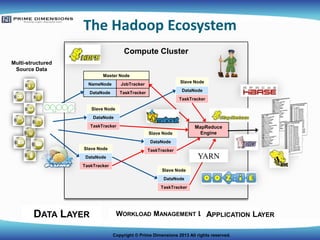
Hadoop is an Apache Open Source project that provides a framework that allows for the distributed processing of large data sets across clusters of computers, each offering local computation and storage. Based on Google File System and MapReduce papers.Hadoop scales out to large clusters of servers (nodes) using the Hadoop Distributed File System (HDFS) to manage huge data sets and spread them across the servers.Hadoop’sdisributed architecture as a Big Data platform allows MapReduce programs to run in parallel across 10s to 1000s of servers, or nodes.MapReduce is a general-purpose execution engine that handles the complexities of parallel programming for a wide variety of applicationsThe Map phase, for computation or analysis applied to a set of input key/value pairs to produce a set of intermediate key/value pairsThe Reduce phase, in which the set of values associated with the intermediate key/value pairs output by the Map phase are combined (that is, “reduced”) to provide the results.More on MapReduce later…We have seen that Hadoop also augments Data Warehouse environments. Hadoop is becoming a critical part of many modern information technology (IT) departments. It is being used for a growing range of requirements, including analytics, data storage, data processing, and shared compute resources. As Hadoop’s significance grows, it is important that it be treated as a component of your larger IT organization, and managed as one. Hadoop is no longer relegated to only research projects, and should be managed as your agency would manage any other large component of your IT infrastructure.A multi-node Hadoop clusterA small Hadoop cluster will include a single master and multiple slave nodes. The master node consists of a JobTracker, TaskTracker, NameNode and DataNode. A slave node acts as both a DataNode and TaskTracker, though it is possible to have data-only worker nodes and compute-only worker nodes. These are normally used only in nonstandard applications.[13]Hadoop requires Java Runtime Environment (JRE) 1.6 or higher. In a larger cluster, the HDFS is managed through a dedicated NameNode server to host the file system index, and Similarly, a standalone JobTracker server can manage job scheduling. HADOOP—THE FOUNDATION FOR CHANGEHadoop has the potential to reach beyond Big Data to catalyze new levels of business productivity and transformation. As the foundation for change in business, Hadoop represents an unprecedented opportunity to improve how organizations can get the most value from large amounts of data. Businesses that rely on Hadoop as the core of their infrastructure can not only do analytics on top of vast amounts of data, but can also go beyond analytics and the foundation for that data layer to build applications that are meaningful, and that have a very tightly coupled relationship with the data. Consumer Internet companies have reaped the benefits of this approach, and EMC believes more traditional enterprises will adopt the same model as they evolve and transform their businesses.Hadoop has rapidly emerged as the preferred solution for Big Data analytics applications that grapple with vast repositories of unstructured data. It is flexible, scalable, inexpensive, fault-tolerant, and enjoys rapid adoption rates and a rich ecosystem surrounded by massive investment. However, customers face high hurdles to broadly adopting Hadoop as their singular data repository due to a lack of useful interfaces and high-level tooling for Business Intelligence and datamining—components that are critical to data analytics and building a data-driven enterprise. As the world's first true SQL processing for Hadoop, Pivotal HD addresses these challenges. THE HADOOP ECOSYSTEM The Hadoop family of products includes the Hadoop Distributed File System (HDFS), MapReduce, Pig, Hive, HBase, Mahout, Lucene, Oozie, Flume, Cassandra, YARN, Ambari, Avro, Chukwa, and Zookeeper. Pivtoalhd: HDFS, MapReduce, Hive, Mahout, Pig, HBase, Yarn, Zookeeper, Sqoop and FlumeHDFS A distributed file system that partitions large files across multiple machines for high-throughput access to dataData LayerFlume: Flume is a framework for populating Hadoop with data. Agents are populated throughout ones IT infrastructure – inside web servers, application servers and mobile devices, for example – to collect data and integrate it into Hadoop.Flume: Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows.Sqoop: Sqoop is a connectivity tool for moving data from non-Hadoop data stores – such as relational databases and data warehouses – into Hadoop. It allows users to specify the target location inside of Hadoop and instruct Sqoop to move data from Oracle, Teradata or other relational databases to the target. HCatalog: HCatalog is a centralized metadata management and sharing service for Apache Hadoop. It allows for a unified view of all data in Hadoop clusters and allows diverse tools, including Pig and Hive, to process any data elements without needing to know physically where in the cluster the data is stored. Workload Management LayerMapReduceA programming framework for distributed batch processing of large data sets distributed across multiple serversMapReduce, which is typically used to analyze web logs on hundreds, sometimes thousands of web application servers without moving the data into a data warehouse, is not a database system, but is a parallel and distributed programming model for analyzing massive data sets (“big data”). One elegant aspect of the MapReduce is its simplicity, mostly due to its dependence on two basic operations that are applied to sets or lists of data value pairs:The Map phase, for computation or analysis applied to a set of input key/value pairs to produce a set of intermediate key/value pairs, andThe Reduce phase, in which the set of values associated with the intermediate key/value pairs output by the Map phase are combined (that is, “reduced”) to provide the results. MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.Typically the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster. ZooKeeperis a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them ,which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed. Oozie is a workflow scheduler system to coordinate and manage Apache Hadoop jobs.Oozieis integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts).Oozie: Oozie is a workflow processing system that lets users define a series of jobs written in multiple languages – such as Map Reduce, Pig and Hive -- then intelligently link them to one another. Oozie allows users to specify, for example, that a particular query is only to be initiated after specified previous jobs on which it relies for data are completed. Mahout: Scalable to reasonably large data sets. Mahout also provides Java libraries for common math (focused on linear algebra and statistics) operations and primitive Java collections. Mahout is a work in progress; the number of implemented algorithms has grown quickly,[3] but there are still various algorithms missing.While Mahout's core algorithms for clustering, classification and batch based collaborative filtering are implemented on top of Apache Hadoop using the map/reduce paradigm, it does not restrict contributions to Hadoop based implementationsMahout: Mahout is a scalable machine learning and data mining library. It takes the most popular data mining algorithms for performing clustering, regression testing and statistical modeling and implements them using the Map Reduce model. Application LayerApache Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets. At the present time, Pig's infrastructure layer consists of a compiler that produces sequences of Map-Reduce programs, for which large-scale parallel implementations already exist (e.g., the Hadoop subproject). Pig's language layer currently consists of a textual language called Pig Latin, which has the following key properties:Pig [1] is a high-level platform for creating MapReduce programs used with Hadoop. The language for this platform is called Pig Latin.[1] Pig Latin abstracts the programming from the Java MapReduce idiom into a notation which makes MapReduce programming high level, similar to that of SQL for RDBMS systems. Pig Latin can be extended using UDF (User Defined Functions) which the user can write in Java, Python, JavaScript, Ruby or Groovy [2] and then call directly from the language. PigA high-level data-flow language for expressing Map/Reduce programs for analyzing large HDFS distributed data setsPig was originally [3] developed at Yahoo Research around 2006 for researchers to have an ad-hoc way of creating and executing map-reduce jobs on very large data sets. In 2007,[4] it was moved into the Apache Software Foundation.[5] Apache HBase™ is the Hadoop database, a distributed, scalable, big data store. Use Apache HBase when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, column-oriented store modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.HBase: HBase is a non-relational database that allows for low-latency, quick lookups in Hadoop. It adds transactional capabilities to Hadoop, allowing users to conduct updates, inserts and deletes. EBay and Facebook use HBase heavily.HBaseAn open-source, distributed, versioned, column-oriented store modelled after Google’s BigtableHive: Hive is a data warehouse system for Hadoop that facilitates easy data summarization, ad-hoc queries, and the analysis of large datasets stored in Hadoop compatible file systems. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL. Hive: Hive is a Hadoop-based data warehousing-like framework originally developed by Facebook. It allows users to write queries in a SQL-like language caledHiveQL, which are then converted to MapReduce. This allows SQL programmers with no MapReduce experience to use the warehouse and makes it easier to integrate with business intelligence and visualization tools such as Microstrategy, Tableau, Revolutions Analytics, etc.HiveA data warehouse system for Hadoop that facilitates data summarization, ad-hoc queries, and the analysis of large datasets stored in Hadoop compatible file systems. Hive provides a mechanism to project structure onto this data and query it using a SQL-like language called HiveQL. HiveQL programs are converted into Map/Reduce programsCluster Sizing The sizing guide for HDFS is very simple: each file has a default replication factor of 3 and you need to leave approximately 25% of the disk space for intermediate shuffle files. So you need 4x times the raw size of the data you will store in the HDFS. However, the files are rarely stored uncompressed and, depending on the file content and the compression algorithm, on average we have seen a compression ratio of up to 10-20 for the text files stored in HDFS. So the actual raw disk space required is only about 30-50% of the original uncompressed size. Compression also helps in moving the data between different systems, e.g. Teradata and Hadoop.MemoryMemory demand for a master node is based on the NameNode data structures that grow with the storage capacity of your cluster. We found 1 GB per petabyte of storage is a good guideline for master node memory. You then need to add on your OS overhead,etc. We have found that with Intel Sandybridge processors 32GB is more than enough memory for a master node.Cluster Design TradeoffsWe classify clusters as small (around 2-3 racks), medium(4-10 racks) and large(above 10 racks). What we have been covering so far are design guidelines and part of the design process is to understand how to bend the design guidelines to meet you goals. In the case of small, medium and large clusters things get progressively more stringent and sensitive when you bend the guidelines. For a small the smaller number of slave nodes allow you greater flexibility in your decisions. There are a few guidelines you don’t want to violate like isolation. When you get to a medium size cluster the number of nodes will increase your design sensitivity. You also now have enough hardware the physical plant issues of cooling and power become more important. Your interconnects also become more important. At the large scale things become really sensitive and you have to be careful because making a mistake here could result in a design that will fail. Our experience at Hortonworks has allowed us to develop expertise in this area and we strongly recommend you work with us if you want to build Internet scale clusters. detailed and specific on what a typical slave node for Hadoop should be: Mid-range processor4 to 32 GB memory1 GbE network connection to each node, with a 10 GbE top-of-rack switchA dedicated switching infrastructure to avoid Hadoop saturating the network4 to 12 drives (cores) per machine, Non-RAIDEach node has 8 cores, 16G RAM and 1.4T storage.FacebookWe use Hadoop to store copies of internal log and dimension data sources and use it as a source for reporting/analytics and machine learning.Currently we have 2 major clusters:A 1100-machine cluster with 8800 cores and about 12 PB raw storage.A 300-machine cluster with 2400 cores and about 3 PB raw storage.Each (commodity) node has 8 cores and 12 TB of storage. Yahoo now manages more than 42,000 Hadoop nodes.(2011)Yahoo!More than 100,000 cores in >40,00 nodes running HadoopOur biggest cluster: 4500 nodes (2*4cpu boxes w 4*1TB disk & 16GB RAM)
MapReduce is a general-purpose execution engine that handles the complexities of parallel programming for a wide variety of applicationsThe Map phase, for computation or analysis applied to a set of input key/value pairs to produce a set of intermediate key/value pairsThe Reduce phase, in which the set of values associated with the intermediate key/value pairs output by the Map phase are combined (that is, “reduced”) to provide the results.YARN: Apache Hadoop NextGenMapReduce (YARN)MapReduce has undergone a complete overhaul in hadoop-0.23 and we now have, what we call, MapReduce 2.0 (MRv2) or YARN.The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker, resource management and job scheduling/monitoring, into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job in the classical sense of Map-Reduce jobs or a DAG of jobs.The ResourceManager and per-node slave, the NodeManager (NM), form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system.The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.As folks are aware, Hadoop HDFS is the data storage layer for Hadoop and MapReduce was the data-processing layer. However, the MapReduce algorithm, by itself, isn’t sufficient for the very wide variety of use-cases we see Hadoop being employed to solve. With YARN, Hadoop now has a generic resource-management and distributed application framework, where by, one can implement multiple data processing applications customized for the task at hand. Hadoop MapReduce is now one such application for YARN and I see several others given my vantage point – in future you will see MPI, graph-processing, simple services etc.; all co-existing with MapReduce applications in a Hadoop YARN cluster.