Can we keep the cost of analysis of haloacetic acids (HAAs) down by using an ...
hw5report
1. Abstract:
I have createdthisreportto examine qualitypropertiesfromawine dataset.Thiswine datasetis
focusedona wine vineyardfrom portugual calledvinhoverde. Thisvineyardcreatesaclassof wines
that are consideredextrodinary exceptinthe eyesof the French.Thisdatasetcontainsalarge sample
(over1000 observations) inwhichexpertwine tastersprovidefeedbackonthe qualityof the redwines
producedbyvinhoverde.These qualityratingsare attachedtothe individual red winequantitative
charactersiticsthatare trackedthroughoutthe productionof eachindividual bottle of theirredwine.
Thisdatasetcontains12 quantitative variablesthathave beendeterminedtodefine quality
characteristicsof a bottle of wine. Iam usingthe dependentvariablequalityandthe independent
variablesare: fixed_acidity volatile_acidity citric_acid residual_sugar
chlorides free_sulfur_dioxide total_sulfur_dioxide density pH sulphates and
alcohol content. These independent variables have been predertermined to
define the final taste of a wine. From this context I want to create a model
that can show what quantitative characteristics are associated with the
dependent variable quality wines. To me wine is an interesting subject I am
currently taking the wine class offered at KSU and this is where I fell in
love with Vinho Verde wines and I hope to one day be able to make my own
wines so if I can create a model that can quantify and key in on the
characteristics that I like about this wine then I feel that this modeling
information will give me great insight into quality wine characteristics.
This dataset comes from a website called
https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/ that
is a database dedicated to free datasets that are useful from around the
world.
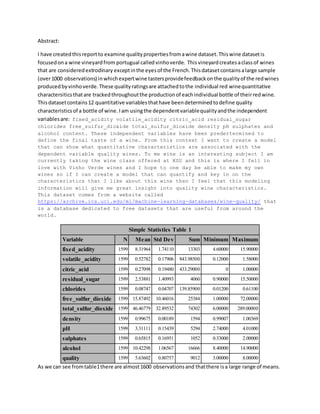
Simple Statistics Table 1
Variable N Mean Std Dev Sum Minimum Maximum
fixed_acidity 1599 8.31964 1.74110 13303 4.60000 15.90000
volatile_acidity 1599 0.52782 0.17906 843.98500 0.12000 1.58000
citric_acid 1599 0.27098 0.19480 433.29000 0 1.00000
residual_sugar 1599 2.53881 1.40993 4060 0.90000 15.50000
chlorides 1599 0.08747 0.04707 139.85900 0.01200 0.61100
free_sulfur_dioxide 1599 15.87492 10.46016 25384 1.00000 72.00000
total_sulfur_dioxide 1599 46.46779 32.89532 74302 6.00000 289.00000
density 1599 0.99675 0.00189 1594 0.99007 1.00369
pH 1599 3.31111 0.15439 5294 2.74000 4.01000
sulphates 1599 0.65815 0.16951 1052 0.33000 2.00000
alcohol 1599 10.42298 1.06567 16666 8.40000 14.90000
quality 1599 5.63602 0.80757 9012 3.00000 8.00000
As we can see fromtable1there are almost1600 observationsand thatthere isa large range of means.
2. Analysis of Variance Table2
Source DF
Sum of
Squares
Mean
Square F Value Pr > F
Model 11 375.75440 34.15949 81.35 <.0001
Error 1587 666.41070 0.41992
Corrected Total 1598 1042.16510
Root MSE 0.64801 R-Square 0.3606
Dependent Mean 5.63602 Adj R-Sq 0.3561
CoeffVar 11.49767
Parameter Estimates Table3
Variable DF
Parameter
Estimate
Standard
Error t Value Pr > |t|
Variance
Inflation
Intercept 1 21.96521 21.19457 1.04 0.3002 0
fixed_acidity 1 0.02499 0.02595 0.96 0.3357 7.76751
volatile_acidity 1 -1.08359 0.12110 -8.95 <.0001 1.78939
citric_acid 1 -0.18256 0.14718 -1.24 0.2150 3.12802
residual_sugar 1 0.01633 0.01500 1.09 0.2765 1.70259
chlorides 1 -1.87423 0.41928 -4.47 <.0001 1.48193
free_sulfur_dioxide 1 0.00436 0.00217 2.01 0.0447 1.96302
total_sulfur_dioxide 1 -0.00326 0.00072873 -4.48 <.0001 2.18681
density 1 -17.88116 21.63310 -0.83 0.4086 6.34376
pH 1 -0.41365 0.19160 -2.16 0.0310 3.32973
sulphates 1 0.91633 0.11434 8.01 <.0001 1.42943
alcohol 1 0.27620 0.02648 10.43 <.0001 3.03116
For the First Model that I want to introduce I created a simple first order model wheras quality is my
dependent variable and my independent variables are fixed_acidity volatile_acidity citric_acid
residual_sugar chlorides free_sulfur_dioxide total_sulfur_dioxide density pH sulphates and alcohol
content. My hypothesis test is that I can build a model that shows the chemical characteristics of these
independent variable is correlated to the variable quality. If we take a look at table 2 we can see that there
is a the overall global f test shows that this model overall could be useful but I am concerned because the
adjusted r value is relatively low at 36%. This means that while the overall model maybe usefull there
could be some independent variables that attribute to the quality variable not accounted for in this model.
I have set my alpha level at 90% and when we take a look at table 3 there are7 independent variables that
I will include into my model volatile_acidity chlorides free_sulfur_dioxide total_sulfur_dioxide ph
sulphates and alcohol.Before model we must take a look at table3 and see if there is any potential
multicollinearity. Based on the VIF from table3 none of the variables have a VIF greater than 10 so there
is not potential multicollinarity concerns in this model so my proposed model is :
3. Quality= 21.96521-1.08359vc-1.87423chl+0.00436freesulfur-0.00326totalsulfur-
0.41365ph+0.91633sulphates+0.27620alcohol
Model 2.
This next model I want to use the model format from the previous selection where quality is my dependent and
fixed_acidity volatile_acidity citric_acid residual_sugar chlorides free_sulfur_dioxide
total_sulfur_dioxide density pH sulphates and alcohol content are still my independent but I want to
perform stepwise regression modeling techniques to see if I missed a potential independent variable that
could be useful in my model. Based on table5 the stepwise selection procedure reported the same
findings which were reported in model 1.
Analysis of Variance table 4
Source DF
Sum of
Squares
Mean
Square F Value Pr > F
Model 7 374.62804 53.51829 127.55 <.0001
Error 1591 667.53706 0.41957
Corrected Total 1598 1042.16510
Variable Table 5
Parameter
Estimate
Standard
Error Type II SS F Value Pr > F
Intercept 4.43010 0.40292 50.72257 120.89 <.0001
volatile_acidity -1.01275 0.10084 42.31760 100.86 <.0001
chlorides -2.01781 0.39754 10.80941 25.76 <.0001
free_sulfur_dioxide 0.00508 0.00213 2.39413 5.71 0.0170
total_sulfur_dioxide -0.00348 0.00068678 10.78662 25.71 <.0001
pH -0.48266 0.11756 7.07271 16.86 <.0001
sulphates 0.88267 0.10991 27.06045 64.50 <.0001
alcohol 0.28930 0.01680 124.48286 296.69 <.0001
Model 3:
In this model I want to hypothesis that when I transform quality by only modeling high quality wines
which I define as a rating of 7 or higher on a scale of 1-10 that I can create a model that indicates what
chemical characteristics from the list of independent variables of these high quality wines can be looked
at as significant in modeling quality. If we take at look at table 6 we see that the global test barely fails at
the .10 alpha level I have set. With this inmind and the very low adjusted r squared at 11% I feel that this
4. model will not be helpful in predicting high quality wine. If we move down to table7 we see that the only
independent variable that is usefull is alcohol at the .10 alpha level. This is an interesting result I was
expecting a quite different result. With all of this information in mind I will reject this model and say that
it will not be useful without further data mining.
Analysis of Variance table 6
Source DF
Sum of
Squares
Mean
Square F Value Pr > F
Model 5 0.68367 0.13673 1.82 0.1095
Error 211 15.82324 0.07499
Corrected Total 216 16.50691
Root MSE 0.27385 R-Square 0.0414
Dependent Mean 7.08295 Adj R-Sq 0.0187
CoeffVar 3.86627
Parameter Estimates table7
Variable DF
Parameter
Estimate
Standard
Error t Value Pr > |t|
Variance
Inflation
Intercept 1 6.45590 0.26363 24.49 <.0001 0
volatile_acidity 1 0.09276 0.13284 0.70 0.4858 1.06803
chlorides 1 -0.67390 0.69427 -0.97 0.3328 1.12612
total_sulfur_dioxide 1 -0.00042984 0.00059115 -0.73 0.4680 1.06790
sulphates 1 0.16542 0.14371 1.15 0.2510 1.06872
alcohol 1 0.04624 0.01925 2.40 0.0172 1.06345
libname hw5 "ClientC$UsersJeanDesktophw5";
data hw5.redwine;
Infile "ClientC$UsersJeanDesktophw5redwine.csv" dsd dlm=
";";
input fixed_acidity volatile_acidity citric_acid residual_sugar
chlorides free_sulfur_dioxide total_sulfur_dioxide density pH sulphates
alcohol quality;
RUN;
ods rtf;
proc contents data=hw5.redwine;
run;
Proc means data=hw5.redwine;
run;
5. proc corr data=hw5.redwine plots=matrix;
var fixed_acidity volatile_acidity citric_acid residual_sugar chlorides
free_sulfur_dioxide total_sulfur_dioxide
density pH sulphates alcohol quality;
run;
proc reg data= hw5.redwine;
model quality=fixed_acidity volatile_acidity citric_acid residual_sugar
chlorides free_sulfur_dioxide total_sulfur_dioxide
density pH sulphates alcohol /vif;
run;
quit;
*stepwise selection;
proc reg data= hw5.redwine;
model quality=fixed_acidity volatile_acidity citric_acid residual_sugar
chlorides free_sulfur_dioxide total_sulfur_dioxide
density pH sulphates alcohol /selection=stepwise sle=0.1 sls=0.1;
run;
quit;
proc reg data=hw5.redwine1;
model quality= volatile_acidity chlorides total_sulfur_dioxide sulphates
alcohol /selection=stepwise sle=0.1 sls=0.1;
run;
proc reg data=hw5.redwine1;
model quality= volatile_acidity chlorides total_sulfur_dioxide sulphates
alcohol /vif;
run;
ods rtf close;
data hw5.redwine2;
set hw5.redwine1;
va2= volatile_acidity*volatile_acidity;
chl2=chlorides*chlorides;
tsd2=total_sulfur_dioxide*total_sulfur_dioxide;
sul2=sulphates*sulphates;
alc2=alcohol*alcohol;
run;
proc reg data=hw5.redwine2;
model quality= volatile_acidity chlorides total_sulfur_dioxide sulphates
alcohol va2 chl2 tsd2 sul2 alc2 /vif;
run;
proc reg data= hw5.redwine;
model alcohol=fixed_acidity volatile_acidity citric_acid residual_sugar
chlorides free_sulfur_dioxide total_sulfur_dioxide density pH sulphates
/vif;
run;
quit;
graph to show interaction effect;
data hw5.redwine1;
set hw5.redwine;
if quality >= 7 then qualityindex='1';
if quality<7 then delete;
*if numbids=10 then delete;
run;
6. proc gplot data=sherry.gfclocks2;
plot price*age=bid_group;
proc reg data=sherry.exesal2;
model y = x1-x10 /selection=stepwise sle=0.1 sls=0.1;
run;
quit;