Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Neil Crosby
14,919 views
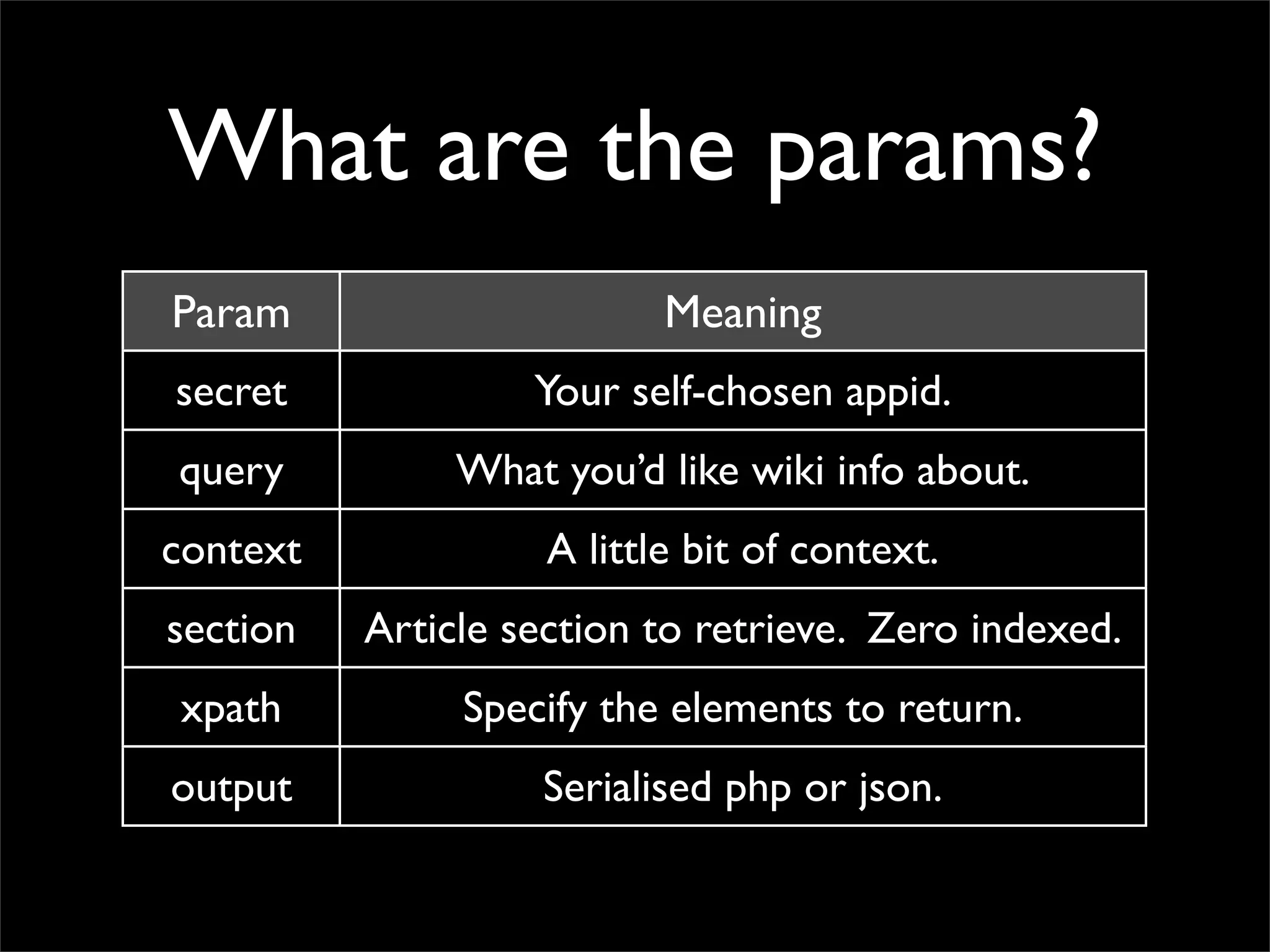
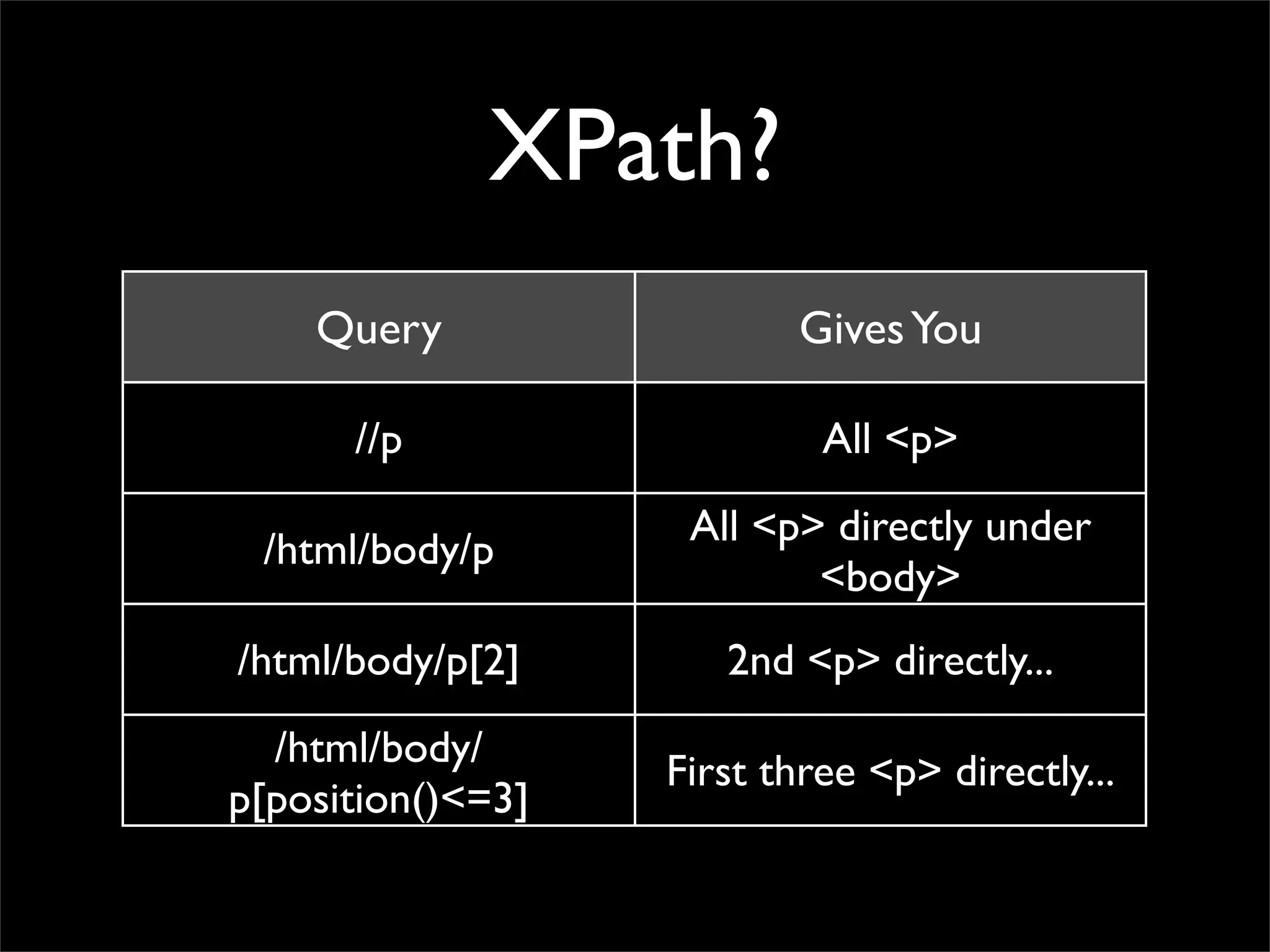
Mining Wikipedia For Awesome Data
Technology
◦
Read more
20
Save
Share
Embed
Embed presentation
Download
Downloaded 482 times
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
KEY
World Affairs Council, Wikipedia as global collaboration Feb 2010
by
Wikimedia Foundation
PPT
Wikipedia as an Ontology for Describing Documents
by
Zareen Syed
PPT
The Wikipedia Model
by
Frieda Brioschi
PPTX
Wikipedia
by
jonreigatemedia
PDF
State of the Word 2011
by
photomatt
PDF
team++; making your team work better together
by
Neil Crosby
ZIP
team++
by
Neil Crosby
ZIP
Geolocation and Beer
by
Neil Crosby
World Affairs Council, Wikipedia as global collaboration Feb 2010
by
Wikimedia Foundation
Wikipedia as an Ontology for Describing Documents
by
Zareen Syed
The Wikipedia Model
by
Frieda Brioschi
Wikipedia
by
jonreigatemedia
State of the Word 2011
by
photomatt
team++; making your team work better together
by
Neil Crosby
team++
by
Neil Crosby
Geolocation and Beer
by
Neil Crosby
More from Neil Crosby
ZIP
Lagging Pipes
by
Neil Crosby
PPT
Yahoo! Pipes: Munging, Mixing and Mashing
by
Neil Crosby
PDF
Search Monkey - Open Hack London '09
by
Neil Crosby
ZIP
Automated Frontend Testing
by
Neil Crosby
PDF
I'll Show You Mine If You Show Me Yours...
by
Neil Crosby
PPT
TV Tubes - Talkin' 'bout my automation...
by
Neil Crosby
PPT
Starting to Monkey Around With Yahoo! Search Monkey
by
Neil Crosby
PPT
Multi-level vCards
by
Neil Crosby
PPT
Twitter Bots
by
Neil Crosby
Lagging Pipes
by
Neil Crosby
Yahoo! Pipes: Munging, Mixing and Mashing
by
Neil Crosby
Search Monkey - Open Hack London '09
by
Neil Crosby
Automated Frontend Testing
by
Neil Crosby
I'll Show You Mine If You Show Me Yours...
by
Neil Crosby
TV Tubes - Talkin' 'bout my automation...
by
Neil Crosby
Starting to Monkey Around With Yahoo! Search Monkey
by
Neil Crosby
Multi-level vCards
by
Neil Crosby
Twitter Bots
by
Neil Crosby
Recently uploaded
PPTX
Cybersecurity Best Practices - Step by Step guidelines
by
Yasir Naveed Riaz
PDF
TrustArc Webinar - Looking Ahead: The 2026 Privacy Landscape
by
TrustArc
PPTX
Software Analysis &Design ethiopia chap-2.pptx
by
Abbas484771
PPTX
Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]
by
UiPathCommunity
PDF
Unser Jahresrückblick – MarvelClient in 2025
by
panagenda
PDF
Lab 1.5 - Sharing Secrets with GPG ~ 2nd Sight Lab Cloud Security Class
by
2nd Sight Lab
PPTX
communication-skills-with-technology tools
by
Jaleto Sunkemo
PPTX
Why Most GenAI Projects Fail to Scale and How to Become One of the Success St...
by
Earley Information Science
PDF
Our Digital Tribe_ Cultivating Connection and Growth in Our Slack Community 🌿...
by
sanjeetmishra30
PDF
Real-Time Data Insight Using Microsoft Forms for Business
by
Elevate
PDF
Eredità digitale sugli smartphone: cosa resta di noi nei dispositivi mobili
by
Speck&Tech
PDF
Six Shifts For 2026 (And The Next Six Years)
by
David Armano
PPTX
Unit-4-ARTIFICIAL NEURAL NETWORKS.pptx ANN ppt Artificial neural network
by
ssuserd4481a
PDF
Data Virtualization in Action: Scaling APIs and Apps with FME
by
Safe Software
PDF
The major tech developments for 2026 by Pluralsight, a research and training ...
by
Chris Skinner
PPTX
Building Cyber Resilience for 2026: Best Practices for a Secure, AI-Driven Bu...
by
Yasir Naveed Riaz
PPTX
Protecting Data in an AI Driven World - Cybersecurity in 2026
by
Yasir Naveed Riaz
PPTX
Cybercrime in the Digital Age: Risks, Impact & Protection
by
Yasir Naveed Riaz
PDF
Energy Storage Landscape Clean Energy Ministerial
by
SurajitBanerjee38
PPT
software-security-intro in information security.ppt
by
ismaeelsahib032
Cybersecurity Best Practices - Step by Step guidelines
by
Yasir Naveed Riaz
TrustArc Webinar - Looking Ahead: The 2026 Privacy Landscape
by
TrustArc
Software Analysis &Design ethiopia chap-2.pptx
by
Abbas484771
Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]
by
UiPathCommunity
Unser Jahresrückblick – MarvelClient in 2025
by
panagenda
Lab 1.5 - Sharing Secrets with GPG ~ 2nd Sight Lab Cloud Security Class
by
2nd Sight Lab
communication-skills-with-technology tools
by
Jaleto Sunkemo
Why Most GenAI Projects Fail to Scale and How to Become One of the Success St...
by
Earley Information Science
Our Digital Tribe_ Cultivating Connection and Growth in Our Slack Community 🌿...
by
sanjeetmishra30
Real-Time Data Insight Using Microsoft Forms for Business
by
Elevate
Eredità digitale sugli smartphone: cosa resta di noi nei dispositivi mobili
by
Speck&Tech
Six Shifts For 2026 (And The Next Six Years)
by
David Armano
Unit-4-ARTIFICIAL NEURAL NETWORKS.pptx ANN ppt Artificial neural network
by
ssuserd4481a
Data Virtualization in Action: Scaling APIs and Apps with FME
by
Safe Software
The major tech developments for 2026 by Pluralsight, a research and training ...
by
Chris Skinner
Building Cyber Resilience for 2026: Best Practices for a Secure, AI-Driven Bu...
by
Yasir Naveed Riaz
Protecting Data in an AI Driven World - Cybersecurity in 2026
by
Yasir Naveed Riaz
Cybercrime in the Digital Age: Risks, Impact & Protection
by
Yasir Naveed Riaz
Energy Storage Landscape Clean Energy Ministerial
by
SurajitBanerjee38
software-security-intro in information security.ppt
by
ismaeelsahib032
Download


















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














