Le codifiche audio percettive
•
1 like•1,487 views

Breve introduzione al funzionamento dell'orecchio e di come i principi base della percezione sonora possono essere usati per codifiche digitali efficienti

Recommended
More Related Content
Similar to Le codifiche audio percettive
Similar to Le codifiche audio percettive (20)
More from Davide Cilano
More from Davide Cilano (6)
Le codifiche audio percettive
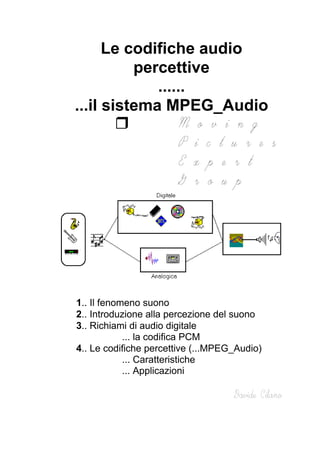
- 1. Le codifiche audio percettive ...... ...il sistema MPEG_Audio 1.. Il fenomeno suono 2.. Introduzione alla percezione del suono 3.. Richiami di audio digitale ... la codifica PCM 4.. Le codifiche percettive (...MPEG_Audio) ... Caratteristiche ... Applicazioni
- 2. Le codifiche audio percettive ...... ...il sistema MPEG_Audio 1.. Il fenomeno suono 2.. Introduzione alla percezione del suono 3.. Richiami di audio digitale ... la codifica PCM 4.. Le codifiche percettive (...MPEG_Audio) ... Caratteristiche ... Applicazioni
- 3. INTRODUZIONE Negli ultimi anni, con la diffusione dell'audio digitale (soprattutto grazie al Compact Disc), sono aumentate le esigenze degli ascoltatori in termini di fedeltà di riproduzione del suono. La percezione dei suoni è un fenomeno molto complesso in cui vengono coinvolti organi fisici ed aspetti psicologici. Proprio la dipendenza da fattori psicologici permette l'affinarsi delle capacità percettive degli ascoltatori e quindi l'aumentare della richiesta di qualità del suono. In campo digitale la qualità di un suono può essere mantenuta con una accurata rappresentazione che, se fatta con metodi tradizionali, porta inevitabilmente a grandi quantità di dati da memorizzare o trasmettere. Queste grandi quantità di dati possono essere gestite solo con apparecchiature altamente affidabili e dai costi proibitivi per la distribuzione su larga scala. Per fare un esempio basti pensare alla richiesta di 768 KBit/sec. per sequenze monofoniche della codifica PCM (Pulse Code Modulation) che, per essere distribuite su larga scala, hanno richiesto lo sviluppo del Compact Disc. La richiesta di alta qualità a basso costo ha indotto numerosi enti di ricerca allo studio di codifiche ottimizzate che permettano di ridurre le dimensioni della rappresentazione digitale. Tali ricerche, hanno individuato una possibile soluzione al problema applicando i risultati degli studi sul comportamento dell'apparato uditivo ed ottenendo la compressione sfruttando le capacità fisico- percettive dell'orecchio. Tra tutte le codifiche proposte si è distinta, per la sua flessibilità e qualità, il sistema MUSICAM (Masking pattern Universal Subband Integrated Coding And Multiplexing, 1992). La codifica MUSICAM ottiene, tramite una analisi psicoacustica del suono, la compressione delle informazioni necessarie per rappresentare segnali audio eliminando le componenti percettivamente irrilevanti e codificando quelle numericamente ridondanti. Tale operazione permette di conservare la qualità originaria del suono pur riducendo la quantità di dati di un fattore tipico di 1:8. La soppressione delle informazioni psicoacusticamente irrilevanti è possibile grazie alle recenti scoperte sul funzionamento dell'apparato uditivo umano, che hanno permesso la costruzione di modelli matematici implementabili in tempo reale, che approssimano le capacità acustico-percettive umane. Il modello percettivo partendo da una rappresentazione temporale del segnale audio, studia l'influenza tra toni mascheranti e toni mascherati nel dominio frequenziale, individuando le componenti del segnale percepibili, che sono le uniche informazioni essenziali da codificare. Il sistema MUSICAM è stato inizialmente progettato per il DAB (Digital Audio Broadcasting), una rete di distribuzione radiofonica via etere che dovrà sostituire le attuali trasmissioni FM. In seguito il MUSICAM è stato standardizzato a livello mondiale dall' ISO-IEC/ JCT1/ SC29/ WG11/ MPEG-Audio ed adottato per la distribuzione su supporti magnetici (DCC - Digital Compact Cassette - Philips) e televisiva (HDTV - Televisione ad alta definizione-).
- 4. Parte 1 IL FENOMENO "SUONO" 1.1. INTRODUZIONE...........................................................................................................................1 1.2. LE CARATTERISTICHE DEL SUONO .........................................................................................2 1.2.1. Ampiezza..........................................................................................................................2 1.2.1.1. DeciBel........................................................................................................3 1.2.2. Frequenza e Timbro .......................................................................................................3 1.3. LA DIVISIONE IN OTTAVE ..........................................................................................................4 1.4. IL RUMORE...................................................................................................................................4 1.5. COMPONENTI TONALI................................................................................................................5 Il capitolo riporta una sintesi dei concetti base e delle caratteristiche fisiche del "suono". Vengono riportate alcune definizioni ed unità di misura che saranno usate in seguito per la descrizione del sistema di compressione dell'audio MPEG_Audio1. 1.1. INTRODUZIONE Il suono è un fenomeno ondulatorio prodotto da movimenti vibratori di un corpo (detto sorgente) e si diffonde con perturbazioni di pressione in un mezzo solido, liquido o gassoso. Le molecole del mezzo propagano il disturbo compiendo degli spostamenti lungo la direzione di propagazione . Tutti i movimenti vibratori con una frequenza che rientra nell' intervallo udibile dall'uomo sono definiti suoni. Il fenomeno acustico dal punto di vista fisico coinvolge sempre tre elementi: .... la sorgente corpo vibrante .... il mezzo qualsiasi mezzo elastico .... il ricevitore l'apparato uditivo La sorgente genera il suono, il mezzo lo trasmette ed il ricevitore percepisce le variazioni di pressione. Nelle applicazioni ingegneristiche il mezzo o canale di trasmissione può comprendere apparecchiature per la trasmissione sotto altre forme energetiche come ad esempio la distribuzione radiofonica che avviene nell'etere sotto forma di onde elettromagnetiche. Indipendentemente dalla forma di trasmissione un suono può essere percepito e generato solo sotto forma di variazioni di pressione. 1MPEG : (Moving Pictures Expert Group) ha definito le specifiche di una codifica che ottiene la compressione dell'audio digitale ovvero la riduzione del numero di simboli usati.
- 5. Sorgente Trasformazione in altra forma energetica Trasmissione Trasformazione in variazioni di pressione Fig. 1.1 I suoni possono essere prodotti solo sotto forma di variazioni di pressione così come l' uomo può percepire i suoni solo come variazioni di pressione. La trasmissione dei segnali sonori può invece avvenire anche sotto altre forme energetiche. 1.2. LE CARATTERISTICHE DEL SUONO Il suono è un particolare tipo di segnale che può essere rilevato dall'apparato uditivo umano ed è caratterizzato da : ... intensità o ampiezza ... acutezza o frequenza ... timbro carattere che distingue lo stesso suono generato da sorgenti diverse 1.2.1. Ampiezza Alcune misure di ampiezza sono: Potenza sonora (P) è l'energia totale emessa dalle sorgente nell'unità di tempo e si misura in Watt. Pressione sonora (p) è la variazione di pressione prodotta dal fenomeno sonoro rispetto alla quiete e può assumere valori sia positivi che negativi e si misura in BAR o Newton/m2 . Intensità sonora (I) è il flusso di energia trasmesso attraverso un'area di sezione unitaria perpendicolare alla direzione di propagazione del suono si misura in Watt/m2. Di seguito è riportata una tabella con alcuni valori tipici di potenza sonora: FENOMENO POTENZA SONORA [WATT] Aereo al decollo 100 Martello pneumatico 1 Automobile in corsa 0,1 Ventilatore industriale 0,01 Voce forte 0,001 Lavastoviglie 0,0001 Piccolo ventilatore 0,00001 Sussurro 0,000000001 Tab 1.1 Alcuni valori di potenza sonora espressi in Watt [Lazzarin]
- 6. Per misurare l'ampiezza di segnali audio in un intervallo temporale si può fare riferimento al massimo valore assunto dal segnale (come pressione, potenza o intensità) detto valore di picco (peak) che rappresenta il livello massimo trattabile dal sistema. Il valore di picco è però una misura ingegneristica che poco si adatta alle caratteristiche percettive dell'uomo in quanto il segnale può raggiungere tale valore solo in brevi istanti e rimanere più basso nella maggior parte dell'intervallo di ascolto. Una misura più rappresentativa potrebbe essere il valore medio dell'ampiezza dell'onda sonora sullo stesso intervallo, anche tale misura è però poco significativa in quanto i risultati di alcuni studi indicano che l'orecchio è maggiormente sensibile al segnale integrato su brevi periodi temporali (tipicamente 0.25 secondi) ed è fortemente dipendente dalla frequenza del segnale, segue quindi che le tradizionali misure fisiche non si prestano ad un dimensionamento valido dei fenomeni acustici così come sono percepiti. 1.2.1.1. DeciBel Il grande intervallo di potenze sonore udibili è evidenziato dalla Tab 1.1.1 che si estende in un rapporto 1:1.000.000.000 così come i valori in pressione sonora che variano da 2 x 10-4µbar a 200µ bar in un rapporto 1:1.000.000. Per evitare di dover usare numeri troppo grandi è stata proposta una misura logaritmica della potenza sonora: il BEL, che, tra l'altro, si adatta perfettamente alle caratteristiche percettive dell'orecchio umano. Il BEL è definito come il logaritmo in base 10 del rapporto di due quantità con le stesse caratteristiche dimensionali, cioè è adimensionale e esprime un raffronto tra due valori: quello da misurare ed un livello di riferimento. rifrif I I Log p p LogBEL 10 2 10 = ö ç ç è æ = Per il nostro scopo però il BEL è ancora una misura troppo grande e per questo viene diviso in DECIBEL. rifrifrif I I Log p p Log p p LogDECIBEL 1010 2 10 102010 == ö ç ç è æ = Il valore di riferimento (Irif , prif) può essere fissato arbitrariamente (in quanto il BEL esprime solo la differenza di livelli) e nel caso si usi il valore della minima intensità udibile di IRif=10-12 W/m2 o della minima pressione rilevabile di 2x10-5N/m2 prende il nome di dB SPL (Sound Pressure Level o Livello di pressione sonora). Il dB è in tal modo una misura appropriata per esprimere intensità sonore , ad esempio le intensità della Tab 1.1.1 coprono un intervallo di circa 180 dB. 140 dB Aereo 130 dB Soglia del dolore 110 dB Moto in accelerazione 90 dB Strada urbana 80 dB Locale pubblico 60 dB Traffico automobilistico 50 dB Voce di conversazione 20 dB Ticchettio orologio 10 dB Fruscio foglie Tab 1.2 Alcuni valori di intensità sonora in dB SPL [Lazzarin]
- 7. 1.2.2. Frequenza e Timbro Percettivamente la frequenza definisce l'acutezza di un suono; le basse frequenze sono proprie di suoni gravi le alte frequenze di suoni acuti. La forma d'onda periodica più semplice è la funzione seno, tutte le onde sinusoidali con qualsiasi frequenza nel campo dell'udibile sono dette TONI PURI (o TONI SEMPLICI) mentre quelle non riconducibili a toni puri sono dette TONI COMPLESSI. 1.3. LA DIVISIONE IN OTTAVE L'intervallo di frequenze udibili dall'uomo è solitamente indicato dai valori tra 20 e 20000 Hz , tali limiti sono solo indicativi in quanto i valori reali dipendono da molti fattori sia fisici che psicologici: .. le caratteristiche genetiche dell'individuo .. la "dotazione fisica" dell'apparato uditivo .. l' età .. l' affaticamento acustico .. l' esperienza in ascolto Tutti gli individui rilevano però una sensazione di "similitudine" tra toni fondamentali di frequenza doppia, tripla, quadrupla, ecc. Per tale motivo è stata introdotta la divisione in ottave dello spettro di frequenze udibili. Un'ottava è definita come l'intervallo di frequenza tra due fenomeni di cui uno abbia frequenza doppia dell'altro. Le frequenze udibili hanno un'estensione di circa 11 ottave e può essere interessante confrontarlo con l'intervallo delle onde visibili che coprono meno di una ottava. Per definizione ogni banda in ottave è individuata dalla media geometrica delle frequenze che la delimitano, detta frequenza caratteristica o nominale. f f f f f alta bassa caratteristica alta bassa = = 2 Un'altra divisione della banda di frequenze udibili può essere fatta in 1/3 di ottava , in tal caso si ottengono 31 bande ognuna delle quali è compresa tra due frequenze che sono in un rapporto di 23 : f f f f f alta bassa caratteristica alta bassa = = 23 1.4. IL RUMORE Il rumore è definito [ANSI S 1.1] come la somma di oscillazioni irregolari, intermittenti o statisticamente casuali. Percettivamente è un suono innaturale e disturbante. Un rumore può essere classificato in base alle sue caratteristiche in [Cosa] : .. continuo o discontinuo riferito alla durata nel tempo .. stazionario o fluttuante in base all'intensità .. casuale se la durata e l'intensità sono irregolari .. impulsivo se la sua energia è concentrata in brevi intervalli temporali La soglia di percezione del rumore dipende dall'intensità, dalla frequenza e , per rumori di tipo impulsivo anche dalla durata. Tipicamente la soglia di percezione dipende fortemente dalla frequenza ed è tra -1 e 3 dB SPL per le frequenze centrali, aumenta a 10-20 dB SPL alle alte frequenze e a 40-70dB SPL per le basse. La soglia temporale di percezione del rumore è di circa 100ms. Un suono si differenzia dal rumore solo per le sensazioni di piacere o sgradevolezza che suscita e non ne esiste una distinzione oggettiva.
- 8. 1.5. COMPONENTI TONALI Le componenti tonali sono quelle componenti di un tono complesso che più assomigliano a toni puri. Un metodo semplificato per valutare la presenza di componenti tonali in una emissione sonora è di effettuarne una analisi per bande di 1/3 di ottava [Cosa]: "se il livello di pressione sonora di una o più bande di 1/3 di ottava dello spettro sonoro supera per più di 5 dB quello delle due bande adiacenti, si è in presenza di componenti tonali." Tutte le componenti del segnale sonoro che dall'analisi non risultano essere tonali vengono dette NON TONALI e possono essere assimilate a rumore.
- 9. Parte 2 INTRODUZIONE ALLA PERCEZIONE DEL SUONO 2.1. ORECCHIO UMANO E SENSIBILITÀ IN FREQUENZA .............................................................1 2.2. LA PERCEZIONE ..........................................................................................................................3 2.3. UNITÀ DI MISURA PERCETTIVE................................................................................................3 2.3.1. Il Bark..............................................................................................................................3 2.3.2. Loudness..........................................................................................................................4 2.3.3. Il Phon.............................................................................................................................4 2.4. IL MASCHERAMENTO .................................................................................................................5 2.4.1. ... Nella Frequenza ..........................................................................................................6 2.4.2. ... Nel Tempo ...................................................................................................................8 2.4.3. ... Nel Tempo e Frequenza...............................................................................................9 2.5. PERCEZIONE DI VARIAZIONI DI INTENSITÀ...........................................................................10 L'orecchio è sensibile ai segnali in funzione della frequenza e dell'ampiezza, due suoni di diversa frequenza e pari intensità vengono percepiti di intensità diversa. Questo capitolo è un' introduzione alla terminologia ed ai fenomeni coinvolti nel processo di percezione dei suoni, vengono definite alcune unità di misura percettive, si riporta una breve descrizione del funzionamento dell'apparato uditivo e si introduce il fenomeno di mascheramento tra suoni. 2.1. ORECCHIO UMANO E SENSIBILITÀ IN FREQUENZA L'orecchio può essere diviso dal punto di vista funzionale in [Lazzarin] : .. orecchio esterno .. padiglione auricolare .. condotto uditivo esterno .. membrana timpanica
- 10. .. orecchio medio .. cavità ossea con tre ossicini : martello, incudine e staffa .. finestra ovale .. due muscoli di smorzamento dei movimenti di tre ossicini (martello, incudine, staffa) .. un canale di comunicazione con l'atmosfera per compensare le pressioni sulle due superfici della membrana timpanica (Tromba di Eustacchio) .. orecchio interno .. vestibolo .. canali semicircolari detti labirinto .. coclea , canale colmo di un materiale elastico Orecchio Esterno Orecchio Medio Orecchio Interno Fig 2.2 Struttura interna dell'orecchio umano, sono indicati i principali organi coinvolti nel processo di percezione. Il canale cocleare è la parte che più influenza i fenomeni di percezione sonora. La coclea è un canale lungo circa 35mm. a fondo cieco che è diviso per tutta la sua lunghezza in tre camere dalla membrana basilare. Queste tre parti sono: .. superiore : o vestibolare comunica con l'orecchio medio attraverso la finestra ovale .. inferiore : o timpanica comunica con la superiore verso l'apice della coclea .. media : che contiene una sostanza detta endolinfa
- 11. Sulla membrana basilare si trova l'organo di Corti in cui sono situate le cellule recettrici il cui compito è di trasformare le differenze di pressione in impulsi elettrochimici da inviare al cervello. Segue una descrizione sintetica del fenomeno della percezione sonora : -- l'orecchio esterno funzionando da risonatore per le frequenze tra 1000 e 7000 Hz (maggiormente efficace intorno a 3000 Hz) produce un incremento di circa 10-12dB delle pressioni sonore fra l'esterno ed il timpano -- nell'orecchio medio la membrana timpanica mette in vibrazione martello, incudine e staffa, che, funzionando come un sistema di leve triplicano la forza applicata sulla finestra ovale (la cui superficie è 1/30 di quella del timpano) -- a questo punto la pressione originaria esercitata sul timpano è stata amplificata di circa 90 volte e viene impressa sulla finestra ovale -- dalla finestra ovale il suono (sotto forma di variazione di pressione) giunge all'orecchio interno dove attraverso il movimento del liquido cocleare dei canali vestibolare e timpanico la membrana base mette in risonanza le cellule situate nell'organo di Corti. -- le cellule del Corti producono dei segnali di tipo elettrochimico che attraverso il nervo uditivo giungono al cervello secondo un processo non ancora ben conosciuto. In tutto il processo di percezione uditiva vengono coinvolti numerosi fenomeni soggettivi che possono produrre in individui diversi sensazioni differenti in presenza dello stesso suono esterno. Inoltre sono presenti altri fenomeni di "autodifesa" che modificano la caratteristica dell'informazione trasmessa nell'apparato uditivo. Ad esempio i tre ossicini martello, incudine e staffa sono controllati da dei piccoli muscoli che in presenza di alte intensità sonore ne riducono il potere amplificante (solo per suoni di durata superiore ai 200ms.). La percezione di un suono può avvenire anche per via ossea (soprattutto per quello auto prodotto). 2.2. LA PERCEZIONE I recenti studi in campo psicoacustico hanno evidenziato che l'apparato uditivo umano è in grado di rilevare solo alcune caratteristiche del segnale audio ed in particolare: Caratteristica FISICA Fenomeno PERCEPITO Frequenza Pitch Intensità Livello percepito o Loudness Forma spettrale, Modulazione ,Frequenza Intensità, Fluttuazioni, Rigidezza Tempo Durata soggettiva Tab 2.3 Caratteristiche fisiche del suono e corrispondente fenomeno percepito dall'uomo. La descrizione di come vengono percepiti i suoni può essere semplificata se al posto delle unità di misura "fisiche" si usano unità di misura "percettive" ovvero costruite "ad hoc" sulla capacità di risoluzione dell'apparato uditivo. Così al posto della frequenza conviene usare le bande critiche o Bark, e al posto dell'intensità il loudness misurato in Phon. 2.3. UNITÀ DI MISURA PERCETTIVE Nei paragrafi che seguono si riportano le definizioni delle unità di misura percettive di uso comune e se ne spiega il significato e l'uso.
- 12. Tali unità di misura essendo percettive sono valide solo su base statistica e sono state ottenute da studi compiuti negli anni passati su grandi campioni di individui acusticamente sani. Ne segue che sono valide per ascoltatori che rientrano nella media e non per soggetti affetti da patologie o dotati di particolare acutezza. Le unità di misura esposte sono state soggette all'approvazione e standardizzazione dell'ISO (International Standard Organization). 2.3.1. Il Bark Il Bark è una unità di misura non lineare che viene usata per dividere l'intera banda di frequenze udibili in sottobande confinanti non sovrapposte che ben modellizzano il processo di percezione dei suoni da parte dell'uomo. Il concetto delle bande critiche è basato sulla comprovata assunzione che il nostro sistema uditivo analizza lo spettro di un segnale audio dividendolo in sottobande (dette bande critiche). Banda Critica [Aarts]: La banda di frequenze più larga in cui l'intensità di un rumore distribuito casualmente nella stessa banda di intensità energetica costante (SPL) è indipendente dalla sua larghezza di banda. Aggiungendo una banda critica alla successiva, in modo che il limite superiore della più bassa coincida con quello inferiore della più alta, si ottiene la scala di banda critiche che è non lineare in quanto le bande critiche hanno un'ampiezza variabile in funzione della frequenza e seguono un'andamento pressoché logaritmico. Fig 2.3 Rappresentazione delle frequenze coperte dai Bark: in ascissa è rappresentata la frequenza, in ordinata le bande critiche 0:24 . La curva rappresenta l'intervallo di frequenza coperto dalle bande critiche. 2.3.2. Loudness Indica l'intensità percepita di un suono e dipende dall'intensità energetica e dalla frequenza, in particolare le definizioni sono [Aarts]: Loudness: Attributo di sensazione uditiva secondo cui un suono può essere ordinato in una scala da lieve a intenso Livello di Loudness: livello della pressione sonora di riferimento, scelta come un'onda sinusoidale di frequenza 1KHz proveniente dal fronte dell'ascoltatore e che è giudicato da una persona con udito sano di uguale intensità al suono di raffronto.
- 13. La scala dei loudness è stata costruita sperimentalmente basandosi sul livello di riferimento di un tono di 1KHz a 40 dB (suono di riferimento standard in elettroacustica). Il loudness può essere misurato in Phon. 2.3.3. Il Phon La sensibilità uditiva varia in funzione della frequenza ed in particolare è massima per le frequenze centrali e minima per le estreme (alte e basse). Il PHON è la misura dell'intensità soggettiva del suono (LOUDNESS) e rappresenta l'intensità necessaria per produrre ad una certa frequenza la stessa sensazione uditiva in deciBel, di quella di un tono alla frequenza di 1000 Hz, a tale frequenza i livelli di Phon e dB si equivalgono. Fig. 2.4 Audiogramma in PHON ISO R 226 di Robinson e Dadson, riporta in funzione della frequenza l'intensità necessaria in dB per produrre la stessa sensazione in intensità di un tono a 1KHz; le linee di isosensazione esprimono l'intensità in dB che un suono deve avere in funzione della frequenza per essere percepito ad una intensità costante in PHON. L'audiogramma riportato nella Fig 1.2.6 riporta le curve di ISOSENSAZIONE (intensità soggettiva del suono) e si riferisce a toni puri. I risultati tabulati sono l'esito di prove eseguite da Robinson e Dadson su un campione di individui sani. 2.4. IL MASCHERAMENTO Non tutte le vibrazioni entro la banda dell'udibile sono percepite dall'orecchio umano, la loro rilevazione da parte dell'apparato uditivo dipende in prima approssimazione dall'intensità e dalla frequenza e da analisi più accurate anche dai segnali adiacenti sia nel dominio del tempo che della frequenza; tale fenomeno è noto con il nome di mascheramento. Il mascheramento è definito come il livello di pressione sonora o dB SPL di un tono di riferimento necessario perché questo possa essere udito in presenza di uno mascherante. La percettibilità di un tono puro in assenza di altri segnali dipende principalmente della frequenza e intensità dando origine a quella che viene detta soglia statica di mascheramento o in quiete. Altri fattori che influiscono nella determinazione della soglia di mascheramento sono: .. durata .. dotazione fisica dell'individuo .. età .. affaticamento .. stato fisico .. stato psichico dell'individuo
- 14. Fig. 2.5 Soglia di percezione in quiete in funzione della frequenza e dell'intensità sonora. La soglia di mascheramento per toni complessi è detta soglia di mascheramento dinamica ed è fortemente dipendente dalla microstruttura del segnale in quanto i toni componenti interagiscono mascherandosi a vicenda e contribuendo alla forma finale della maschera. La maschera può essere studiata sia nel dominio del tempo che della frequenza; nel dominio del tempo il mascheramento può essere simultaneo e non simultaneo mentre in quello della frequenza un tono maschera quelli di frequenza adiacente a seconda dell'intensità. 2.4.1. ... Nella Frequenza Nel dominio della frequenza il mascheramento è molto intenso in prossimità dei toni mascheranti, che alzano in modo significativo i valori di soglia statica, in particolare se l'orecchio percepisce un suono di una certa frequenza, presenta minore sensibilità per le frequenze vicine ad essa. La conoscenza di tale fenomeno permette la costruzione della soglia di mascheramento. In generale un suono ad una certa frequenza maschera tanto più i suoni di frequenza adiacente quanto più è intenso. La figura 2.5 riporta la curva di mascheramento per toni a 0.5, 1.2, 4, 8 KHz con livello di 60 dB SPL, la scala delle frequenze è lineare. Fig 2.6 Curve di mascheramento in funzione della frequenza su scala lineare, la curva inferiore rappresenta la soglia statica. Per determinare tali curve si usa un tono di riferimento e si trova l'intensità affinché sia udibile in presenza di un mascherante. Nella Fig 2.5 si nota una gran diversità tra le curve di mascheramento al variare della frequenza. Risultati non diversi si ottengono dalla rappresentazione su scala logaritmica (Fig 2.6) :
- 15. Fig. 2.7 Rappresentazione su scala logaritmica degli effetti di toni mascheranti di intensità pari a 60 dB. Anche in scala logaritmica la forma delle curve risulta dipendente dalla frequenza, però si può notare come le curve su scala lineare sotto i 500 Hz siano uguali a quelle su scala logaritmica sopra i 500 Hz. Ciò suggerisce che si potrebbe ottenere l'indipendenza della forma della maschera dalla frequenza scegliendo una scala lineare sotto i 500 Hz e logaritmica al di sopra. Una tale scala di frequenze è già stata illustrata ed è quella dei Bark ; infatti la rappresentazione dello stesso fenomeno usando la scala dei bark evidenzia una forma di mascheramento costante: Fig 2.8 Rappresentazione della forma della curva di mascheramento di toni puri con livello di 60dB usando per la frequenza la scala dei Bark. Il vantaggio introdotto è evidente rendendo indipendente la forma della maschera dalla frequenza a meno di intersezioni con la soglia statica di mascheramento. Si noti che la funzione di mascheramento è molto più ripida a sinistra che a destra. Dunque, con la scala dei Bark lo studio dei fenomeni di mascheramento è molto semplificato permettendo la costruzione della soglia con una funzione dipendente solo dall'intensità. In particolare la dipendenza dall' intensità provoca l'allungamento della curva di mascheramento con l'aumentare del livello, tale fenomeno è dovuto alla saturazione delle cellule recettrici dell'orecchio interno.
- 16. Fig 2.9 Variazione della forma della curva di mascheramento in funzione dell'intensità del tono mascherante 2.4.2. ... Nel Tempo Nel dominio del tempo un tono viene mascherato notevolmente dalle sollecitazioni sonore temporali precedenti (specialmente per quelle più immediate); ed in modo molto meno evidente e motivabile per quelle immediatamente future (per cui non è ancora stata trovata una valida spiegazione), tale fenomeno è noto come mascheramento temporale e si distingue in simultaneo e NON simultaneo. Un esempio della condizione di simultaneità potrebbe essere il caso in cui noi abbiamo una conversazione con un vicino mentre passa un treno. La nostra conversazione risulta disturbata e per poterla continuare è necessario "alzare la voce" per produrre più potenza e quindi una maggiore sonorità. Nella musica si ha un comportamento analogo. I differenti strumenti si possono mascherare tra di loro, gli strumenti più tenui possono essere uditi solo quando non sono presenti quelli più forti. NON SIMULTANEO Fenomeno secondo cui un tono "copre" quelli vicini nel tempo sia passato che futuro. La soppressione nel tempo futuro può essere ben spiegata dagli studi sulle proprietà meccaniche degli apparati dell'udito interni mentre non è ancora stata trovata una valida spiegazione (sono state solo fatte delle supposizioni) del fenomeno del pre-mascheramento; vale a dire che un tono maschera non solo i suoni che seguono ma anche quelli che lo precedono. La supposizione più avvalorata è che a livello neurale venga compiuta una analisi del suono, come se fosse ritardato e analizzato prima di trasmetterne gli impulsi al cervello per la vera e propria "audizione". Fig 2.10 Rappresentazione schematica del fenomeno di mascheramento non simultaneo nel dominio del tempo, si può notare che il pre- mascheramento ha effetti minori del post-mascheramento. SIMULTANEO Riguardo al mascheramento simultaneo da esperimenti su animali si è trovato che ha luogo nell'orecchio interno, prima della trasmissione a livello neurale. Il mascheramento simultaneo ha come effetto l'aumento della soglia di mascheramento ad una composizione delle due.
- 17. 2.4.3. ... Nel Tempo e Frequenza Fig 2.11 Rappresentazione schematica del fenomeno di mascheramento di un tono puro nel dominio della frequenza. Una prima approssimazione delle curve di salita e discesa con delle rette è data da [Kapust]: BarkdBLivello f S BarkdBS dB /2,010, 230 min22 /31 2 1 ö ç ç è æ −÷÷ ö çç è æ += = Fig 2.12 Rappresentazione schematica del mascheramento temporale di un impulso di durata finita. Il post-masking si verifica come rilascio graduale degli effetti di mascheramento ovvero il mascherante non si arresta subito dopo il suo manifestarsi ma decresce gradatamente. L'effetto di post-masking dipende in modo non lineare anche dalla durata del mascherante. Gli effetti di durata e di mascheramento possono essere ben definiti in tre dimensioni (Bark, loudness, tempo) Fig 2.13 Rappresentazione del fenomeno di mascheramento nei domini di tempo, frequenza e intensità. Non solo il mascheramento può essere descritto più semplicemente in termini di Bark ma anche molti altri effetti, come la tonalità, le differenze di frequenza udibili distintamente e la crescita dell'intensità sonora in funzione della larghezza di banda.
- 18. 2.5. PERCEZIONE DI VARIAZIONI DI INTENSITÀ Le variazioni in intensità vengono percepite solo se superiori a 5 dB (più di un raddoppio dell'energia sonora2). La sensazione di raddoppio dell'intensità soggettiva corrisponde ad un incremento di 10 dB (corrispondente a un'amplificazione dell'energia iniziale di 10 volte !). 2Si ricorda che un raddoppio dell'energia sonora corrisponde all'aumento di 3 dB . Con 6 dB di aumento, si ha un quadruplicamento dell'energia sonora.
- 19. Parte 3 RICHIAMI DI AUDIO DIGITALE 3.1. INTRODUZIONE...........................................................................................................................1 3.2. L'SNR (Signal to Noise Ratio)........................................................................................................1 3.3. LA CODIFICA PCM (Pulse Code Modulation).............................................................................2 3.4. I SISTEMI DI COMPRESSIONE NELLA CATENA PCM ............................................................3 3.1. INTRODUZIONE Il termine "Audio digitale" indica la tecnica usata per la registrazione, la memorizzazione o la trasmissione dell'informazione sonora, che dovrà venire riportata in analogico per permetterne l'ascolto. Il suono infatti è per sua natura analogico e può essere prodotto e percepito solo sotto forma di variazioni di pressione; una sua rappresentazione (codifica) può invece essere fatta in forma analogica o digitale. Il termine digitale indica dunque solo un modo per "trasportare" (trasmettere o registrare) il segnale: Fig. 3.14 L'audio digitale è una alternativa alla forma analogica per la rappresentazione dell'informazione sonora, si tenga presente che un suono può essere prodotto e percepito solo sotto forma analogica. L'introduzione dell'audio digitale ha cambiato il modo di riprodurre ed ascoltare il "suono", l'audio digitale è infatti ben lontano come fedeltà di riproduzione dall'audio analogico, la qualità di riproduzione ottenibile con la tecnica digitale è notevolmente superiore alla analogica in quanto in generale l'accuratezza dei sistemi è una funzione del rumore introdotto dal sistema stesso; nei sistemi analogici tale rumore non è facilmente controllabile perché è difficile ottenere componenti con tolleranze inferiori all'1%. In digitale invece adottando la necessaria precisione numerica è possibile ottenere qualsiasi accuratezza che rimane (al contrario dell'analogico) invariante nel tempo. Altra caratteristica dei sistemi digitali è la possibilità di essere programmati ottenendo una maggior versatilità rispetto agli analogici. Si fa notare che il preferire l'audio digitale o analogico sia solo una scelta dettata dalle sensazioni soggettive che si hanno ascoltando l'audio in una o l'altra forma. 3.2. L'SNR (Signal to Noise Ratio) Il rumore di quantizzazione può essere più o meno udibile a seconda della sua intensità rispetto a quella del segnale audio in ogni intervallo di campionamento.
- 20. Per dare una misura dell'interferenza del rumore di quantizzazione e quindi di quanto può essere percepito può essere usato il rapporto segnale rumore; indicato con SNR. SNR Log Segnale Rumore dB= 20 10 Se si usa un numero B di Bit per la quantizzazione su livelli equi ampi, il rumore di quantizzazione vale: SNR Log B = 20 210 ed in forma approssimata : SNR B dB≅ +6 1 74. Si evidenzia così che ogni bit contribuisce per circa 6 dB al diminuire del rapporto SNR totale, in un segnale, maggiore è il rapporto SNR e più fedele è la rappresentazione dell'audio. Tuttavia si noti che per quantizzare un segnale analogico caratterizzato da un rumore intrinseco di 20 dB sarebbe del tutto inutile usare più di 4 bit per la quantizzazione digitale. Condizione sufficiente affinché il rumore di quantizzazione non sia udibile è che il valore di SNR sia superiore al valore in dB tra segnale e soglia di mascheramento per ogni banda critica. 3.3. LA CODIFICA PCM (Pulse Code Modulation) La rappresentazione numerica ottenuta campionando e quantizzando un segnale analogico può essere codificata secondo una qualsiasi sintassi. Ogni modo di rappresentazione permette però una diversa accuratezza nei processi di quantizzazione e campionamento determinando in l'efficienza del sistema in termini di: ... larghezza di banda ... rapporto segnale rumore ... accuratezza ... sensibilità agli errori Il sistema PCM viene universalmente accettato come una codifica efficiente per audio ad alta qualità, offrendo buoni parametri in termini di larghezza di banda, intervallo di dinamica e dimensioni della rappresentazione. Il sistema PCM quantizza l'intensità analogica in 2N livelli equiampi (N è il numero di bit della rappresentazione). In pratica il segnale in ingresso viene campionato ed il valore di ogni campione viene rappresentato con il livello più prossimo della rappresentazione digitale (troncando o arrotondando). Una sequenza di campioni per uno o più canali viene ottenuta alternandone le rappresentazioni PCM: N Bit N Bit N Bit N Bit N Bit N Bit N Bit N Bit N Bit N Bit N Bit N Bit Sinistr o Destro Sinistro Destro Sinistro Destro Sinistro Destro Sinistr o Destro Sinistro Destro Fig. 3.15 Rappresentazione di una sequenza di campioni PCM per segnali audio stereofonici
- 21. 3.4. I SISTEMI DI COMPRESSIONE NELLA CATENA PCM I sistemi di compressione dell'audio digitale riducono l'occupazione del mezzo di memorizzazione e del canale di trasmissione. Nella catena di registrazione digitale la codifica compressa si colloca prima della memorizzazione e prima della ricostruzione del segnale nel processo di decodifica
- 22. Parte 4 LE CODIFICHE PERCETTIVE (...MPEG_Audio) 4.1. LE CODIFICHE COMPRESSE .....................................................................................................1 4.2. LA CODIFICA MPEG_Audio........................................................................................................2 4.2.1. Introduzione ....................................................................................................................3 4.2.2. Caratteristiche.................................................................................................................3 4.2.2.1. Layer...........................................................................................................3 4.2.2.2. Frequenze di Campionamento ....................................................................4 4.2.2.3. Modalità......................................................................................................4 4.2.2.4. Bitrate .........................................................................................................5 4.2.3. Possibili Applicazioni......................................................................................................5 4.3. LA CODIFICA E I FRAME...........................................................................................................6 4.3.1. La Rappresentazione Frequenziale.................................................................................7 4.3.2. ... un Modello Psicoacustico ...........................................................................................7 4.3.3. Calcolo dell'SMR.............................................................................................................9 4.4. DECODIFICA................................................................................................................................10 4.5. VALUTAZIONE DELLA CODIFICA.............................................................................................10 Nel presente capitolo viene introdotta la codifica MPEG_Audio esponendone i principi di funzionamento e le possibili applicazioni, i paragrafi ne illustrano gli aspetti relativi a: •Scopo •Principi •Applicazioni MPEG (Moving Picture Expert Group) è un gruppo di lavoro composto nel 1988 con lo scopo di definire uno standard per la trasmissione di immagini e del relativo audio in formato digitale a un bitrate totale (immagini + audio) di 1.5MBit /sec. . In particolare l'audio deve essere ad una qualità paragonabile a quella del Compact Disc o DAT (Digital Audio Tape) e le immagini non devono essere peggiori di quelle di un sistema VHS. MPEG ha adottato due codifiche sintattiche indipendenti: una per l'audio ed una per le immagini. 4.1. LE CODIFICHE COMPRESSE L'audio digitale permette una gran flessibilità d'uso rispetto all'analogico ma per ottenere una buona qualità del segnale i sistemi digitali devono manipolare una notevole quantità di informazioni in tempi brevi (ad alta velocità). Ad esempio la codifica PCM (Pulse Code Modulation) richiede:
- 23. se la larghezza di banda del segnale è di 20000Hz e si vuole usare la rappresentazione PCM con un rapporto segnale-rumore (SNR) di almeno 90dB (16 Bit) è necessario una capacità di 768KBit/sec. per ogni canale monofonico: 16(Bit) *48000 (frequenza di Campionamento) = 768 000 Bit/sec. Quindi la memorizzazione in PCM necessita di costose apparecchiature e canali trasmissivi di complessa progettazione, tanto che si è dovuto ricorrere a dispositivi ottici (Compact Disc) e magnetici (DAT: Digital Audio Tape) di alta precisione mentre la distribuzione radiofonica in formato PCM rimane pressoché irrealizzabile a bassi costi. Proprio la necessità di trasmettere via radio segnali audio digitali ad alta qualità ha stimolato lo studio di codifiche per la riduzione del volume di dati pur mantenendo la qualità tipica dei sistemi PCM a 16 Bit con campionamento a 44.1 KHz (che verrà indicata come "qualità CD"). Queste codifiche sono dette di compressione perché appunto "comprimono" ovvero riducono la quantità di dati per rappresentare il segnale audio. La compressione può essere ottenuta sfruttando le capacità percettive dell'orecchio umano per ridurre in modo significativo la quantità di informazione per rappresentare il segnale audio, codificando solo quelle parti che sono realmente percepibili. In pratica tali codifiche, dette percettive, ottimizzano l'uso del mezzo sfruttando le caratteristiche del ricevitore, ottenendo la compressione del segnale. Le tecniche che soddisfano le ultime richieste sono dette tecniche di compressione percettive e permettono la riduzione di un fattore tipico di 1:4 - 1:8 della quantità di informazioni da trasmettere, abbassando significativamente la richiesta di capacità del canale e rendendo possibile la distribuzione radiofonica digitale a basso costo. Per una reale applicazione la codifica digitale deve porre riguardo alla possibilità di: -- COMPRESSIONE, per una distribuzione a bassi bitrate e quindi a bassi costi -- ALTA QUALITÀ del segnale audio, paragonabile a quella del Compact Disc -- ROBUSTEZZA, garantita anche per trasmissione a punti mobili -- FLESSIBILITÀ, per adattarsi alle diverse esigenze -- DECODIFICA IN TEMPO REALE Una codifica che soddisfa queste richieste è ad esempio la MPEG_Audio che si è distinta per la sua efficienza e flessibilità. 4.2. LA CODIFICA MPEG_Audio Negli ultimi anni in Europa sono stati finanziati diversi progetti di ricerca per definire e sviluppare codifiche efficienti dei segnali, utilizzabili per la diffusione dell'audio digitale a basso costo. Tra tutte le codifiche sviluppate si è distinta quella denominata MUSICAM (Masking pattern adapted Universal Subband Integrated Coding And Multiplexing). MUSICAM è stata definita all'interno del progetto EUREKA EU 147 da : CCETT (Centre Commun d' Ètudes de Télédiffusion et Télécommunications -Francia-) IRT (Institut fùr Rundfunktechnik -Germania-) PHILIPS Consumer Electronics (-Olanda-). il cui sviluppo è stato iniziato nel 1986 ed ha richiesto 4 anni (1987-1991) per un totale di 360 anni- uomo alla scadenza dei quali è stato deciso un ulteriore investimento in una seconda fase di due anni (1992-1994) in 170 anni-uomo per completare le specifiche, sviluppare i circuiti hardware e definire l'uso in particolari applicazioni.
- 24. La codifica MUSICAM per la sua efficienza e flessibilità è stata scelta da MPEG nei primi mesi del 1992 come base per un sistema a tre livelli di codifica dell'audio associato alle immagini, denominato MPEG_Audio. Lo standard MPEG_Audio è composto da due moduli : - CODIFICATORE - DECODIFICATORE Il formato dei dati in ingresso al codificatore e prodotti all'uscita del decodificatore sono compatibili con lo standard PCM (Pulse Code Modulation). La catena di codifica e decodifica è definita su tre livelli (layer) numerati progressivamente I, II e III (ognuno con una propria sintassi); il Layer II è noto anche con l'acronimo di MUSICAM. 4.2.1. Introduzione La compressione del segnale permette di abbassare i costi per la memorizzazione o trasmissione dell'audio digitale aprendo nuove fasce di mercato per la distribuzione di servizi audio in alta qualità su larga scala. Modello Percettivo Fig. 4.16 Principio di funzionamento della codifica MPEG_Audio. Gran parte del segnale è percettivamente irrilevante e può essere rimossa, il codificatore riduce anche una certa quantità di ridondanza che viene ricostruita nel decodificatore. Le informazioni percepibili (le uniche che devono essere trasmesse) sono solo una piccola parte di quelle contenute nella codifica PCM. La codifica percettiva si avvale delle recenti scoperte in campo psicoacustico che hanno reso possibile lo sviluppo di un modello matematico implementabile in tempo reale per il calcolo delle capacità di risoluzione dell'orecchio umano, con tale analisi si possono distinguere le informazioni udibili da quelle mascherate (perché coperte da altre componenti del segnale). 4.2.2. Caratteristiche Le caratteristiche della codifica MPEG_Audio sono: - Struttura a livelli - Tre possibili frequenze di campionamento - Modalità stereo, bilingue, mono e joint_stereo - Codifica e decodifica per vari bitrate - Basso tempo di ritardo - Accesso diretto a piccoli grani di informazione - Bassa complessità del decodificatore - Possibilità di inserimento di informazioni ausiliarie - (Possibilità di editing in forma codificata )
- 25. La codifica prevede in ingresso sequenze PCM a 16:20 Bit, tre frequenze di campionamento, bitrate variabili e la possibilità di inserire nella forma codificata dati ausiliari secondo una sintassi libera. 4.2.2.1. Layer La codifica MPEG_Audio è strutturata su tre livelli (layer) indipendenti, ognuno con una propria sintassi, le caratteristiche di ognuno di essi influiscono su: .. complessità .. fattore di compressione .. qualità a parità di compressione .. potenza di calcolo richiesta Per ogni livello si deve usare un codificatore ed il rispettivo decodificatore , lo standard impone che un co-decodificatore per il livello N operi anche su tutti i livelli inferiori ad N. La scelta del layer da usare per una particolare applicazione è funzione dei risultati che si vogliono ottenere e dalla disponibilità del canale. Layer I è appropriato per la distribuzione e registrazione domestica o per la memorizzazione su nastri o dischi magneto-ottici dove non è indispensabile un'altissimo fattore di compressione. Attualmente è usato nelle DCC (Digital-Compact-Cassette Philips). È quello più semplice e non pone particolare attenzione nel limitare ridondanza ed irrilevanza dei dati, richiede una bassa complessita di calcolo. Dal layer I è stata derivata la codifica PASC. Layer II introduce un'ulteriore compressione eliminando gran parte della ridondanza e irrilevanza del segnale. Il layer II è il più simile all'originale codifica MUSICAM. Il suo campo di applicazione è il più vasto tra i tre layer , andando dalle applicazioni domestiche ai contributi (aggiunta di commenti) di trasmissioni radiofoniche. È stato adottato come standard per la distribuzione DAB. Fornisce un ottimo rapporto complessità - qualità del risultato ed è indicato soprattutto dove è richiesto un alto fattore di compressione con risorse contenute. Layer III le sue applicazioni sono principalmente per telecomunicazioni (soprattutto a banda stretta) e nel campo dell'audio professionale con bitrate molto bassi e alti fattori di compressione. È consigliato per applicazioni che richiedono bassi bitrate (alti fattori di compressione) come per trasmissioni via satellite o per un buon uso di canali telefonici (piccola larghezza di banda). Utilizza una codifica ottimizzata (codifica di Huffmann) per la memorizzazione dei campioni quantizzati. È un compromesso tra gli aspetti migliori delle codifiche ASPEC e MUSICAM. 4.2.2.2. Frequenze di Campionamento Sono previste tre possibili frequenze di campionamento indipendentemente dal layer in uso. In particolare : 32 KHz Per compatibilità con i precedenti sistemi 44.1 KHz Per qualità CD 48 KHz Per qualità "da studio" Tab 4.4 Frequenze di campionamento utilizzabili con il sistema MPEG_Audio 32 KHz : per compatibilità con i precedenti sistemi di trasmissione ma praticamente con poche applicazioni nel futuro dell'audio digitale. È utilizzabile solo per trasmettere commenti vocali e non musicali. 44.1 KHz : usata nel Compact Disc, è stata mantenuta anche se la codifica di sequenze PCM con questa frequenza di campionamento crea alcuni problemi di sincronizzazione
- 26. per via della parte frazionaria che si ripercuote in elementi di codifica di dimensioni variabili. 48 KHz : è quella maggiormente utilizzabile per la compressione dato che è un multiplo intero delle frequenze usate nella normale distribuzione e mette a disposizione una larghezza di banda che conserva la qualità tipica degli studi di produzione. 4.2.2.3. Modalità La codifica MPEG_Audio prevede quattro modalità per la codifica di un segnale audio. Esse si distinguono dal numero di canali monofonici PCM immessi al codificatore e dalle tecniche usate nella compressione. STEREO DUAL_CHANNEL JOINT_STEREO SINGLE_CHANNEL Tab. 4.5 Modalità previste dalla codifica MPEG_Audio. La modalità deve essere compatibile con la sequenza PCM in ingresso al codificatore. 4.2.2.4. Bitrate Indica l'occupazione del canale di trasmissione da parte della sequenza codificata in termini di Bit al secondo. Il bitrate può essere scelto tra una serie di valori predefiniti dipendenti dal layer e dalla modalità audio. Bitrate Layer I Bitrate Layer II Bitrate Layer III NON SPECIFICATO NON SPECIFICATO NON SPECIFICATO 32 32 32 64 48 40 96 56 48 128 64 56 160 80 64 192 96 80 224 112 96 256 128 112 288 160 128 320 192 160 352 224 192 384 256 224 416 320 256 448 384 320 Tab. 4.6 Possibili Bitrate espressi in KBit/sec. a seconda del layer in uso. Le righe della tabella non hanno nessun rapporto con la qualità dell'audio. Il bitrate indicato è da ritenersi totale per la sequenza indipendentemente dalla modalità. Il valore NON SPECIFICATO indica che il bitrate è determinato unicamente dalla struttura della sequenza codificata ovvero dalla dimensione in bit dei FRAME. 4.2.3. Possibili Applicazioni Le caratteristiche della codifica MPEG ne fanno un valido prodotto applicabile direttamente per : - DAB (Digital Audio Broadcasting) ovvero distribuzione radiofonica digitale - Audio associato all' HDTV (Televisione ad alta Definizione) - Trasmissione di contributi (voce, parlato, commenti..... ) - Editing e postprocessing
- 27. - Memorizzazione a bassi costi - Applicazioni multi e ipermediali -Sistemi multicanale -Educazione e istruzione - Uso in campo industriale - Applicazione in sezioni di intrattenimento - Electronic publishing - Registrazione audio su dischi Winchester, magneto-ottici, - Trasmissione in banda stretta ISDN per contributi, tele o video conferenze - Distribuzione da studio ai trasmettitori e ripetitori . La codifica è usata per la distribuzione su larga scala di audio digitale nelle DCC (Digital Compact Cassette)3. 4.3. LA CODIFICA E I FRAME Il processo di codifica prende in ingresso il segnale audio sotto forma di campioni PCM e produce una sequenza compressa. La codifica rappresenta gruppi di N campioni PCM4 trasformati nel dominio della frequenza e produce un blocco di dati con una sintassi ben definita chiamato FRAME. Di seguito sono rappresentati schema e descrizione del processo di codifica: Fig. 4.17 Schema semplificato della codifica MPEG_Audio, i dati in ingresso vengono codificati a gruppi di N campioni. Il codificatore servendosi di un banco di filtri ottiene la rappresentazione frequenziale dei campioni in ingresso, mappata in 32 sottobande equi ampie. Tali campioni (detti di sottobanda) vengono quantizzati e codificati servendosi delle informazioni fornite da un modello psicoacustico che seleziona le componenti non mascherate del segnale. I dati così quantizzati e codificati possono essere inviati ad un modulo che si occupa della loro organizzazione e dell'aggiunta di informazioni di servizio (ad esempio un codice di rilevazione errori) ottenendo la definitiva sequenza compressa. Un frame viene formattato come di seguito: HEADER DATI AUDIO DATI AUSILIARI 3Supporto magnetico sviluppato dalla Philips; la codifica usata corrisponde al layer I della codifica MPEG_Audio. 4Il numero N (fisso) di campioni che vengono codificati in ogni frame dipende dal livello di compressione che si vuole ottenere.
- 28. L'efficienza del codificatore dipende principalmente dall'accuratezza del modello psicoacustico, lo standard permette l'uso di un qualsiasi modello lasciando aperta la possibilità di aggiornare il codificatore con algoritmi psicoacustici più accurati e efficienti che saranno disponibili in futuro. Ciò' che deve fare il modello psicoacustico è comunque ben definito nel fornire il rapporto SMR; Signal to Mask Ratio o differenza in dB tra il massimo segnale e il minimo livello di mascheramento per ogni canale e per ogni sottobanda. 4.3.1. La Rappresentazione Frequenziale ... divisione in sottobande La divisione in 32 sottobande è stata scelta per avvicinarsi alle capacità percettive dell'orecchio umano, tale rappresentazione offre la possibilità di una accurata analisi del segnale ed un buon compromesso per la localizzazione temporale e frequenziale. La divisione in sottobande teoricamente ottima sarebbe in 26 sottobande corrispondenti ai Bark (per frequenze di campionamento di 48KHz) e quindi di ampiezza variabile, una tale divisione richiede complessi filtri ad albero che introducono un ritardo inaccettabile per la maggior parte delle applicazioni. Il filtro che è stato adottato nella applicazione pratica è un polifase con struttura parallela che non permette bande di ampiezza variabile. I vantaggi di tale soluzione sono principalmente il basso ritardo e la bassa complessità, inoltre è un ottimo compromesso tra implementazione efficiente e adattamento alle caratteristiche percettive umane. Un buon compromesso tra risoluzione spettrale e perdita temporale dei transitori è stato trovato nel sistema MUSICAM e consiste appunto nella divisione in 32 sottobande equiampie. ... l'analisi psicoacustica La rappresentazione frequenziale del filtro polifase non è sufficientemente accurata per il calcolo della funzione di mascheramento, infatti per ottenere alti fattori di compressione è necessaria una accurata analisi delle componenti frequenziali del segnale su cui calcolare la funzione di mascheramento con l'identificazione delle componenti tonali e non tonali. 4.3.2. ... un Modello Psicoacustico Le quantità numeriche alla base dell'analisi psicoacustica sono : SNR : Signal to Noise Ratio _ Differenza in dB tra il segnale ed il rumore di quantizzazione, è un valore sempre positivo ed in prima approssimazione assume valore di 6*B dove B è il numero di bit usati per quantizzare il segnale. Il valore di SNR dipende esclusivamente dal numero di bit usati per quantizzare il segnale e quindi, solo dal valore di bit allocation. SMR : Signal to Mask Ratio _ Differenza in dB tra il segnale ed il valore di soglia di mascheramento. La soglia di mascheramento viene calcolata dal modello psicoacustico. Un valore positivo di SMR indica che il segnale è udibile, un valore negativo indica che il segnale non può essere udibile perché mascherato dalle altre componenti del segnale. MNR : Mask to Noise Ratio _Differenza in dB tra il valore di maschera e rumore di quantizzazione. Al suo valore viene dato un significato importantissimo infatti qualitativamente un valore negativo indica che nella banda il rumore di quantizzazione è udibile mentre un valore positivo indica il completo mascheramento del rumore di quantizzazione. Quantitativamente indica rispettivamente il margine in dB per elaborazioni del segnale e quanto il rumore di quantizzazione è udibile. Tra queste tre quantità vale la relazione :
- 29. MNR = SNR - SMR L'efficienza della codifica dipende principalmente dall'accuratezza dei calcoli del modello psicoacustico (che per il momento può essere visto come una sistema di calcolo che prende in ingresso 1152 campioni PCM e fornisce in uscita il valore SMR in dB per ogni banda e canale), lo standard permette l'uso di un qualsiasi modello lasciando aperta la possibilità di aggiornare il codificatore con algoritmi psicoacustici più accurati e efficienti che saranno disponibili in futuro. Si fa notare come ciò non pregiudichi il diventare obsoleto delle sequenze codificate con i precedenti algoritmi psicoacustici in quanto il processo di decodifica non dipende in nessun modo dal modello usato per la codifica. MODELLO PERCETTIVO Ingresso di 1152 campioni PCM Uscita 32 valori di SMR Fig. 4.18 Rappresentazione schematica della funzione svolta dal modello percettivo per ogni canale monofonico. La relazione esistente tra i valori SNR, SMR, MNR in ogni sottobanda può essere illustrata graficamente come segue: Segnale Maschera Noise SMR ( b_a) MNR = SNR - SMR SNR [quant] Fig. 4.19 Diagramma dei valori qualitativamente ottimali di Segnale, Maschera e Rumore. Nella figura si evidenzia il fatto che l'SMR. influenza direttamente il valore della BIT_ALLOCATION e che l'SNR dipende unicamente dal numero di livelli di quantizzazione assegnati alla sottobanda. Dal valore di SMR può essere ottimizzata l'allocazione dei campioni audio di sottobanda sfruttando la considerazione che è del tutto inutile quantizzare su un numero di livelli che introduca un rumore di quantizzazione molto inferiore al rumore già presente (per caratteristica del segnale) in ogni sottobanda; dove per rumore si intende tutto il segnale sotto la soglia di mascheramento5. Infatti ogni segnale che è sotto la soglia di mascheramento non può essere percepito in nessun modo e quindi è irrilevante ai fini della riproduzione sonora. In tal senso può essere giustificata la quantizzazione dinamica dei campioni di sottobanda che mantiene il Rapporto Segnale Rumore (SNR) (funzione del numero di bit usati per la quantizzazione) dipendente dal valore tra Segnale e Maschera (SMR). È dunque sufficiente quantizzare i campioni in ogni banda con un numero di bit tale che 5Si ricorda che il rapporto SNR aumenta di circa 6 dB per ogni bit in più usato per la quantizzazione.
- 30. SNR > SMR La qualità dell'audio ed il margine per compiere dell'editing audio è tanto maggiore quanto più la differenza MNR = SNR - SMR è grande e ciò dipende unicamente dal numero di bit disponibili per codificare i 1152 campioni ovvero dalla dimensione del FRAME (modalità audio e bitrate). Una allocazione è ottima se riesce ad ottenere valori di MNR>0 per tutte le sottobande con segnale udibile. Ovviamente dato che il Frame ha una dimensione fissa non è detto che si riesca a raggiungere tale situazione oppure se si riesce a raggiungerla può accadere che rimangono disponibili altri bit che possono essere allocati in modo inoffensivo per aumentare ulteriormente il valore di MNR in tutte le sottobande. 4.3.3. Calcolo dell'SMR L'algoritmo per il calcolo dei valori di SMR esegue una analisi psicoacustica delle componenti frequenziali del segnale e fornisce in uscita il valore SMR per ogni sottobanda e ogni canale del segnale audio. Il valore SMR è dato dalla differenza tra il massimo livello del segnale ed il minimo della soglia di mascheramento in ogni sottobanda. Banda N-1 Banda N Banda N+1 dB SPL Minimo della soglia nella banda Massimo segnale nella banda SMR Banda N Funzione di mascheramento Soglia statica Soglia statica Soglia statica A B C = D EF Funzione di eccitazione G Fig. 4.20 Rappresentazione schematica del calcolo dell'SMR nella generica banda N: A - funzione di mascheramento B - minimo della funzione di mascheramento C - minimo della soglia statica D - massimo tra i due valori dei punti B e C E - massimo livello del segnale F - valore di SMR. G - impulso di eccitazione Il valore di SMR serve per stabilire la quantità di bit necessari per quantizzare i campioni di sottobanda sfruttando il fatto che è percettivamente ininfluente ottenere un livello di SNR superiore al valore di MNR. Nel modello psicoacustico 1 (proposto da MPEG) il calcolo dell' SMR procede come di seguito: 1.. Calcolo della FFT per la rappresentazione frequenziale dei campioni PCM 2.. Calcolo livello del segnale (in deciBel SPL) in ogni sottobanda 3.. Confronto con la soglia statica in quiete (tabulata) 4.. Identificazione delle componenti tonali (simili al seno) e non tonali (simili a rumore)
- 31. 5.. Decimazione dei toni di mascheramento per ottenerne solo i rilevanti 6.. Calcolo soglia di mascheramento individuale per ogni componente spettrale 7.. Calcolo soglia globale 8.. Calcolo minimo della soglia di mascheramento in ogni sottobanda 9.. Calcolo dell'SMR in ogni sottobanda. 4.4. DECODIFICA Il processo di decodifica prende in ingresso un file codificato contenente audio compresso e lo elabora per ottenere il segnale originale sotto forma di campioni PCM. Segue lo schema del processo di decodifica: Fig. 2.21 Schema semplificato di decodifica MPEG_Audio La sequenza inviata al decodificatore viene depaccata e ne viene controllata la consistenza (se c'è protezione errori). Se vengono rilevati degli errori si possono intraprendere azioni per minimizzarne l'effetto. Si dividono poi i campioni audio (quantizzati) dalle informazioni per la loro ricostruzione. La ricostruzione vera e propria consiste nel dequantizzare e denormalizzare i campioni di sottobanda, da tali campioni si ottiene l'originaria forma PCM. La decodifica non richiedendo nessuna analisi psicoacustica del segnale è a bassa complessità. Ogni valore di BIT_ALLOCATION si riferisce a tutti i 36 campioni di ogni sottobanda. 4.5. VALUTAZIONE DELLA CODIFICA Test soggettivi condotti con un campione di ascoltatori esperti hanno valutato la qualità e fedeltà della compressione per diversi valori di bitrate. L' EBU (European Broadcasting Union) definisce la qualità dell'audio per la distribuzione su larga scala: "La qualità del segnale audio riprodotto dopo la decodifica dovrebbe essere indistinguibile rispetto alla qualità ottenibile da un Compact disc. In pratica questo implica comparare il segnale analogico in uscita dal decodificatore con un segnale di riferimento riprodotto da un sistema lineare a 16 Bit, mediante un doppio test cieco del tipo A_B_C con caratteristiche dei due segnali nascoste per la valutazione soggettiva. Il co-decodificatore è giudicato accettabile se il risultato della valutazione delle sequenze sonore su una scala a 5 gradi di giudizio (scala CCIR) mostra una coincidenza dell'intervallo di fiducia del 95 % del segnale originale e del decodificato. Il test deve essere eseguito su segnali critici e la coincidenza deve avvenire per almeno il 70 % delle sequenze sonore." La codifica MPEG_Audio rispetta questi requisiti di qualità con un fattore di compressione 4 al layer I, 6 al layer II e 8 al layer III. Come considerazione generale, la qualità in ascolto di una sequenza decodificata sarà tanto più simile all'originaria tanto più: - il bitrate disponibile per la codifica è alto - la qualità dell'audio originale è buona - il modello percettivo usato è accurato
- 32. GLOSSARIO bit_allocation : struttura contenente informazioni sul numero di livelli di quantizzazione dei campioni di ogni sottobanda bit_allocation adattativa : assegnazione di bit alle sottobande in modo variabile nella frequenza e nel tempo secondo il risultato del modello psicoacustico. bitrate: velocità con cui la sequenza codificata MPEG viene trasmessa dal mezzo di memorizzazione al decodificatore (espressa in Bit al secondo) bound: piu' piccola sottobanda in cui si usa la codifica joint stereo. canale[1]: mezzo digitale che memorizza o trasporta una sequenza MPEG-Audio canale[2]: porzione del segnale audio riguardante solo la parte destra o sinistra di una sequenza stereo, dual_channel o Joint_stereo. CRC: [Cyclic Redundancy Code] codice ridondante per la rilevazione di errori. codificatore: corpo del processo di codifica. decodificatore: corpo del processo di decodifica. frame: unità base della sequenza MPEG che corrisponde alla codifica di un numero fisso di campioni PCM. granulo: per il layer II un granulo è l'insieme di 12 gruppi di 3 campioni della stessa sottobanda , sono 36 campioni all'interno della stessa sottobanda. gruppo : insieme di tre campioni frequenziali successivi della stessa sottobanda; i gruppi di campioni sono usati per sfruttare al meglio il mezzo di memorizzazione se il numero di passi di quantizzazione non è una potenza di due.
- 33. intensity_stereo: metodo per eliminare l'irrilevanza e la ridondanza presente nei segnali stereofonici basata sul fatto che alle alte frequenze è rilevante solo l'inviluppo dell'energia dei canali destro e sinistro. Joint_stereo [codifica]: Qualsiasi metodo che elimina parte della irrilevanza e ridondanza dei segnali stereo. Joint_stereo [modo]: modalita dell'algoritmo di codifica che usa una codifica Joint_stereo layer: uno dei livelli della gerarchia di codifica definiti dallo Standard mascheramento: proprietà del sistema uditivo umano secondo cui un segnale audio non può essere percepito in presenza di un segnale mascherante modello psicoacustico: modello matematico per la rappresentazione delle capacità di mascheramento dell'orecchio umano MS_stereo: modalità di codifica per eliminare irrilevanza e ridondanza di segnali stereofonici basata sulla memorizzazione della somma e differenza dei segnali. padding: informazione binaria per adattare la dimensione media dei frame audio usando uno slot addizionale processo di codifica: processo di lettura di campioni audio e produzione della forma codificata definita dallo standard ISO (il metodo di costruzione non è però totalmente standardizzato) processo di decodifica: processo definito dall'ISO che legge un codice in ingresso e produce in uscita campioni audio decodificati. scfsi (Struttura Codifica Fattori di Scala su Intervalli) : struttura usata per codificare i fattori di scala eliminandone parte irrilevante (anche percettivamente) sequenza decodificata: sequenza ricostruita da una forma compressa MPEG. slot: parte elementare della sequenza codificata. Nel layer I equivale a 4 Byte ; nei layer II e III a 1 Byte soglia di mascheramento: funzione nei domini di frequenza e tempo che rappresenta il limite inferiore dei segnali udibili dall'orecchio umano.
- 35. BIBLIOGRAFIA [Aarts] R. M. Aarts "Calculation of the loudness of loudspeakers during listening tests" Journal of the Audio Engineering Society, Vol.39 No.1, 1991. [Blesser] B. A. Blesser "Digitization of audio : A comprehensive examination of theory, implementation, and current practice" Journal of the Audio Engineeering Society, Vol.26 No.10, 1978. [CCETT] CCETT, IRT, PHILIPS "MUSICAM: High quality audio bit-rate reduction system family for different applications" Presented at IEEE International Conference on Communications, 1990. [Cosa] M. Cosa "Inquinamento da rumore" La Nuova Italia Scientifica, 1992. [Dehery] Y. F. Dehery "Musicam source coding" AES 10th International Conference, 1990. [Gold] B. Gold, L. Rabiner "Theory and application of digital signal processing" Prentice Hall, 1975. [Kapust] R. Kapust "A human ear related objective measurement technique yields audible error and error margin" AES 11th International Conference, 1991. [Lazzarin] R. Lazzarin , M. Strada "Elementi di acustica tecnica" CLUEP Padova, 1992. [Moore] B. C. J. Moore "An introduction to the Psychology of hearing" Third Edition, Harcourt Brace Jovanovich Publishers, 1978. [MPEG-A] ISO - International Organization for Standardization References MPEG Audio 3-11172 rev.3 ISO/IEC/JTC1/SC29/WG11 MPEG_Audio, 1991. [Mùller] F. Mùller-Ròmer "Directions in digital audio broadcasting" Journal of the Audio Engineering Society, Vol.41 No.3, 1993. [Pohlmann] K. C. Pohlmann "Principles of digital audio" Third printing, Howard W.Sams & Co., 1987. [Shafer] A. V. Oppenheim, R. W.Shafer "Elaborazione numerica dei segnali" Franco Angeli editore, 1981.
- 36. [Stoll] G. Stoll "Source coding for DAB and the evaluation of its performance: A major application of the new ISO audio coding standard" Presented at the EBU First International Symposium of Digital Audio Broadcasting, 1992. [Theile] G. Theile, G. Stoll, M. Link "Low bit-rate coding of high-quality audio signals. An introduction to the MASCAM system" EBU Review Technical , No.230, 1988. [Wiese] D. Wiese, G. Stoll "Bitrate reduction of high quality audio signals by modelling the ears masking theresholds" Presented at the 89th AES Convention, 1990. [Zwicker] E. Zwicker, U. T. Zwicker "Audio engineering and psychoacoustics: matching signals to the final receiver, the human auditory system" Journal of the Audio Engineeering Society, Vol.39 No.3, 1991.