This document discusses tries, a data structure used to store strings. It begins by outlining the advantages of tries over hash tables, including faster insertion and lookup. It then defines a trie as a tree that stores strings where all descendants of a node have a common prefix. The document describes standard tries and compressed tries, noting compressed tries save space by merging nodes with only one child. It provides examples and discusses time/space complexity. Applications mentioned include word matching, prefix matching, and use in web search engines to index words and associated URLs.
2. Outline
• Understand Requirements
• What is Trie?
• Different types of Tries.
• Memory and Time Analysis using Tries
• Various application of the Tries
3. Understand Requirements
● Insertion is faster as compared to the Hash
Table
● Lookup is much more faster than hash table
implementations
● You can store as many keys as much you want
without any reconstruction as like in Hash Table
if size becomes full
● There are no collision of different keys in tries
4. What is TRIE?
• The term trie comes from retrieval. This term
was coined by Edward Fredkin, who pronounce
it tri as in the word retrieval
• In computer science, a trie, also called digital
tree and sometimes radix tree or prefix tree
• All the descendants of a node have a common
prefix of the string associated with that node,
and the root is associated with the empty string.
5. Different Types of Tries
● Standard Tries
● Compressed/Compact Tries
● Suffix Tries
6. Standard Tries
• The standard trie for a set of strings S is an
ordered tree such that:
o each node but the root is labeled with a
character
o the children of a node are alphabetically
ordered
o the paths from the external nodes to the root
yield the strings of S
7. •The number of children a node can have is the
size/total number of characters in the language
and all children are ordered alphabetically.
•leaf node is represented as square
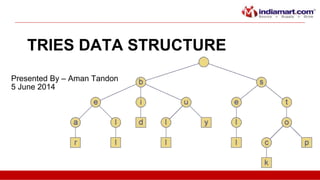
•Example: standard trie for the set of strings S = {
bear, bell, bid, bull, buy, sell, stock, stop }
9. ● A standard trie uses O(n) space. Operations (find,insert,
remove) take time O(dm) each, where:
○ n = total size of the strings in S
○ m =size of the string parameter of the operation
○ d =alphabet size
● The bad thing about this data structure is space
requirements
Time/Space complexity of Standard Tries
10. Applications of Standard Tries
● word matching: find the first occurrence of word X in the text
● prefix matching: find the first occurrence of the longest prefix of word X in
the text
11. Compressed Tries
● The bad thing about the standard tries is the space requirements, to overcome we
can use the compressed tries
● Compressed Trie are with the nodes of degree at least 2
● If any node has only one child, then we can merge it into a single node
16. Tries and Web Search Engines
● The index of a search engine (collection of all
searchable words) is stored into a compressed
trie
● Each leaf of the trie is associated with a word
and has a list of pages (URLs) containing that
word, called occurrence list
● The trie is kept in internal memory
17. ●The occurrence lists are kept in external
memory and are ranked by relevance
●Boolean queries for sets of words (e.g., Java
and coffee) correspond to set operations
(e.g.,intersection) on the occurrence lists