Download as KEY, PPTX












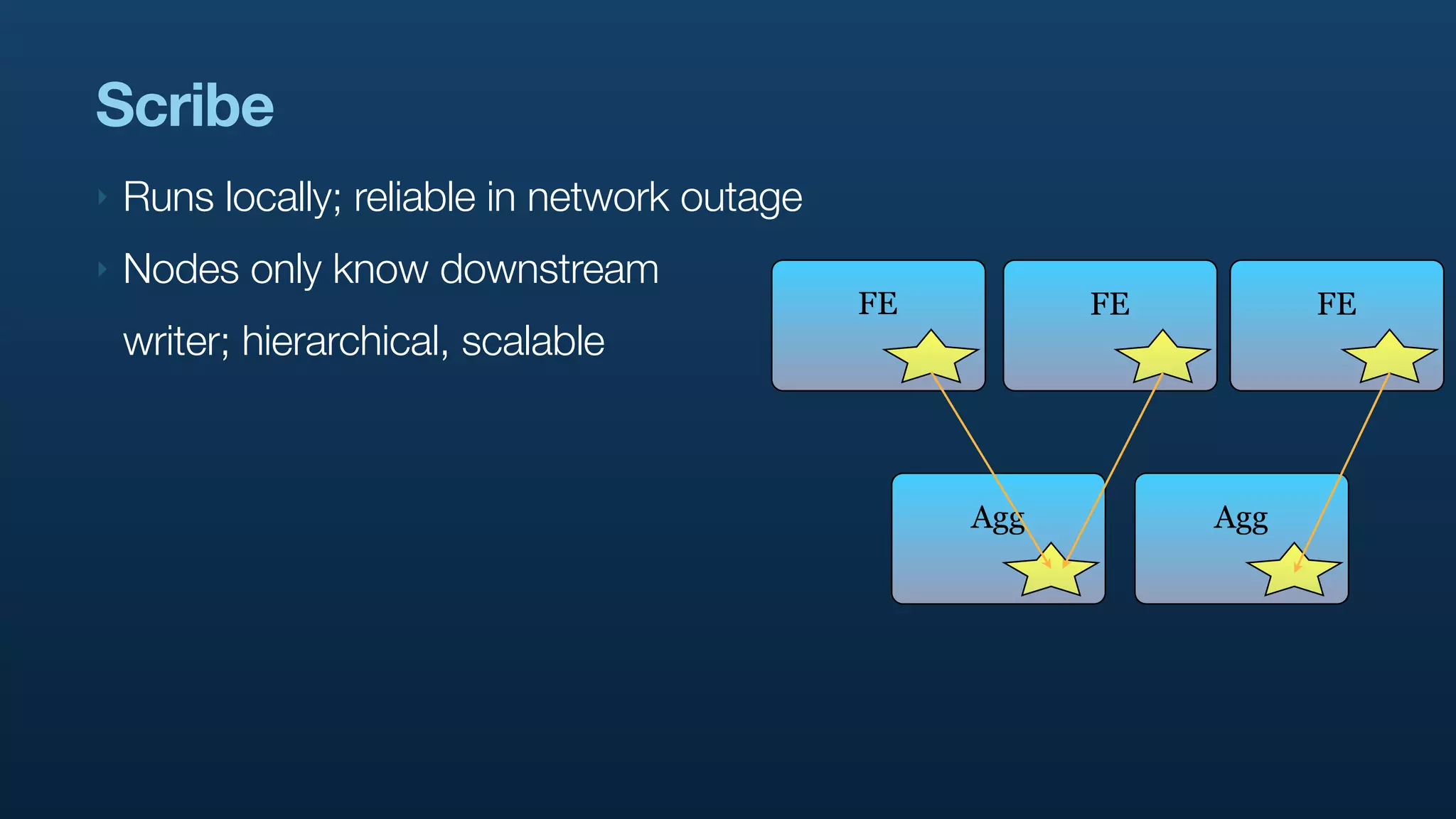
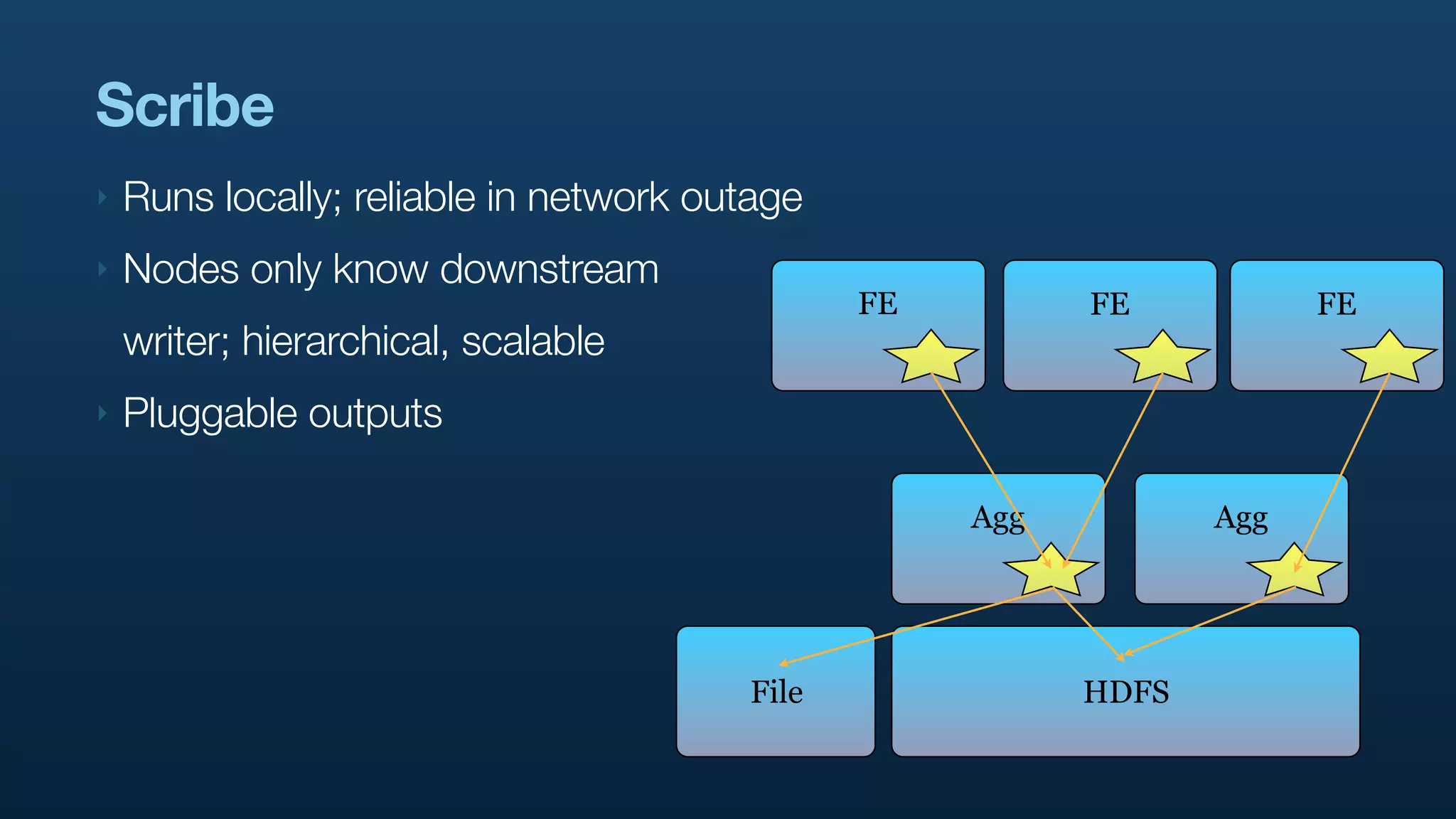












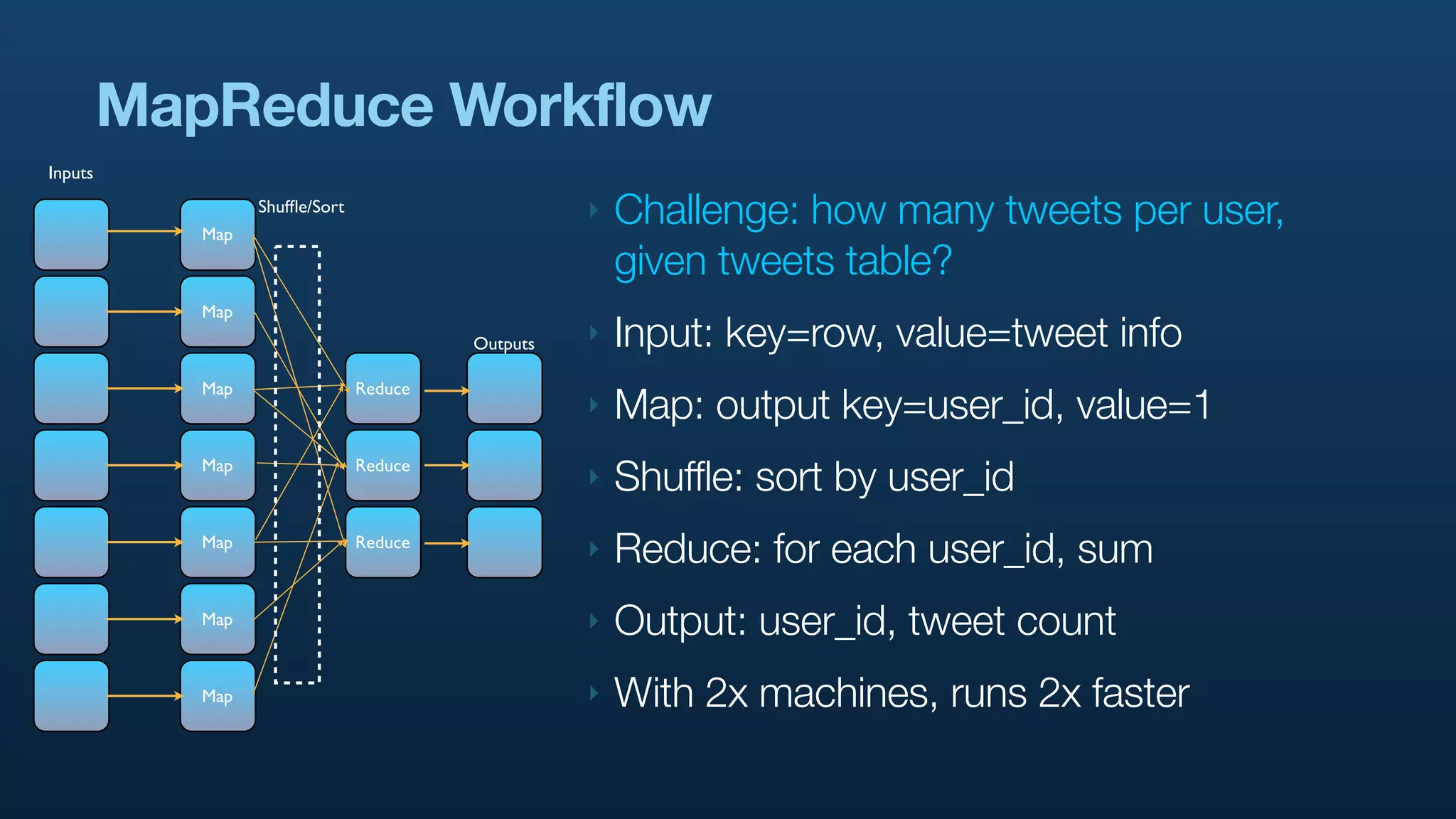
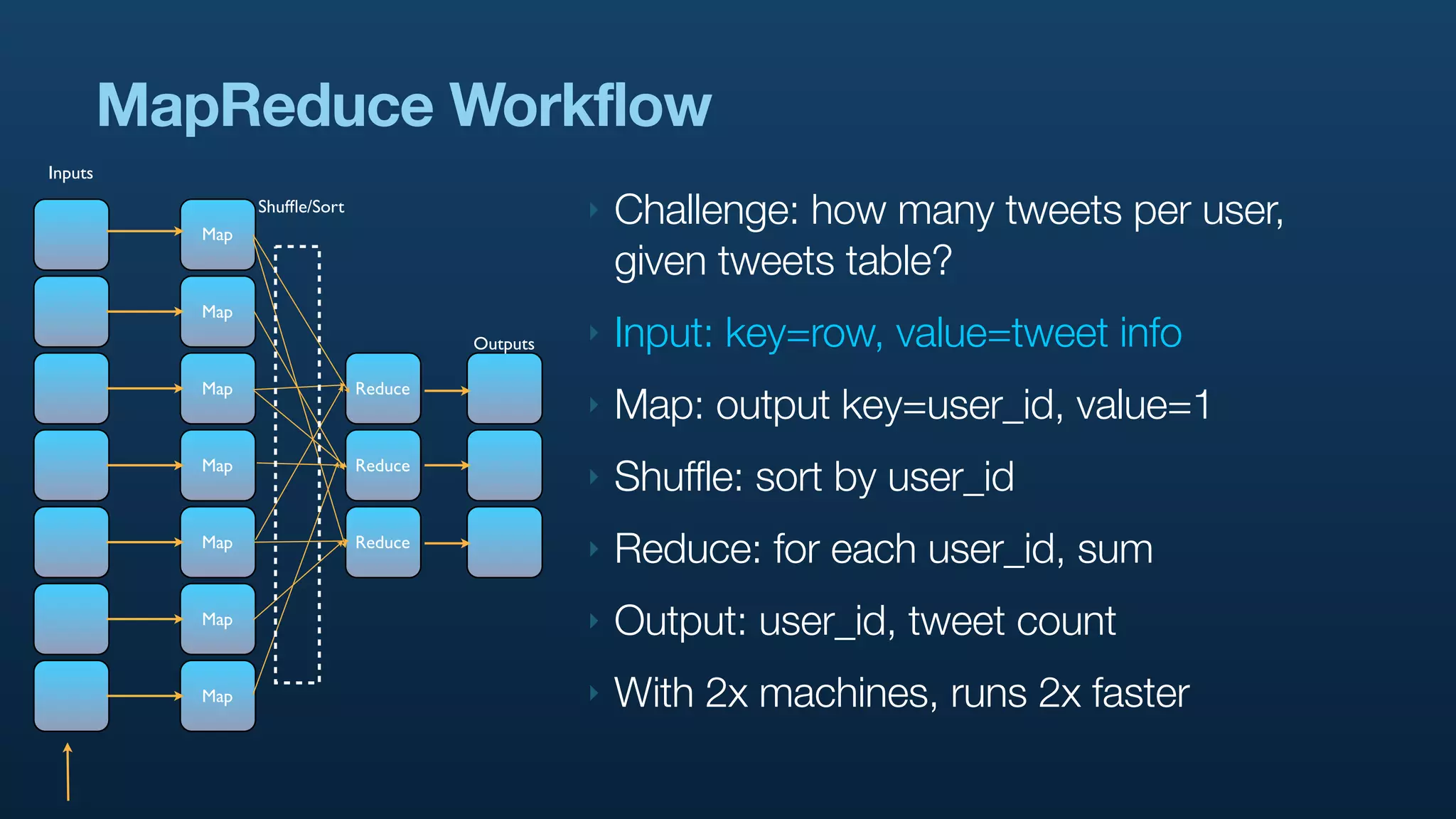
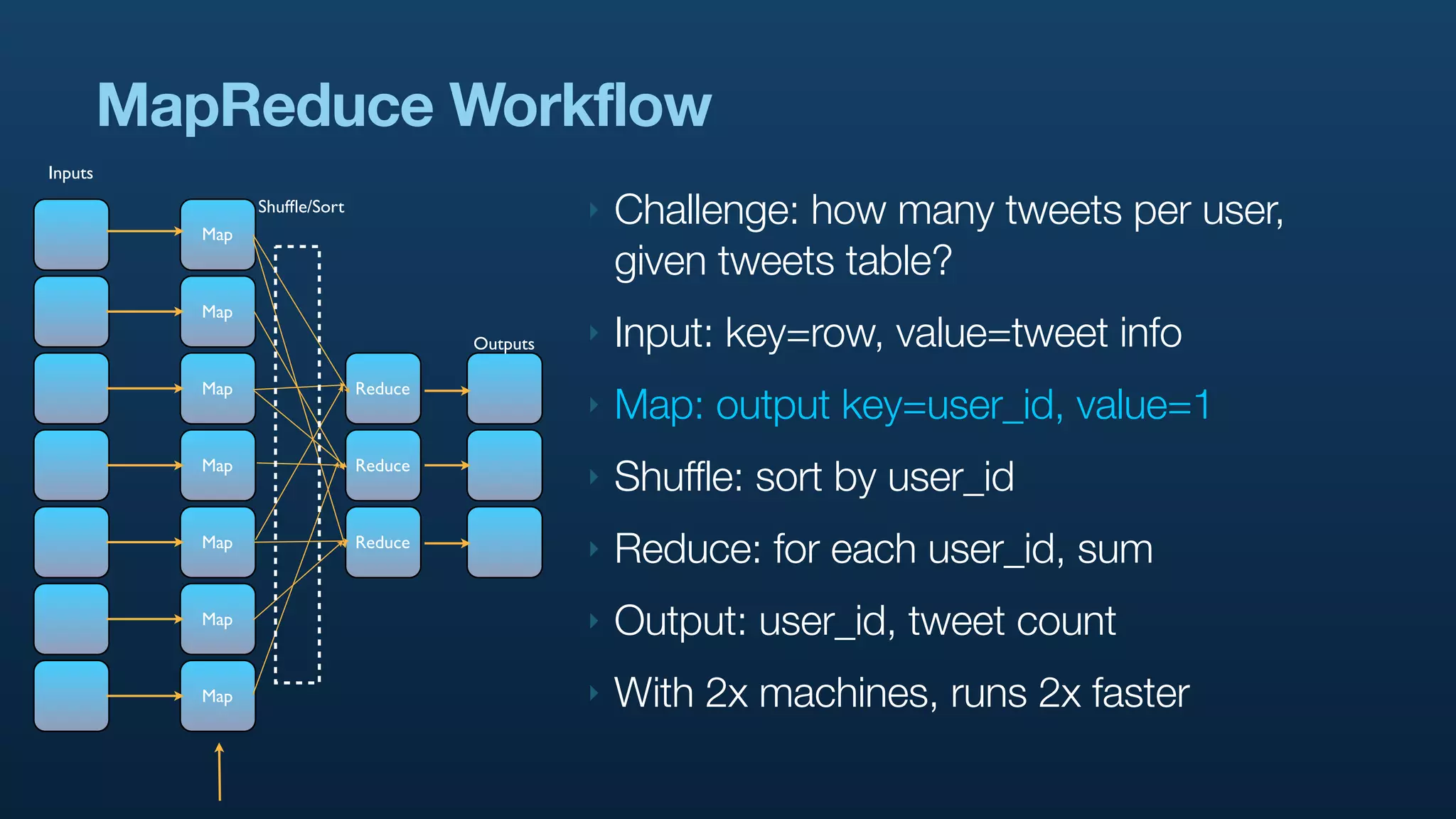
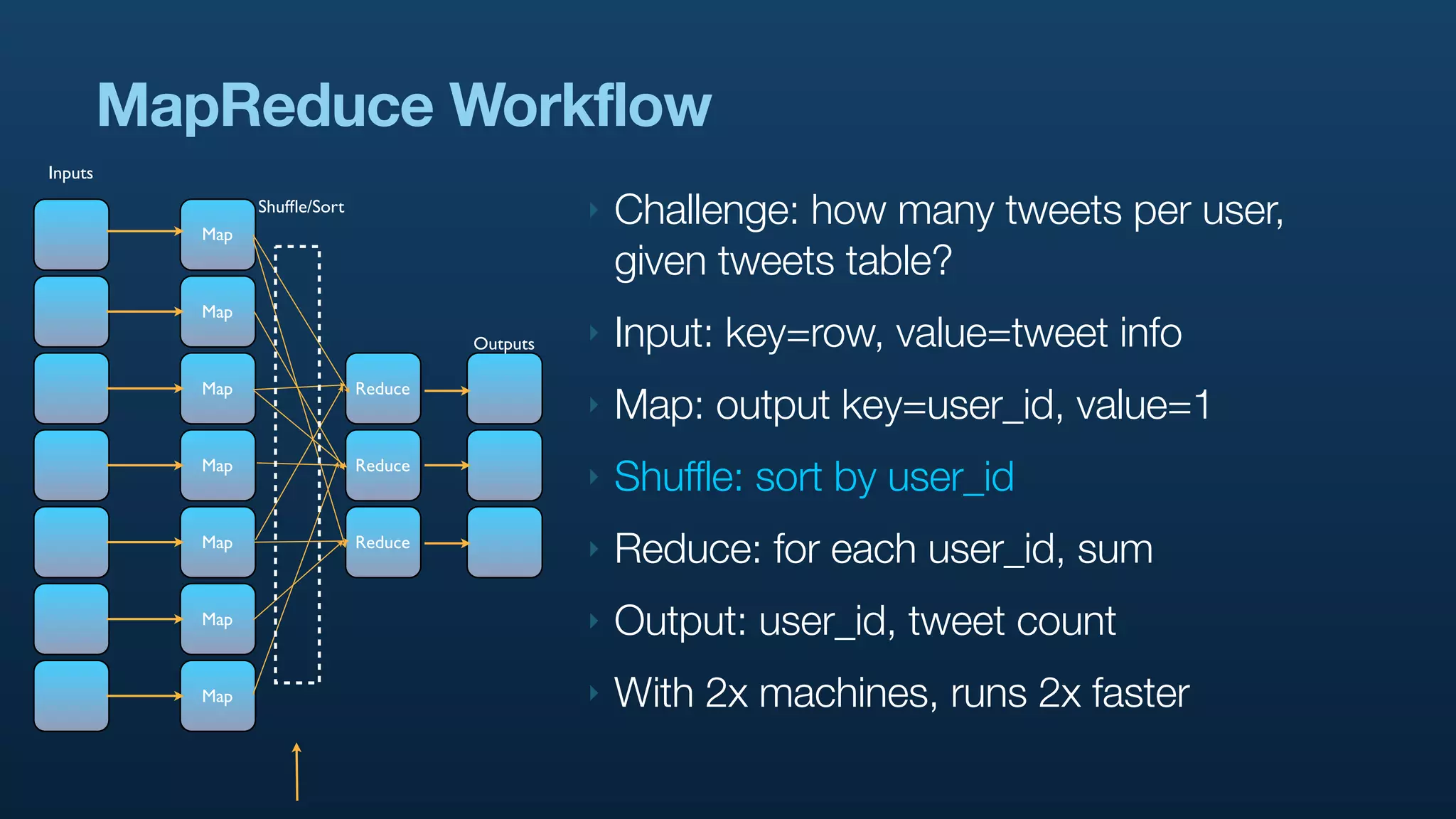
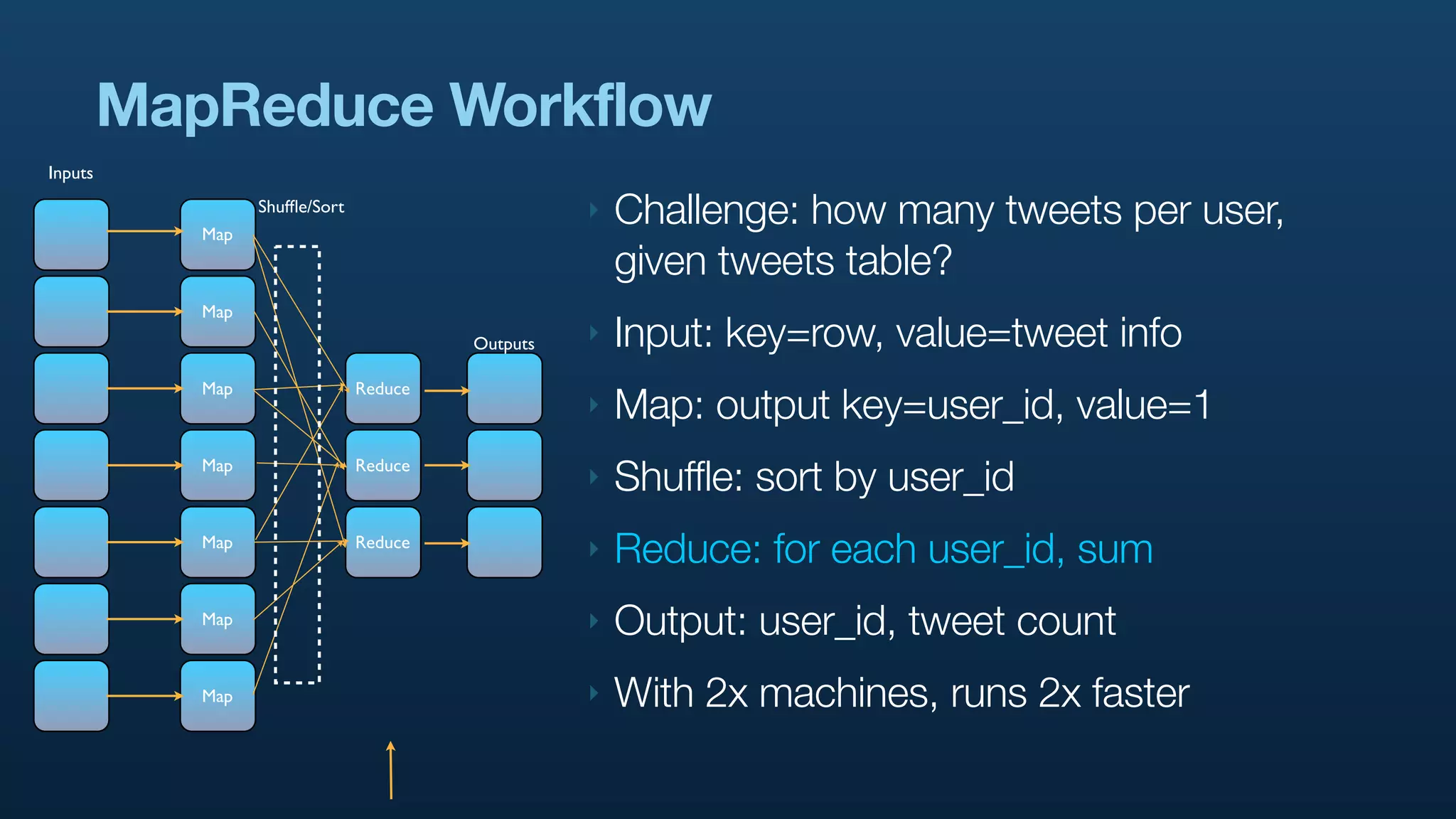
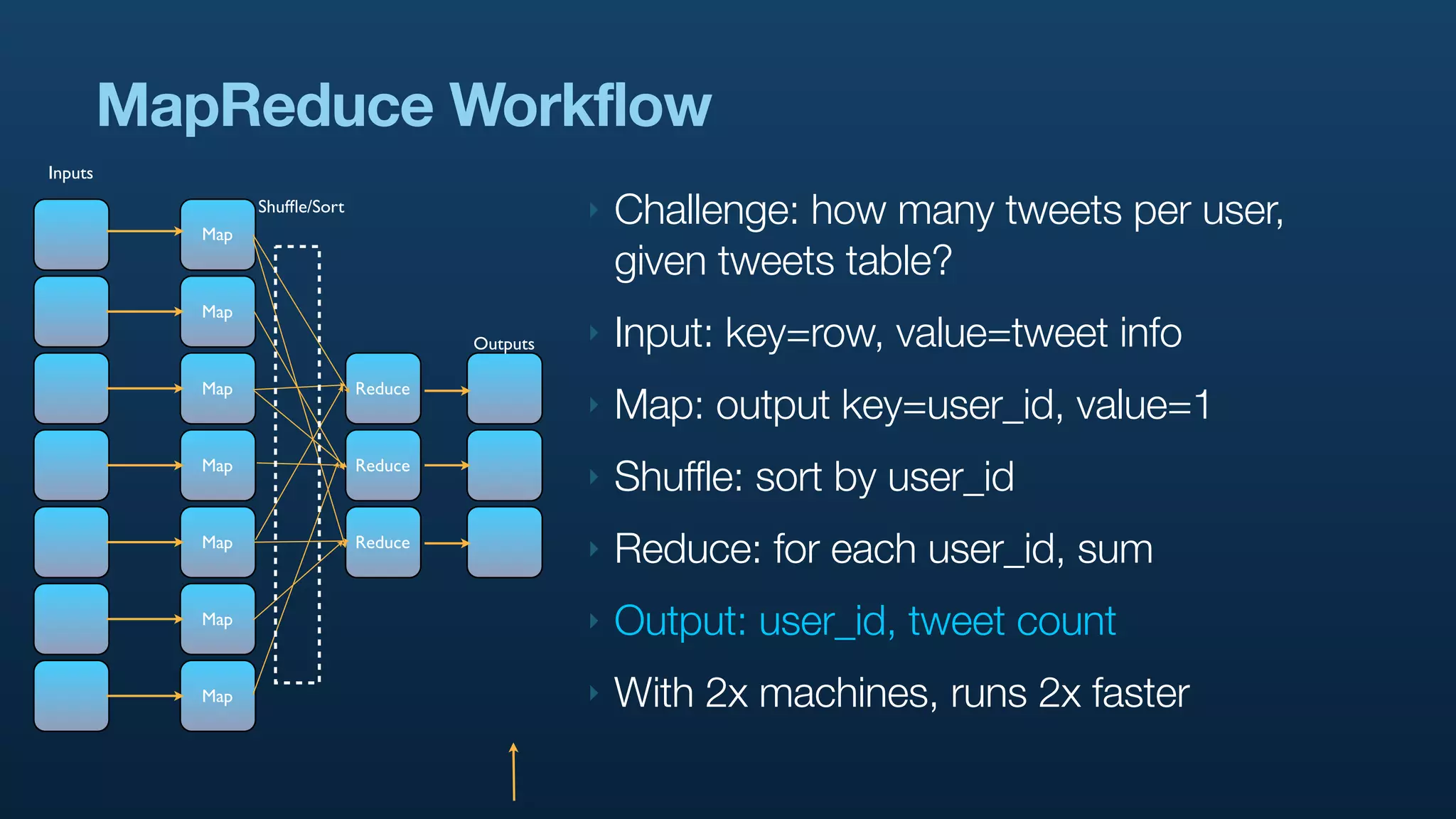
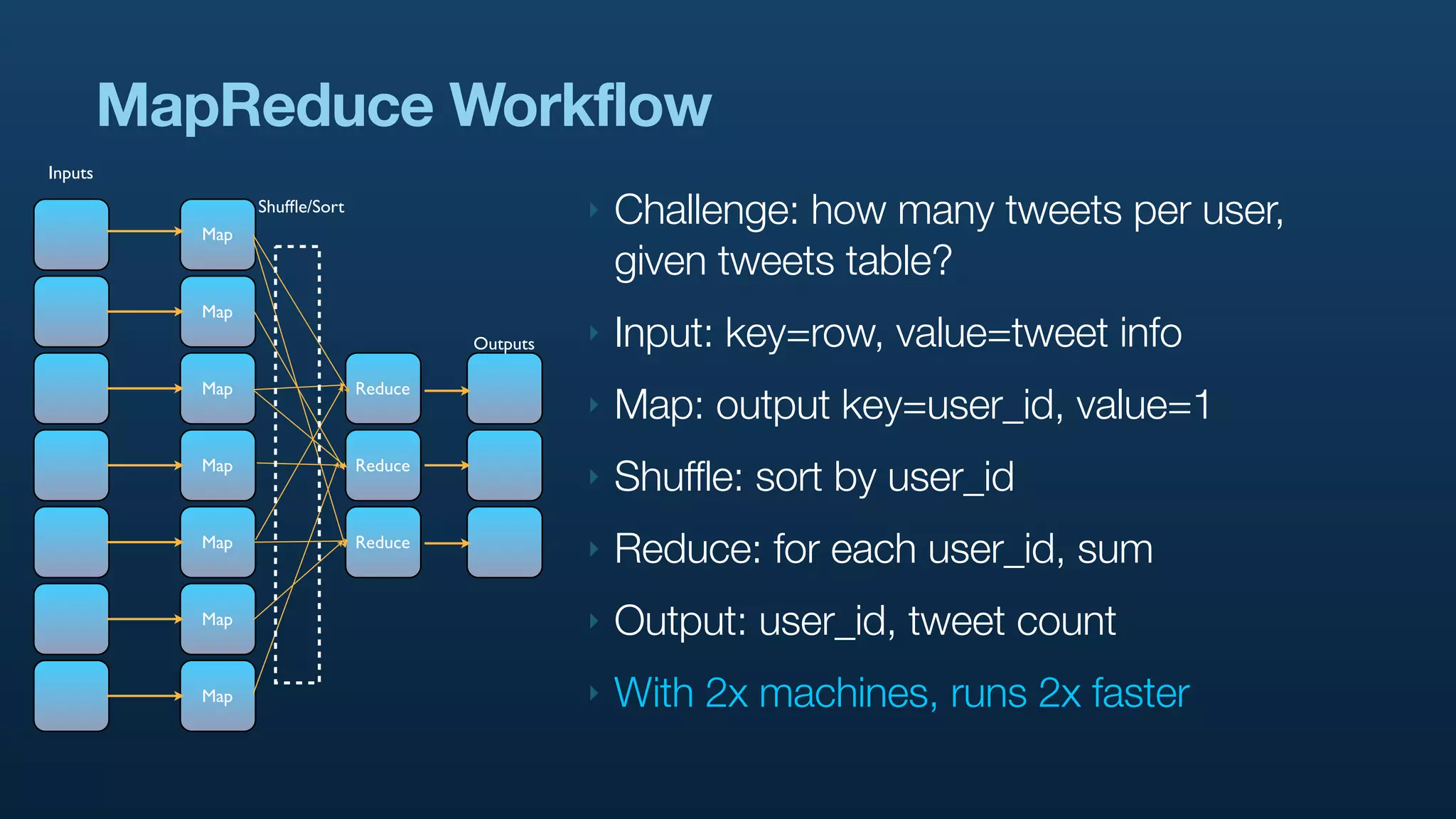
















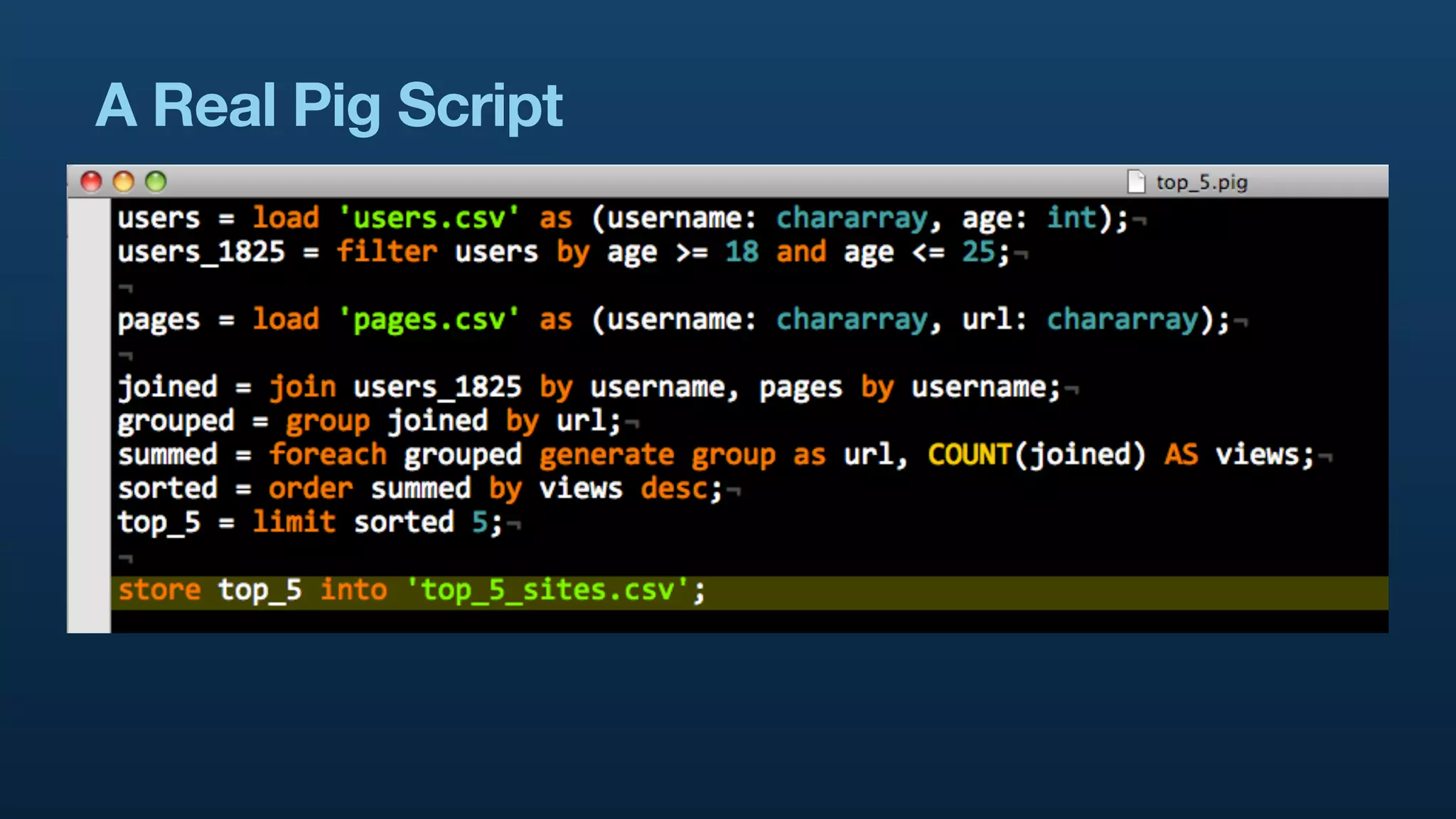
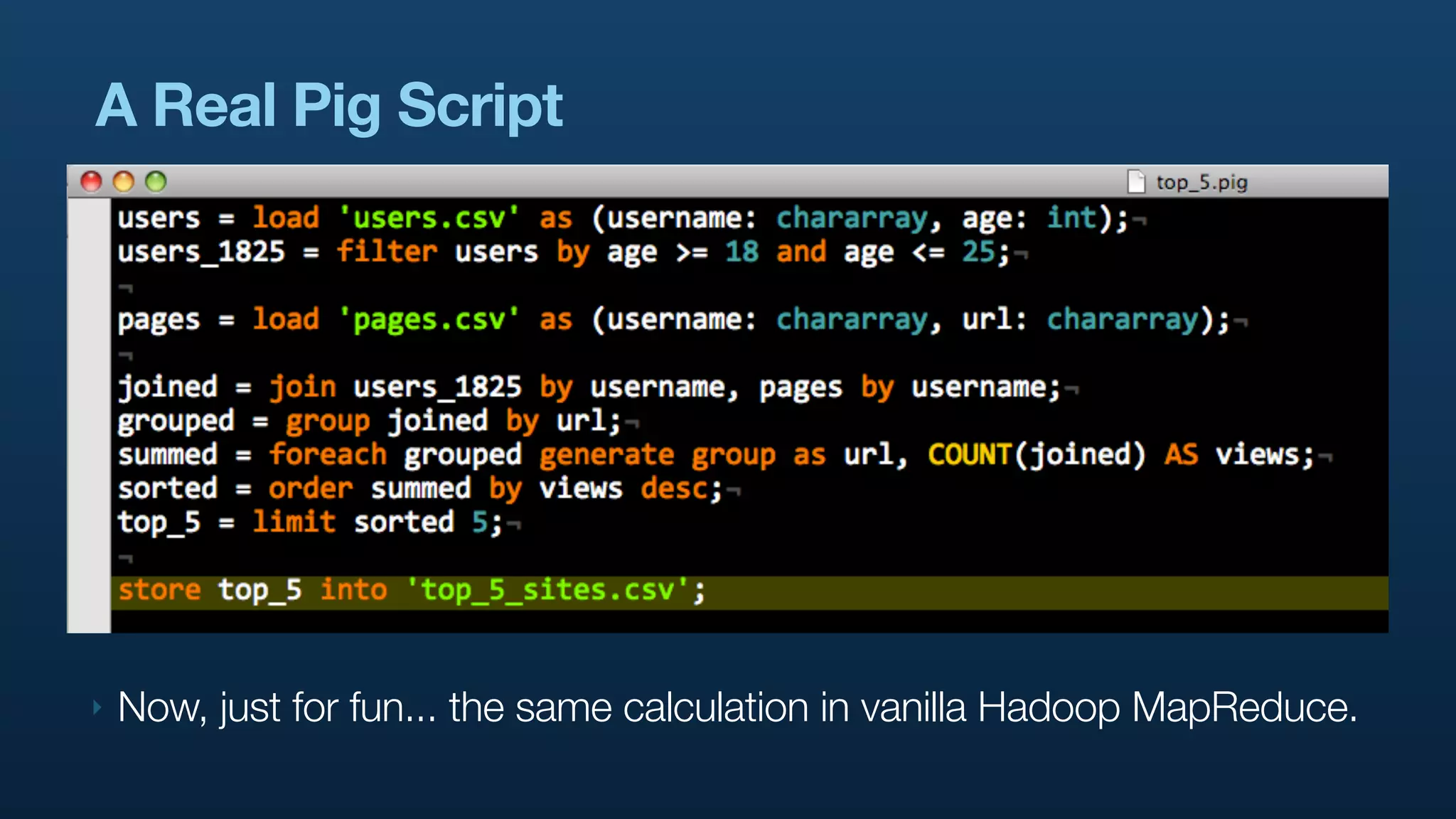































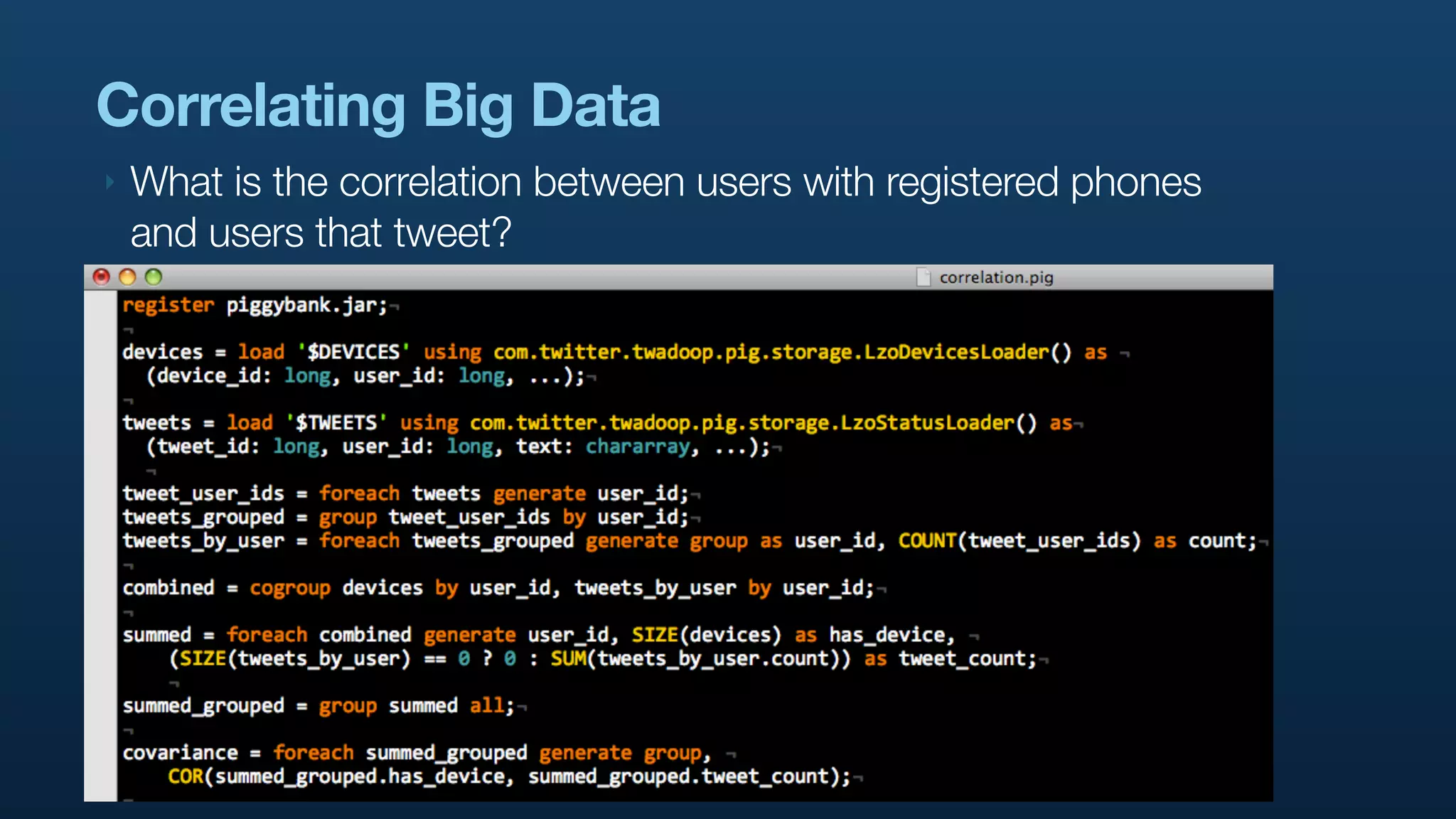













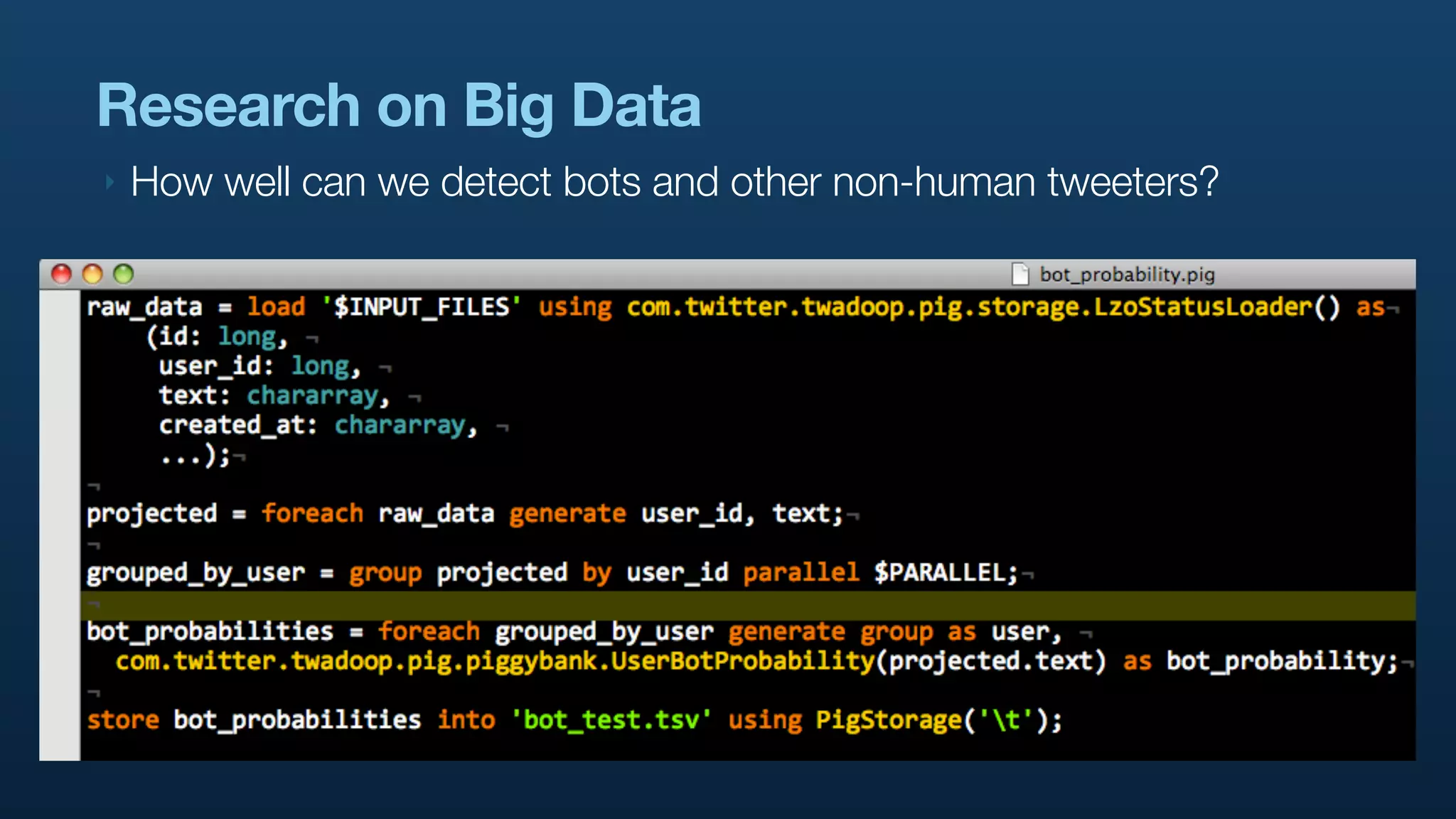



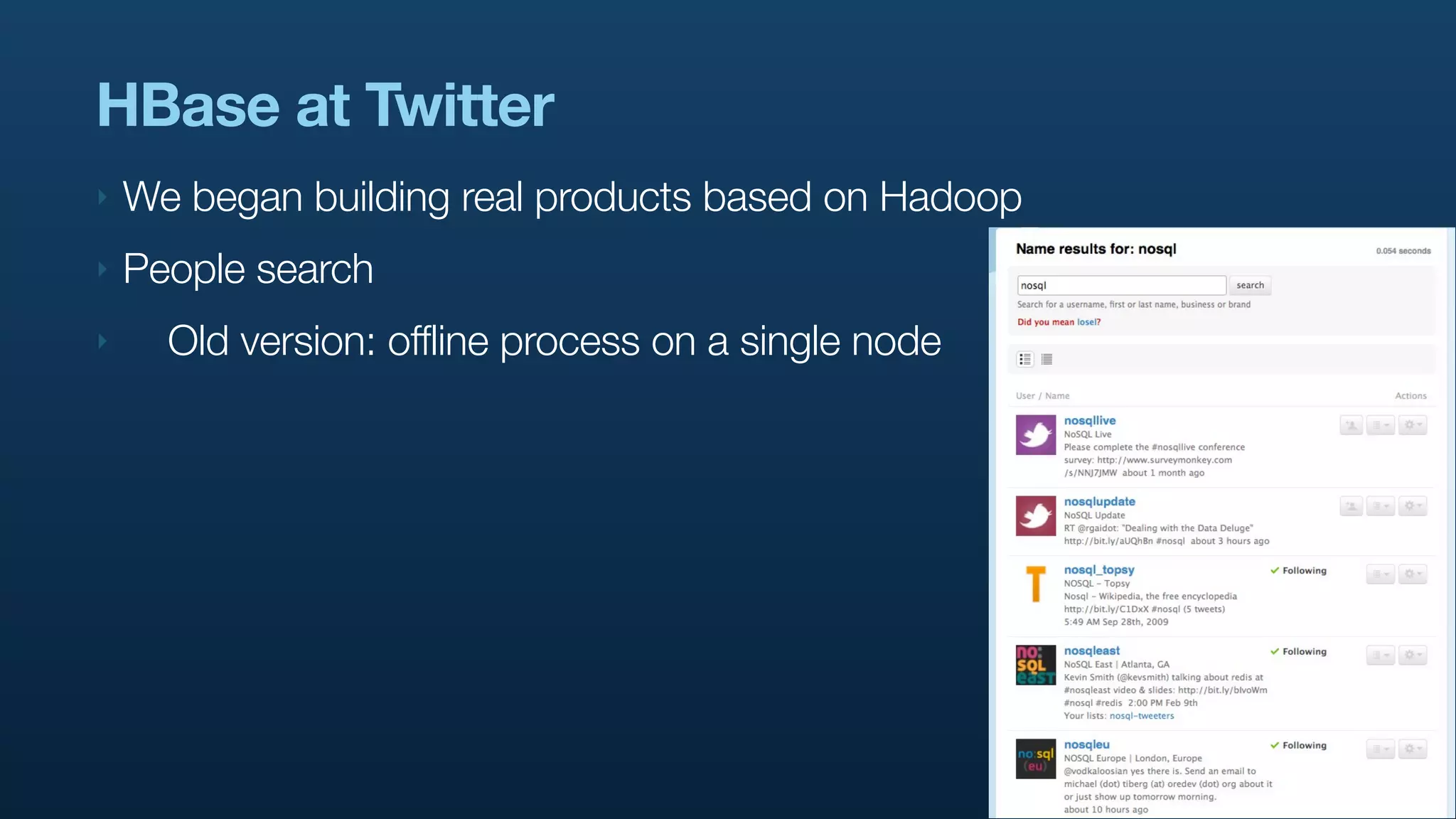
















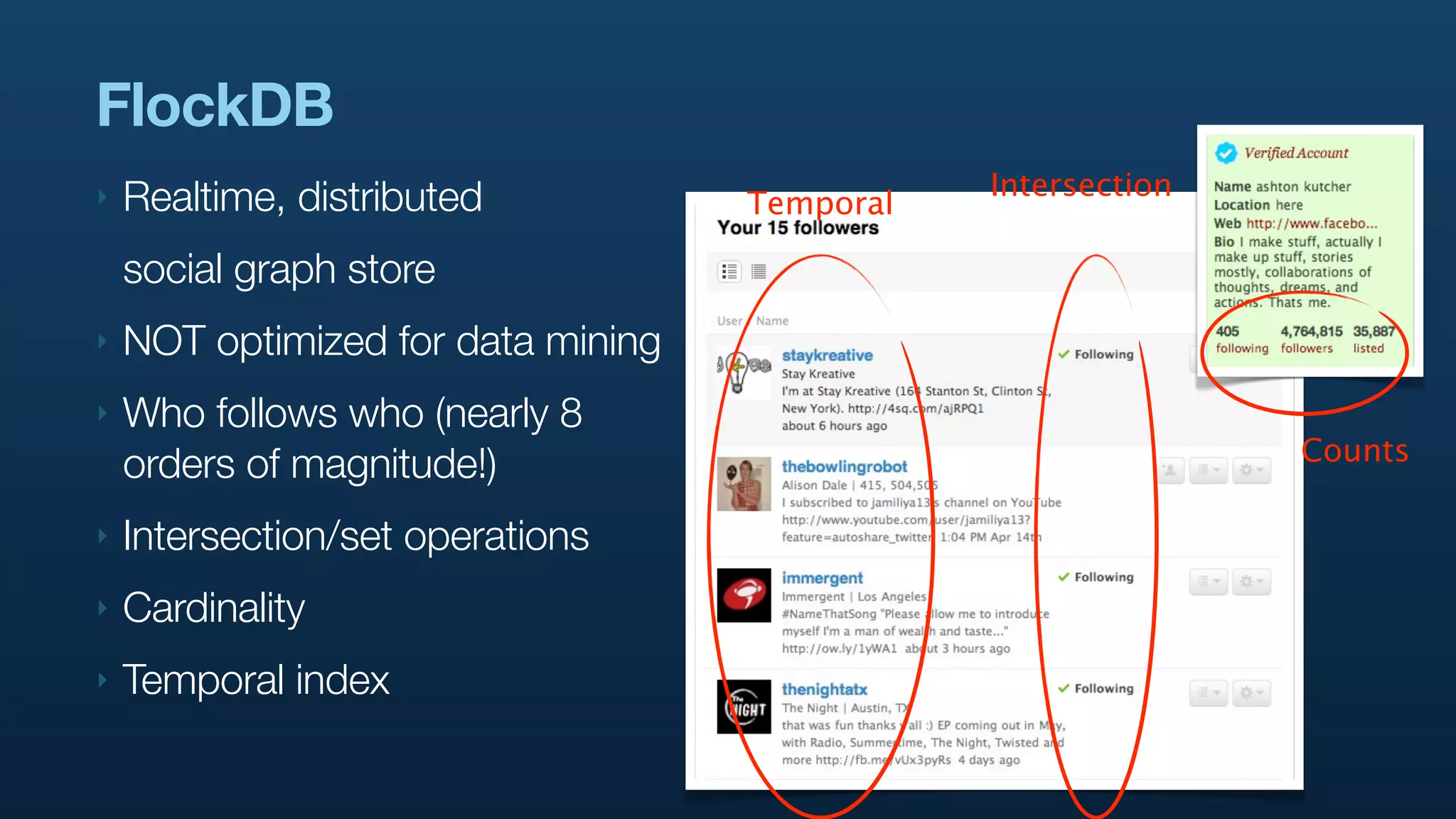
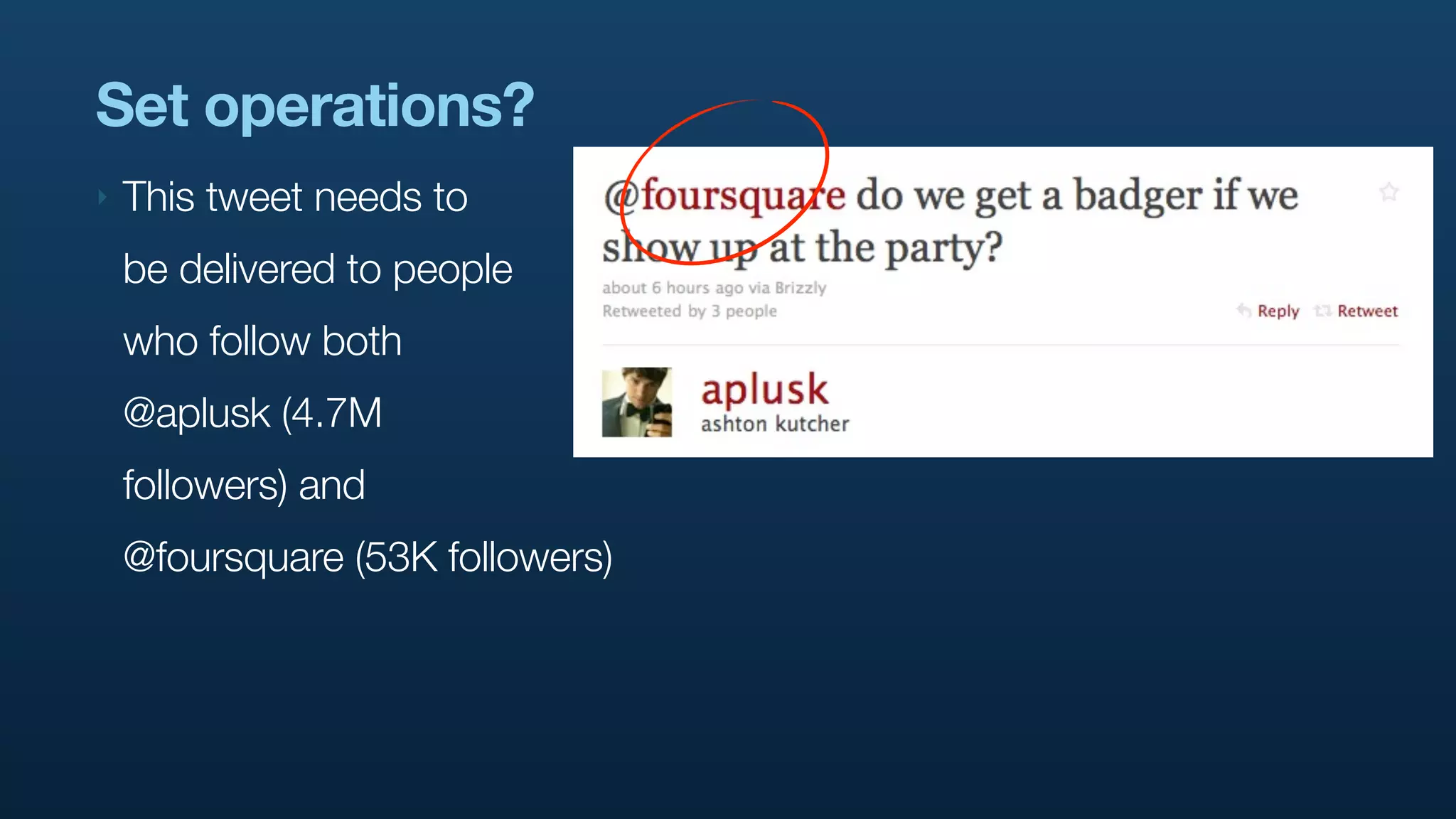

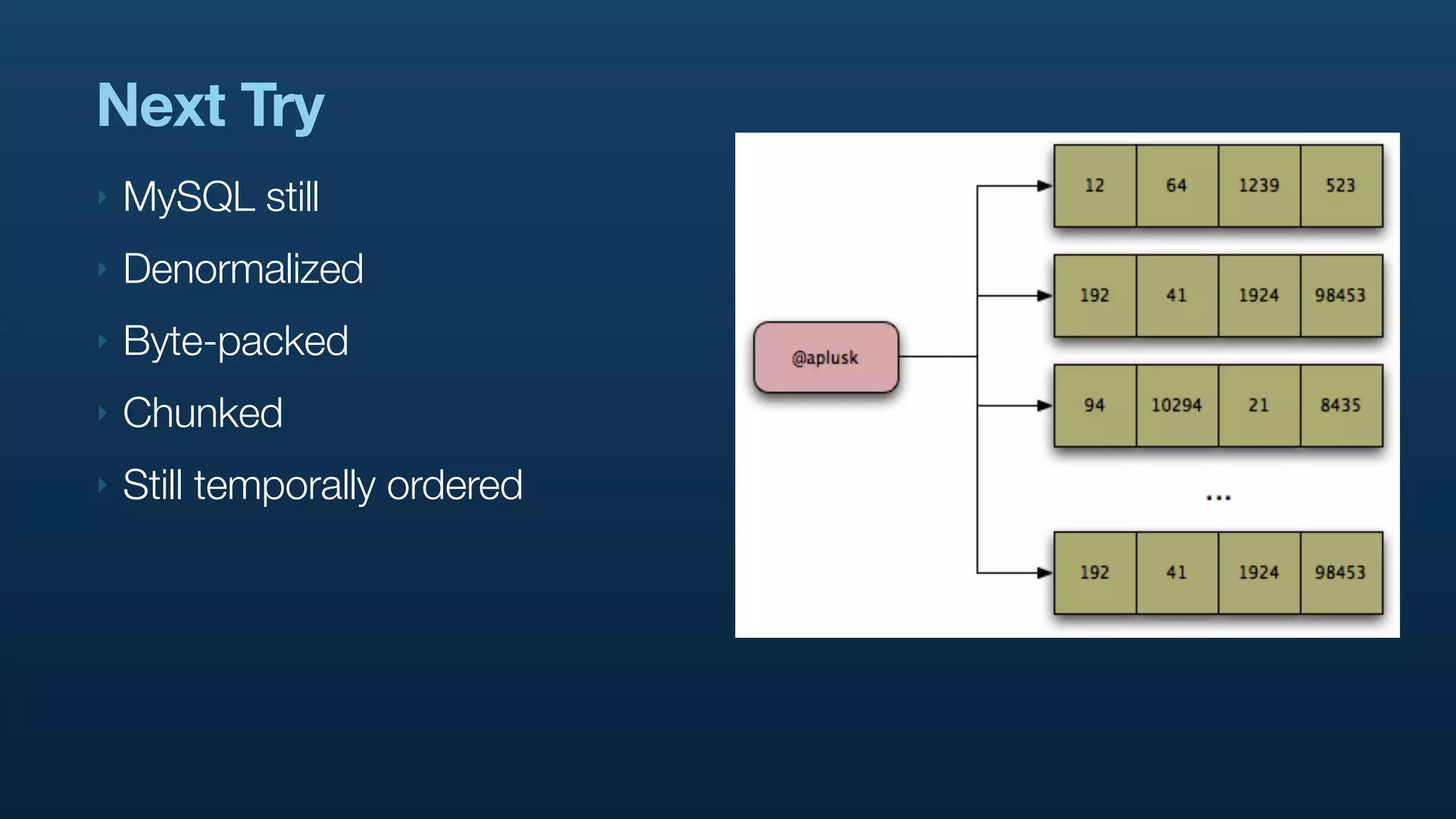
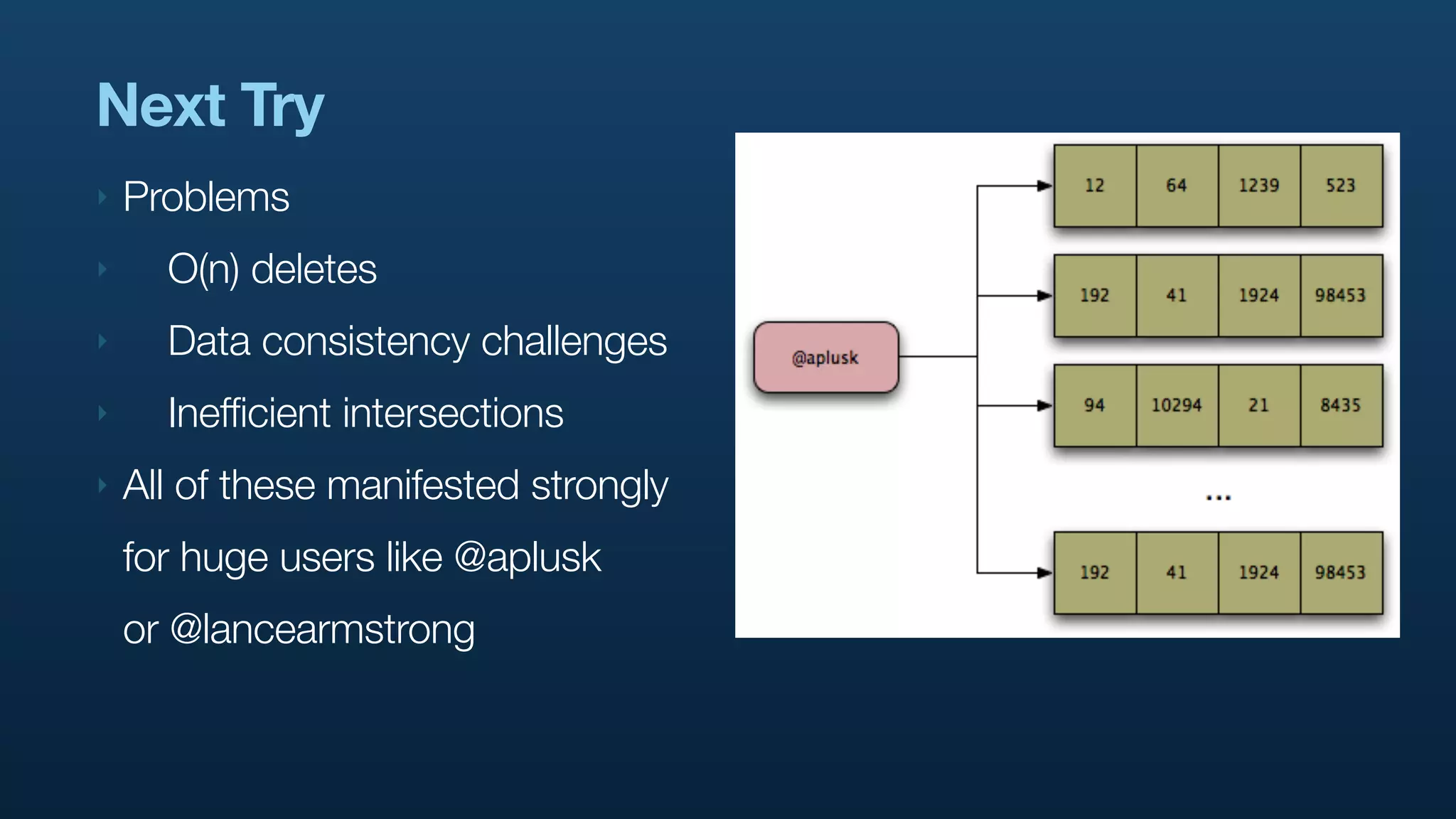































The document discusses Twitter's use of NoSQL databases and big data analytics, detailing the challenges of managing and analyzing the massive amounts of data generated by its users, which can reach 7 TB per day. It highlights the implementation of technologies like Scribe for data collection, Hadoop for storage and analysis, and Pig for simplifying data processing tasks. The presentation emphasizes the need for scalable solutions to support the growing data demands and improve analysis efficiency.























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











