的 partition 根据触发条件 0 1 2 docsDistributionPst : 100 , 100 , 100 触发条件: 10000 , 1000000 2 : 6










































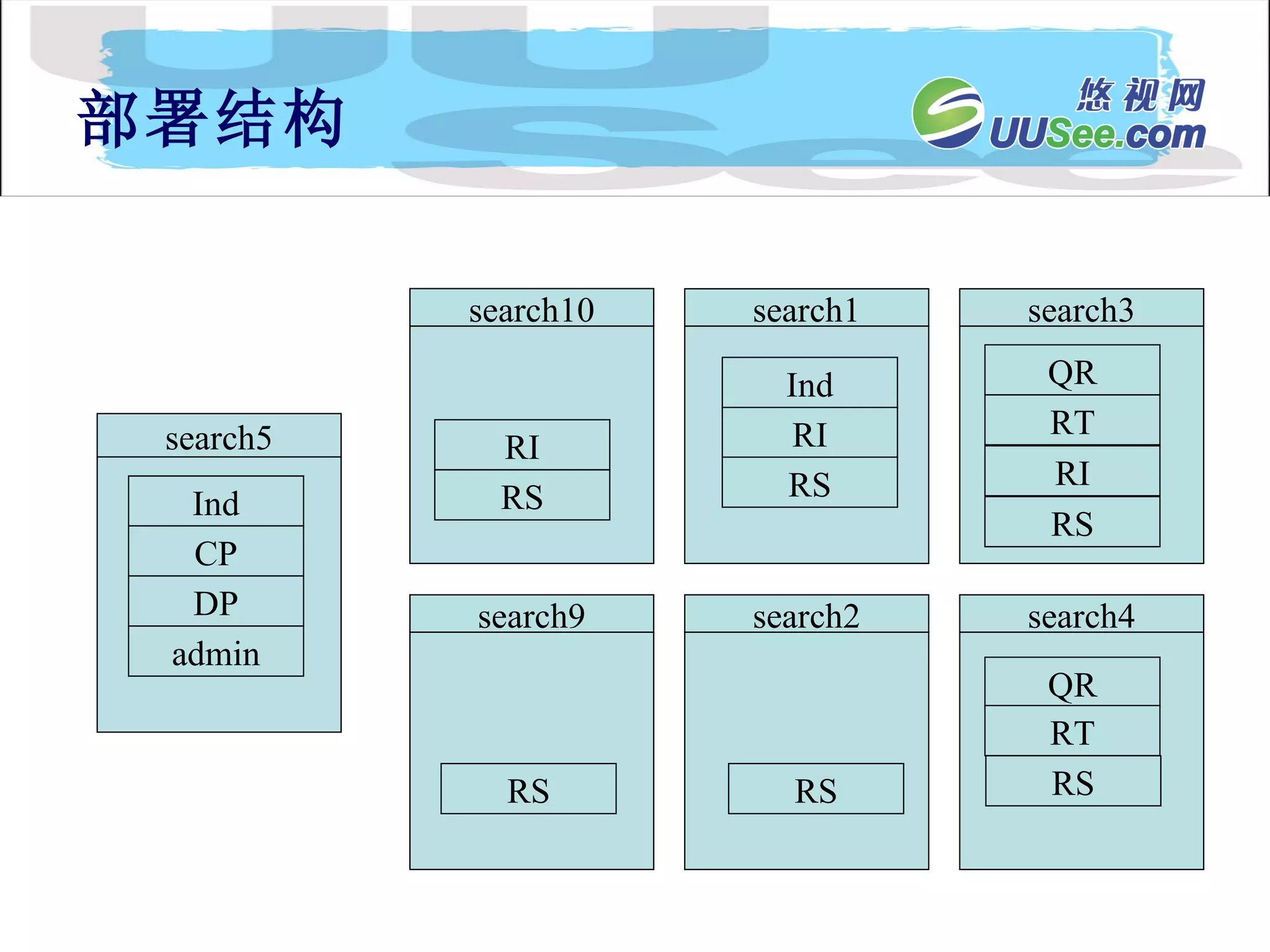
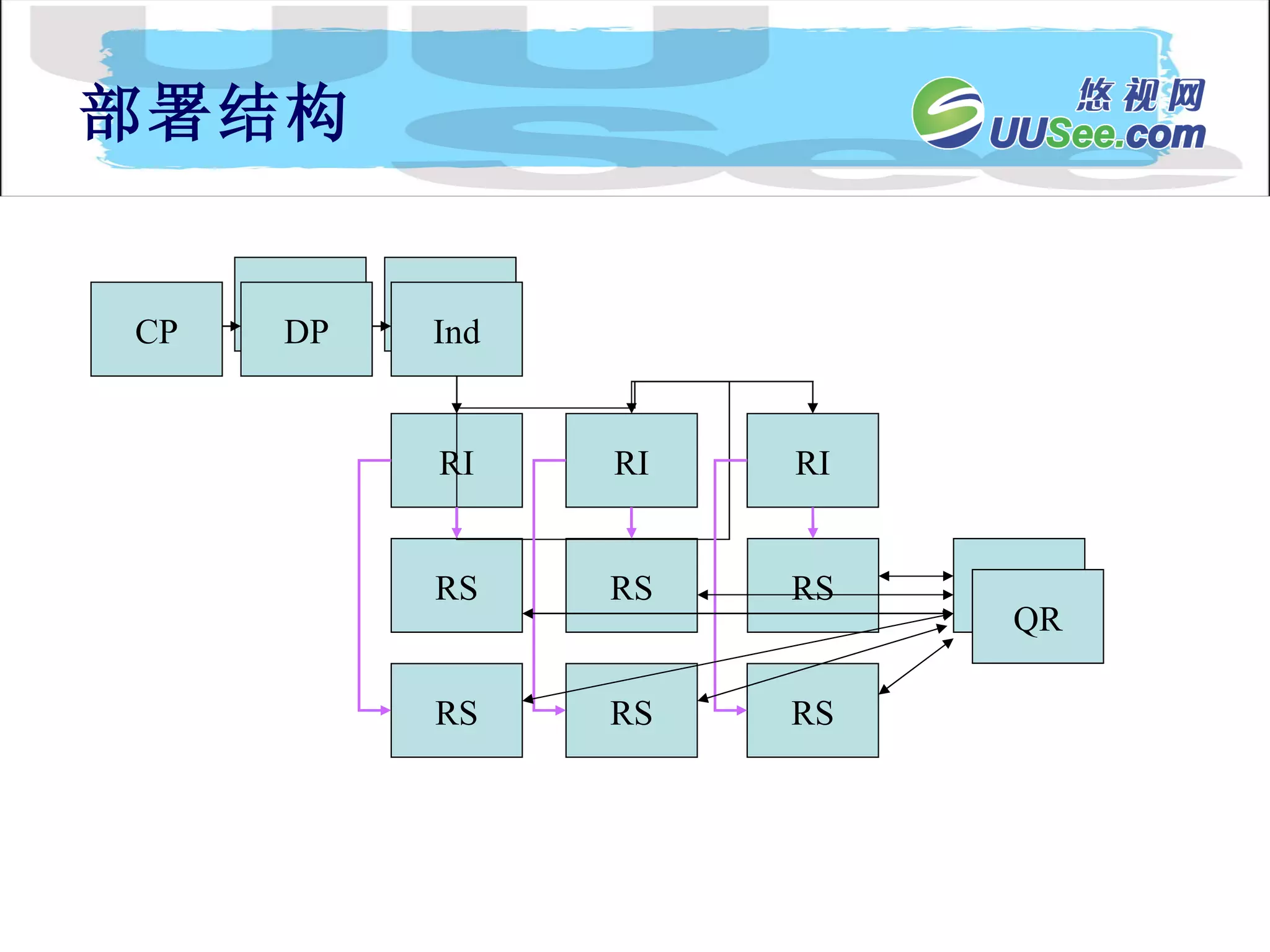

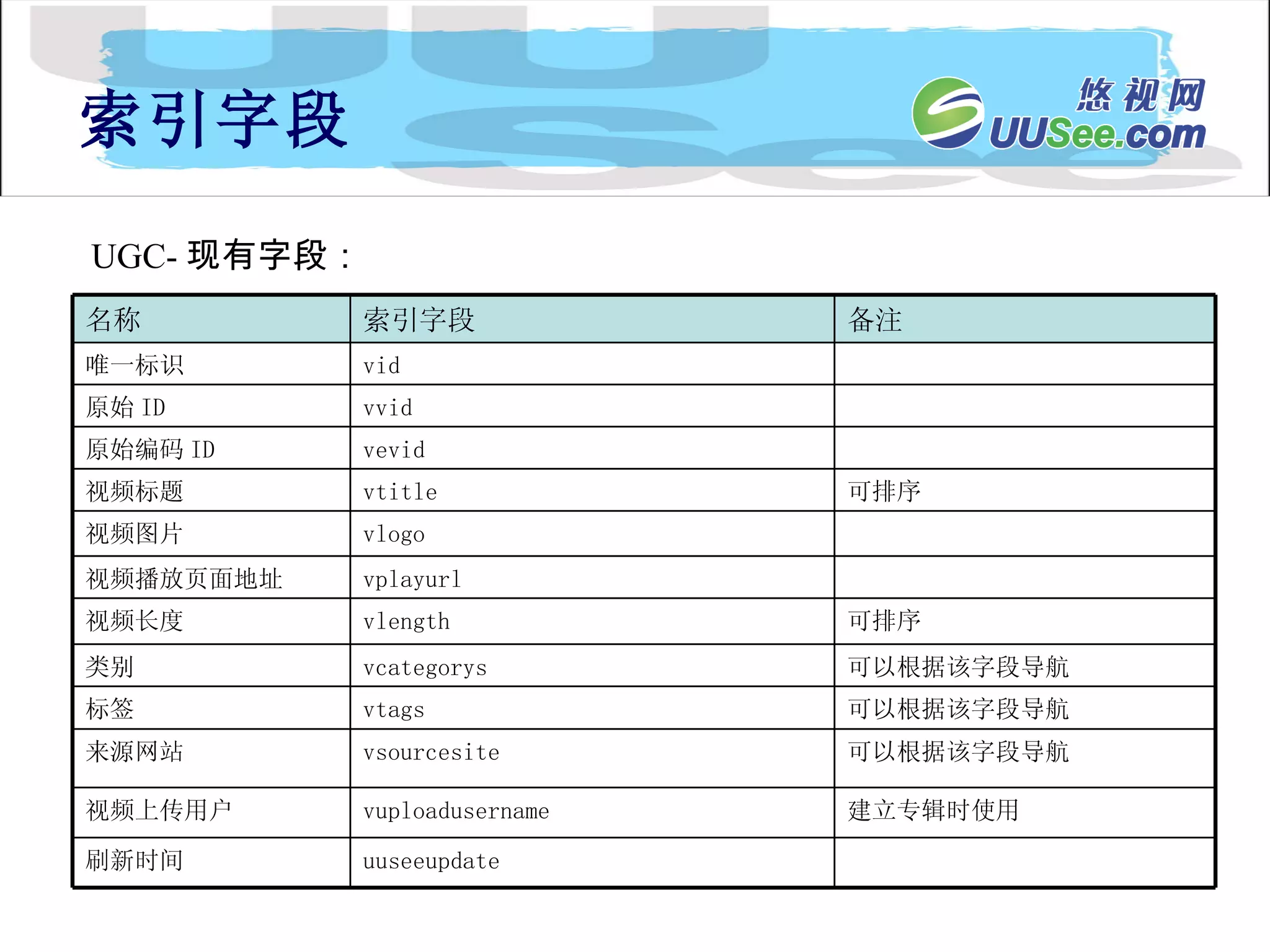
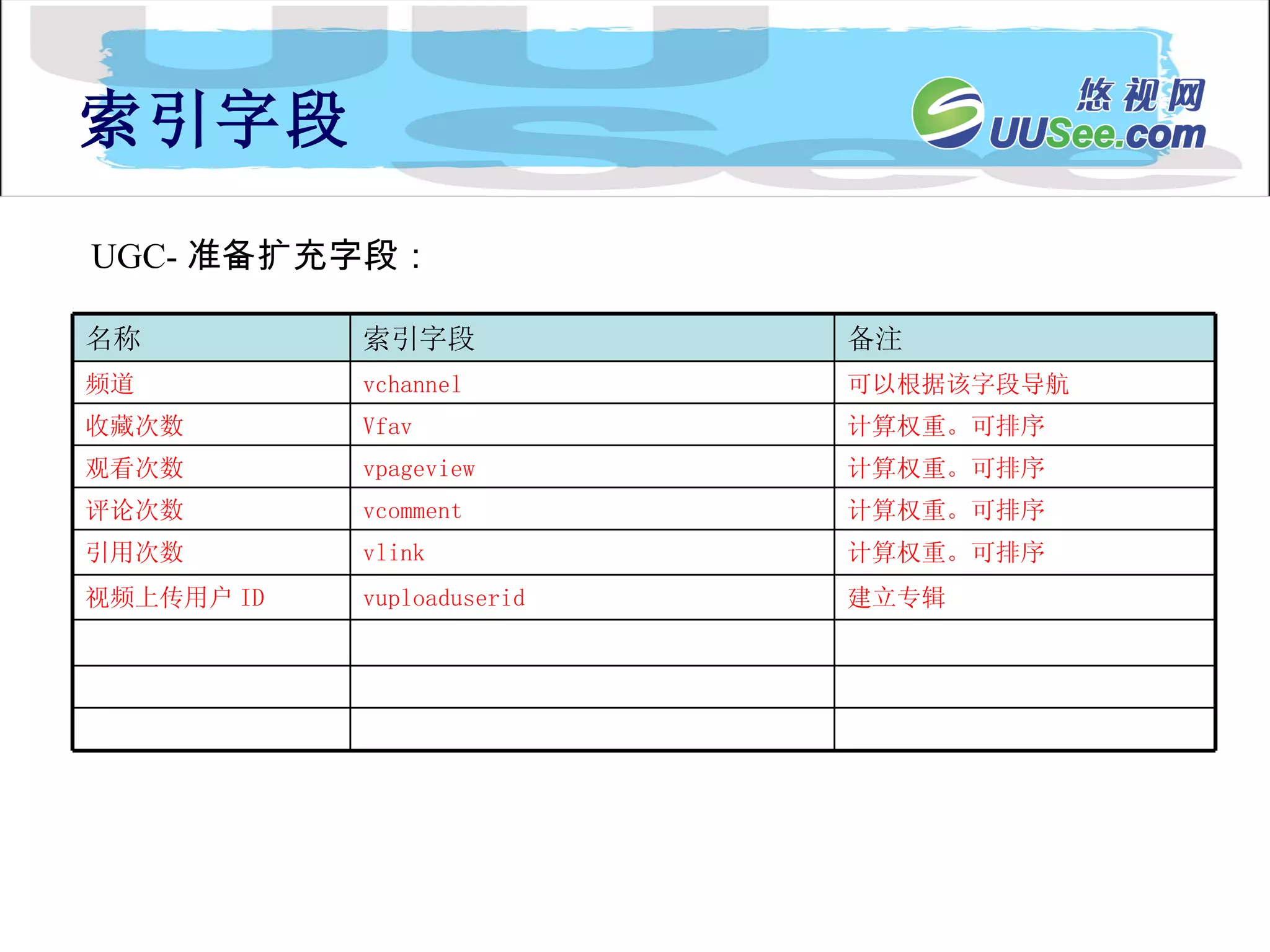



























![Lucene 3[1] 0 原理与代码分析](https://cdn.slidesharecdn.com/ss_thumbnails/lucene31-0-100225194736-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)