Downloaded 212 times



![CAPITOLUL I
DESCRIEREA ALGORITMILOR
1.1 Algoritm, program, programare
Apariţia primelor calculatoare electronice a constituit un salt uriaş în direcţia automatizării
activităţii umane. Nu există astăzi domeniu de activitate în care calculatorul să nu îşi arate utilitatea[18].
Calculatoarele pot fi folosite pentru a rezolva probleme, numai dacă pentru rezolvarea acestora se
concep programe corespunzătoare de rezolvare. Termenul de program (programare) a suferit schimbări în
scurta istorie a informaticii. Prin anii '60 problemele rezolvate cu ajutorul calculatorului erau simple şi se
găseau algoritmi nu prea complicaţi pentru rezolvarea lor. Prin program se înţelegea rezultatul scrierii
unui algoritm într-un limbaj de programare. Din cauza creşterii complexităţii problemelor, astăzi pentru
rezolvarea unei probleme adesea vom concepe un sistem de mai multe programe.
Dar ce este un algoritm? O definiţie matematică, riguroasă, este greu de dat, chiar imposibilă fără
a introduce şi alte noţiuni. Vom încerca în continuare o descriere a ceea ce se înţelege prin algoritm.
Ne vom familiariza cu această noţiune prezentând mai multe exemple de algoritmi şi observând ce
au ei în comun. Cel mai vechi exemplu este algoritmul lui Euclid, algoritm care determină cel mai mare
divizor comun a două numere naturale. Evident, vom prezenta mai mulţi algoritmi, cei mai mulţi fiind
legaţi de probleme accesibile absolvenţilor de liceu.
Vom constata că un algoritm este un text finit, o secvenţă finită de propoziţii ale unui limbaj. Din
cauză că este inventat special în acest scop, un astfel de limbaj este numit limbaj de descriere a
algoritmilor. Fiecare propoziţie a limbajului precizează o anumită regulă de calcul, aşa cum se va
observa atunci când vom prezenta limbajul Pseudocod.
Oprindu-ne la semnificaţia algoritmului, la efectul execuţiei lui, vom observa că fiecare algoritm
defineşte o funcţie matematică. De asemenea, din toate secţiunile următoare va reieşi foarte clar că un
algoritm este scris pentru rezolvarea unei probleme. Din mai multe exemple se va observa însă că, pentru
rezolvarea aceleaşi probleme, există mai mulţi algoritmi.
Pentru fiecare problemă P există date presupuse cunoscute (date iniţiale pentru algoritmul
corespunzător, A) şi rezultate care se cer a fi găsite (date finale). Evident, problema s-ar putea să nu aibă
sens pentru orice date iniţiale. Vom spune că datele pentru care problema P are sens fac parte din
domeniul D al algoritmului A. Rezultatele obţinute fac parte dintr-un domeniu R, astfel că executând
algoritmul A cu datele de intrare x∈D vom obţine rezultatele r∈R. Vom spune că A(x)=r şi astfel
algoritmul A defineşte o funcţie
A : D ---> R .
Algoritmii au următoarele caracteristici: generalitate, finitudine şi unicitate.
Prin generalitate se înţelege faptul că un algoritm este aplicabil pentru orice date iniţiale x∈D.
Deci un algoritm A nu rezolvă problema P cu nişte date de intrare, ci o rezolvă în general, oricare ar fi
aceste date. Astfel, algoritmul de rezolvare a unui sistem liniar de n ecuaţii cu n necunoscute prin metoda
lui Gauss, rezolvă orice sistem liniar şi nu un singur sistem concret.
Prin finitudine se înţelege că textul algoritmului este finit, compus dintr-un număr finit de
propoziţii. Mai mult, numărul transformărilor ce trebuie aplicate unei informaţii admisibile x∈D pentru a
obţine rezultatul final corespunzător este finit.
Prin unicitate se înţelege că toate transformările prin care trece informaţia iniţială pentru a obţine
rezultatul r∈R sunt bine determinate de regulile algoritmului. Aceasta înseamnă că fiecare pas din
execuţia algoritmului dă rezultate bine determinate şi precizează în mod unic pasul următor. Altfel spus,
ori de câte ori am executa algoritmul, pornind de la aceeaşi informaţie admisibilă x∈D, transformările
prin care se trece şi rezultatele obţinute sunt aceleaşi.
În descrierea algoritmilor se folosesc mai multe limbaje de descriere, dintre care cele mai des
folosite sunt:
- limbajul schemelor logice;
6](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-4-2048.jpg)




![programare propriu-zisă acestor propoziţii le corespund într-un limbaj de programare instrucţiuni de
intrare-ieşire.
Propoziţia CITEŞTE se foloseşte pentru precizarea datelor iniţiale, deci a datelor considerate
cunoscute în problemă (numite şi date de intrare) şi are sintaxa:
CITEŞTE listă ;
unde listă conţine toate numele variabilelor a căror valoare iniţială este cunoscută.
Deci în propoziţia CITEŞTE, în dreapta acestui cuvânt se vor scrie acele variabile care apar în
propoziţia DATE în specificarea problemei. Se subînţelege că aceste variabile sunt iniţializate cu valorile
cunoscute corespunzătoare.
Pentru aflarea rezultatelor dorite, pe care calculatorul o va face prin tipărirea lor pe hârtie sau
afişarea pe ecran, se foloseşte propoziţia standard
TIPĂREŞTE listă ;
în construcţia listă ce urmează după cuvântul TIPĂREŞTE fiind trecute numele variabilelor a căror
valori dorim să le aflăm. Ele sunt de obicei rezultatele cerute în problemă, specificate şi în propoziţia
REZULTATE.
Blocului de atribuire dintr-o schemă logică îi corespunde în Pseudocod propoziţia standard
[FIE] var := expresie ;
Această propoziţie este folosită pentru a indica un calcul algebric, al expresiei care urmează după
simbolul de atribuire ":=" şi de atribuire a rezultatului obţinut variabilei var. Expresia din dreapta
semnului de atribuire poate fi orice expresie algebrică simplă, cunoscută din manualele de matematică din
liceu şi construită cu cele patru operaţii: adunare, scădere, înmulţire şi împărţire (notate prin caracterele +,
-, *, respectiv /).
Prin scrierea cuvântului FIE între paranteze drepte se indică posibilitatea omiterii acestui cuvânt
din propoziţie. El s-a folosit cu gândul ca fiecare propoziţie să înceapă cu un cuvânt al limbii române care
să reprezinte numele propoziţiei. De cele mai multe ori vom omite acest cuvânt. Atunci când vom scrie
succesiv mai multe propoziţii de atribuire vom folosi cuvântul FIE numai în prima propoziţie, omiţându-l
în celelalte.
Din cele scrise mai sus rezultă că o variabilă poate fi iniţializată atât prin atribuire (deci dacă este
variabila din stânga semnului de atribuire :=) cât şi prin citire (când face parte din lista propoziţiei
CITEŞTE). O greşeală frecventă pe care o fac începătorii este folosirea variabilelor neiniţializate.
Evident că o expresie în care apar variabile care nu au valori nu poate fi calculată, ea nu este definită.
Deci nu folosiţi variabile neiniţializate.
Pentru a marca începutul descrierii unui algoritm vom folosi propoziţia:
ALGORITMUL nume ESTE:
fără a avea o altă semnificaţie. De asemenea, prin cuvântul SFALGORITM vom marca sfârşitul unui
algoritm.
Algoritmii care pot fi descrişi folosind numai propoziţiile prezentate mai sus se numesc algoritmi
liniari.
Ca exemplu de algoritm liniar prezentăm un algoritm ce determină viteza v cu care a mers un
autovehicul ce a parcurs distanţa D în timpul T.
ALGORITMUL VITEZA ESTE: { A1: Calculează viteza }
{ D = Distanţa (spaţiul) }
{ T = Timpul; V = Viteza }
CITEŞTE D,T; { v:= spaţiu/timp }
FIE V:=D/T;
TIPĂREŞTE V
SFALGORITM
11](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-9-2048.jpg)

![1.3.3 Algoritmi ciclici
În rezolvarea multor probleme trebuie să efectuăm aceleaşi calcule de mai multe ori, sau să
repetăm calcule asemănătoare. De exemplu, pentru a calcula suma a două matrice va trebui să adunăm un
element al primei matrice cu elementul de pe aceeaşi poziţie din a doua matrice, această adunare
repetându-se pentru fiecare poziţie. Alte calcule trebuiesc repetate în funcţie de satisfacerea unor condiţii.
În acest scop în limbajul Pseudocod există trei propoziţii standard: CÂTTIMP, REPETĂ şi PENTRU.
Propoziţia CÂTTIMP are sintaxa CÂTTIMP cond EXECUTĂ A SFCÂT
i cere execuţia repetată a grupului de propoziţii A, în funcţie de condiţia "cond". Mai exact, se evaluează
condiţia "cond"; dacă aceasta este adevărată se execută grupul A şi se revine la evaluarea condiţiei. Dacă
ea este falsă execuţia propoziţiei se termină şi se continuă cu propoziţia care urmează după SFCÂT. Dacă
de prima dată condiţia este falsă grupul A nu se va executa niciodată, altfel se va repeta execuţia grupului
de propoziţii A până când condiţia va deveni falsă. Din cauză că înainte de execuţia grupului A are loc
verificarea condiţiei, această structură se mai numeşte structură repetitivă condiţionată anterior. Ea
reprezintă structura repetitivă prezentată în figura 1.3.1.c.
Ca exemplu de algoritm în care se foloseşte această propoziţie dăm algoritmul lui Euclid pentru
calculul celui mai mare divizor comun a două numere.
ALGORITMUL Euclid ESTE: {A3: Cel mai mare divizor comun}
CITEŞTE n1,n2; {Cele două numere a căror divizor se cere}
FIE d:=n1; i:=n2;
CÂTTIMP i≠0 EXECUTĂ
r:=d modulo i; d:=i; i:=r
SFCÂT
TIPĂREŞTE d; { d= cel mai mare divizor comun al }
SFALGORITM { numerelor n1 şi n2 }
În descrierea multor algoritmi se întâlneşte structura repetitivă condiţionată posterior:
REPETĂ A PÂNĂ CÂND cond SFREP
structură echivalentă cu: CÂTTIMP not(cond) EXECUTĂ A SFCÂT
Deci ea cere execuţia necondiţionată a lui A şi apoi verificarea condiţiei "cond". Va avea loc
repetarea execuţiei lui A până când condiţia devine adevărată. Deoarece condiţia se verifică după prima
execuţie a grupului A această structură este numită structura repetitivă condiţionată posterior, prima
execuţie a blocului A fiind necondiţionată.
O altă propoziţie care cere execuţia repetată a unei secvenţe A este propoziţia
PENTRU c:=li ;lf [;p] EXECUTĂ A SFPENTRU
Ea defineşte structura repetitivă predefinită, cu un număr determinat de execuţii ale grupului de
propoziţii A şi este echivalentă cu secvenţa
c:=li ; final:=lf ;
REPETĂ
A
c:=c+p
PÂNĂCÂND (c>final şi p>0) sau (c<final şi p<0) SFREP
Se observă că, în sintaxa propoziţiei PENTRU, pasul p este închis între paranteze drepte. Prin
aceasta indicăm faptul că el este opţional, putând să lipsească. În cazul în care nu este prezent, valoarea
lui implicită este 1.
Semnificaţia propoziţiei PENTRU este clară. Ea cere repetarea grupului de propoziţii A pentru
toate valorile contorului c cuprinse între valorile expresiilor li şi lf (calculate o singură dată înainte de
începerea ciclului), cu pasul p. Se subînţelege că nu trebuie să modificăm valorile contorului în nici o
propoziţie din grupul A. De multe ori aceste expresii sunt variabile simple, iar unii programatori modifică
în A valorile acestor variabile, încălcând semnificaţia propoziţiei PENTRU. Deci, nu recalcula limitele
şi nu modifica variabila de ciclare (contorul) în interiorul unei structuri repetitive PENTRU).
13](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-11-2048.jpg)






![DACĂ ind=0 ATUNCI k:=k+1; rk:=bj SFDACĂ
SFPENTRU
SF-REUNIUNE
SUBPROGRAMUL TIPMUL(n,M) ESTE: { Tipăreşte cele n elemente }
PENTRU i:=1;n EXECUTĂ { ale mulţimii M }
TIPĂREŞTE mi
SFPENTRU
SF-TIPMUL
SUBPROGRAMUL TIPORDON(n,M) ESTE: { Ordonează şi tipăreşte }
CHEAMĂ ORDON(n,M); { elementele mulţimii M }
CHEAMĂ TIPMUL(n,M);
SF-TIPORDON
Tot ca exemplu de folosire a SUBPROGRAMilor, vom scrie un algoritm pentru rezolvarea
următoarei probleme:
dirigintele unei clase de elevi doreşte să obţină un clasament al elevilor în funcţie de media generală. În
plus, pentru fiecare disciplină în parte doreşte lista primilor şase elevi.
În rezolvarea acestei probleme este necesară găsirea ordinii în care trebuiesc tipăriţi elevii în
funcţie de un anumit rezultat: nota la disciplina "j", sau media generală. Am identificat prin urmare două
subprobleme independente, referitoare la:
(1) aflarea ordinii în care trebuie tipărite n numere pentru a le obţine ordonate;
(2) tipărirea elevilor clasei într-o anumită ordine.
Prima subproblemă se poate specifica astfel:
Dându- se numerele x1, x2, ... , xn, găsiţi ordinea o1, o2, ..., on, în care aceste numere devin ordonate
descrescător, adică
x[o1] ≥ x[o2] ≥ ... x[on] .
Pentru rezolvarea ei vom da un SUBPROGRAM ORDINE în care intervin trei parametri formali:
- n, numărul valorilor existente;
- X, vectorul acestor valori;
- O, vectorul indicilor care dau ordinea dorită.
Primii doi parametri marchează datele presupuse cunoscute, iar al treilea, rezultatele calculate de
SUBPROGRAM.
SUBPROGRAMUL ORDINE(n,X,O) ESTE:
{n, numărul valorilor existente}
{X, vectorul acestor valori}
{O, vectorul indicilor care dau ordinea dorită}
PENTRU i:=1; n EXECUTĂ oi :=i SFPENTRU
REPETĂ ind:=0;
PENTRU i:=1;n- 1 EXECUTĂ
DACĂ x[oi] < x[oi+1] ATUNCI
FIE ind:=1; t:=oi+1 ;
oi+1 :=oi; oi :=t;
SFDACĂ
SFPENTRU
PANÂCÂND ind=0 SFREP
SF-ORDINE
A doua subproblemă se poate specifica astfel:
20](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-18-2048.jpg)














![Dacă a≤k1 atunci p:=1 altfel
Dacă a>kn atunci p:=n+1 altfel
Pentru i:=2; n execută
Dacă (p=0) şi (a≤ki) atunci p:=i sfdacă
sfpentru
sfdacă
sfdacă
sf-CautSecv
Se observă că prin această metodă se vor executa în cel mai nefavorabil caz n-1 comparări,
întrucât contorul i va lua toate valorile de la 2 la n. Cele n chei împart axa reală în n+1 intervale. Tot
atâtea comparări se vor efectua în n-1 din cele n+1 intervale în care se poate afla cheia căutată, deci
complexitatea medie are acelaşi ordin de mărime ca şi complexitatea în cel mai rău caz.
Evident că în multe situaţii acest algoritm face calcule inutile. Atunci când a fost deja găsită cheia
dorită este inutil a parcurge ciclul pentru celelalte valori ale lui i. Cu alte cuvinte este posibil să înlocuim
ciclul PENTRU cu un ciclu CÂTTIMP. Ajungem la un al doilea algoritm, dat în continuare.
SUBPROGRAMul CautSucc(a,n,K,p) este: {n∈N, n≥1 şi}
{k1 < k2 < .... < kn}
{Se caută p astfel ca:}
{(p=1 şi a ≤ k1) sau (p=n+1 şi a>kn)}
{sau (1<p≤n) şi (kp-1 < a ≤ kp).
Fie p:=1;
Dacă a>k1 atunci
Câttimp p≤n şi a>kp executş p:=p+1 sfcât
sfdacă
sf-CautSecv
O altă metodă, numită căutare binară, care este mult mai eficientă, utilizează tehnica "divide et
impera" privitor la date. Se determină în ce relaţie se află cheia articolului aflat în mijlocul colecţiei cu
cheia de căutare. În urma acestei verificări căutarea se continuă doar într-o jumătate a colecţiei. În acest
mod, prin înjumătăţiri succesive se micşorează volumul colecţiei rămase pentru căutare. Căutarea binară
se poate realiza practic prin apelul funcţiei BinarySearch(a,n,K,1,n), descrisă mai jos, folosită în
SUBPROGRAMul dat în continuare.
SUBPROGRAMul CautBin(a,n,K,p) este: {n∈N, n≥1 şi k1 < k2 < .... < kn}
{Se caută p astfel ca: (p=1 şi a ≤ k1) sau}
{(p=n+1 şi a>kn) sau (1<p≤n) şi (kp-1 < a ≤ kp)}
Dacă a≤k1 atunci p:=1 altfel
Dacă a>kn atunci p:=n+1 altfel
p:=BinarySearch(a,n,K,1,n)
sfdacă
sfdacă
sf-CautBin
Funcţia BinarySearch (a,n,K,St,Dr) este:
Dacă St≥Dr-1
atunci BinarySearch:=Dr
altfel m:=(St+Dr) Div 2;
Dacă a≤K[m]
atunci BinarySearch:=BinarySearch(a,n,K,St,m)
altfel BinarySearch:=BinarySearch(a,n,K,m,Dr)
sfdacă
35](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-33-2048.jpg)
![sfdacă
sf-BinarySearch
În funcţia BinarySearch descrisă mai sus, variabilele St şi Dr reprezintă capetele intervalului de
căutare, iar m reprezintă mijlocul acestui interval.
Se observă că funcţia BinarySearch se apelează recursiv. Se poate înlătura uşor recursivitatea, aşa
cum se poate vedea în următoarea funcţie:
Funcţia BinSeaNerec (a,n,K,St,Dr) este:
Câttimp Dr-St>1 execută
m:=(St+Dr) Div 2;
Dacă a≤K[m]
atunci Dr:=m
altfel St:=m
sfdacă
sfcât
BinSeaNerec:=Dr
sf-BinSeaNerec
5.2 Sortare internă
Prin sortare internă vom înţelege o rearanjare a unei colecţii aflate în memoria internă astfel
încât cheile articolelor să fie ordonate crescător (eventual descrescător).
Din punct de vedere al complexităţii algoritmilor problema revine la ordonarea cheilor. Deci
specificarea problemei de sortare internă este următoarea:
Date n,K; {K=(k1,k2,...,kn)}
Precondiţia: ki∈R, i=1,n
Rezultate K';
Postcondiţia: K' este o permutare a lui K, dar ordonată crescător.
Deci k1 ≤ k2 ≤ ... ≤ kn.
O primă tehnică numită "Selecţie" se bazează pe următoarea idee: se determină poziţia
elementului cu cheie de valoare minimă (respectiv maximă), după care acesta se va interschimba cu
primul element. Acest procedeu se repetă pentru subcolecţia rămasă, până când mai rămâne doar
elementul maxim.
SUBPROGRAMul Selectie(n,K) este: {Se face o permutare a celor}
{n componente ale vectorului K astfel}
{ca k1 ≤ k2 ≤ .... ≤ kn }
Pentru i:=1; n-1 execută
Fie ind:=i;
Pentru j:=i+1; n execută
Dacă kj < kind atunci ind:=j sfdacă
sfpentru
Dacă i<ind atunci t:=ki; ki:=kind; kind:=t sfdacă
sfpentru
sf-Selectie
Se observă că numărul de comparări este:
(n-1)+(n-2)+...+2+1=n(n-1)/2
indiferent de natura datelor.
A treia metodă care va fi prezentată, numită "BubbleSort", compară două câte două elemente
consecutive iar în cazul în care acestea nu se află în relaţia dorită, ele vor fi interschimbate. Procesul de
comparare se va încheia în momentul în care toate perechile de elemente consecutive sunt în relaţia de
ordine dorită.
36](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-34-2048.jpg)


![Algoritmul MergeSort de sortare bazat pe interclasare se poate vedea în continuare.
Algoritmul MergeSort este: {Sortare prin interclasare}
Citeşte n;
Pentru i:=1 ; n execută Citeşte Ki sfpentru
Cheamă SortInter (n,K);
Pentru i:=1; n execută Tipăreşte Ki sfpentru
sf-MergeSort
SUBPROGRAMul SortInter(n, C) este:
Cheamă Ordon (1,n,C);
sf-SortInter
SUBPROGRAMul Ordon (St,Dr,A) este: {Sortare prin interclasare a}
{elementelor ASt,ASt+1,...,ADr}
Dacă St < Dr atunci
Fie m:=(St+Dr) Div 2;
Cheamă Ordon (St,m,A);
Cheamă Ordon (m+1,Dr,A);
Cheamă Inter (St,m, m+1,Dr);
sfdacă
sf-Ordon
SUBPROGRAMul Inter (s1,d1, s2,d2) este: { Interclasare }
Fie A:=C; k:=s1-1;
Câttimp (s1<=d1) şi (s2<=d2) execută
Dacă (C[s1]<C[s2])
atunci Cheamă PUNE(s1,cs1 ,k,A)
altfel Cheamă PUNE(s2,cs2 ,k,A)
sfdacă
sfcât
Câttimp (s1<=d1) execută Cheamă PUNE(s1,cs1 ,k,A) sfcât
Câttimp (s2<=d2) execută Cheamă PUNE(s2,cs2 ,k,A) sfcât
C:=A
sf-Inter
5.4 Sortare externă
O problemă cu care ne confruntăm adesea este sortarea unei colecţii de date aflate pe un suport
extern, de volum relativ mare faţă de memoria internă disponibilă. În această secţiune o astfel de colecţie
de date o vom numi fişier. În acest caz nu este posibil transferul întregii colecţii în memoria internă
pentru a fi ordonată şi apoi din nou transferul pe suport extern. Dacă datele ce urmează a fi sortate ocupă
un volum de n ori mai mare decât spaţiul de memorie internă de care dispunem, atunci colecţia se va
împărţi în n subcolecţii ce vor fi transferate succesiv în memoria internă, se vor sorta pe rând şi vor fi
stocate din nou pe suportul extern sortate. Din acest moment prin operaţii de interclasare două câte două
se pot obţine colecţii de dimensiuni superioare până se obţine toată colecţia ordonată.
La aceste interclasări, pentru a efectua un număr cât mai mic de operaţii de transfer se recomandă
interclasarea colecţiilor de dimensiuni minime, apoi din datele obţinute din nou vor fi alese două colecţii
de dimensiuni minime şi aşa mai departe până se obţine o singură colecţie care va fi colecţia cerută, adică
sortată.
După metodele de sortare externă folosite, se descriu trei procedee de sortare externă:
39](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-37-2048.jpg)


















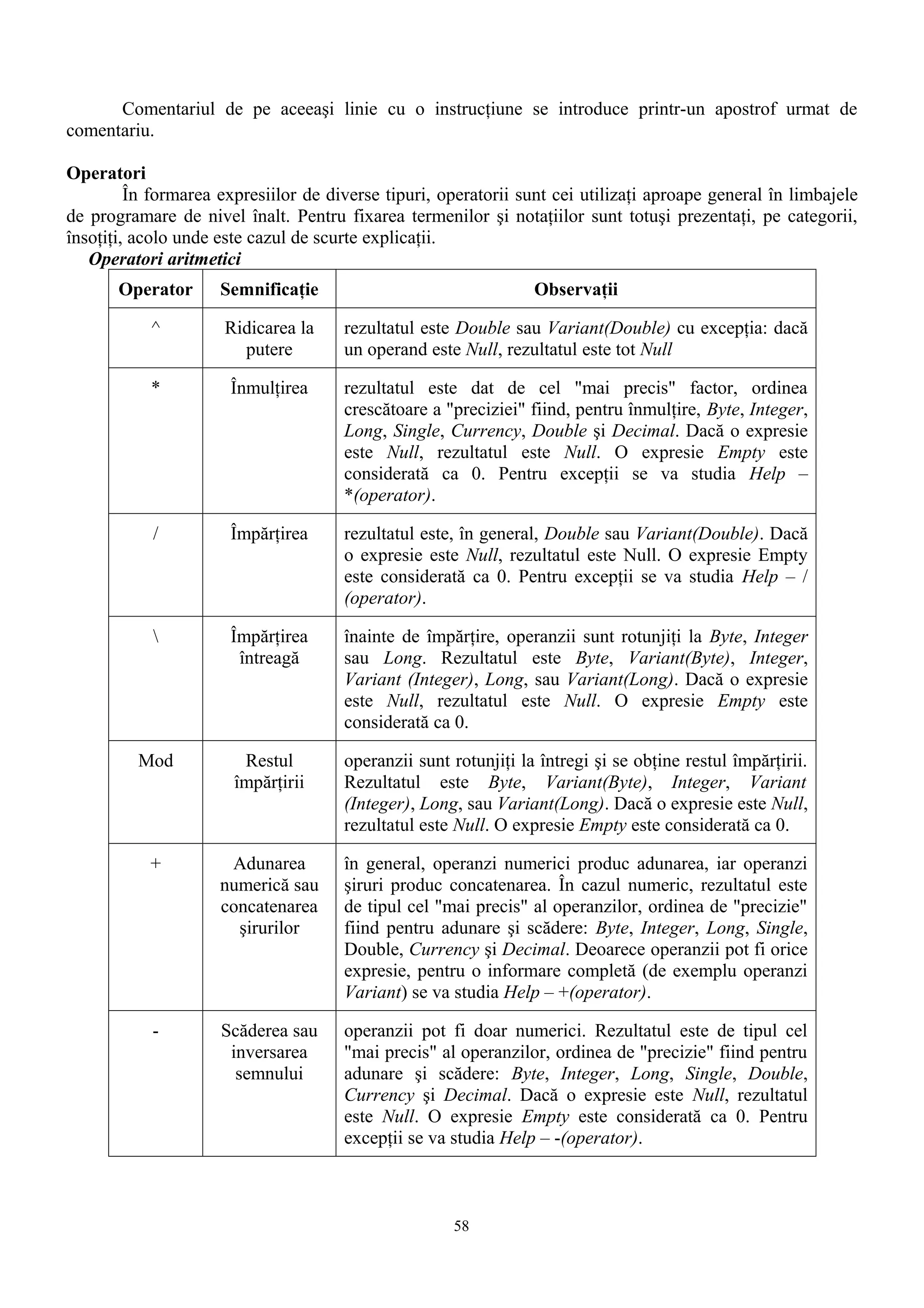
![Operatori de comparare
Relaţiile care există între diferite tipuri de entităţi se pot evidenţia prin comparaţii având una
dintre formele următoare:
result = expression1 comparisonoperator expression2
result = object1 Is object2
result = string Like pattern
unde
result este o variabilă numerică
expression este o expresie oarecare
comparisonoperator este un operator relaţional
object este un nume de obiect
string este o expresie şir oarecare
pattern este o expresie String sau un domeniu de caractere.
Operatorii de comparare sunt cei uzuali: < (mai mic), <= (mai mic sau egal), > (mai mare), >=
(mai mare sau egal), = (egal), <> (diferit, neegal).
Rezultatul este True (dacă este adevărată relaţia), False (dacă relaţia este neadevărată), Null (dacă
cel puţin un operand este Null).
Operatorul Is produce True dacă variabilele se referă la acelaşi obiect şi False în caz contrar.
Operatorul Like compară două şiruri cu observaţia că al doilea tremen este un şablon. Prin urmare
rezultatul este True dacă primul şir operand este format după şablon, False în caz contrar. Atunci când un
operand este Null, rezultatul este tot Null.
Comportarea operatorului Like depinde de instrucţiunea Option Compare, care poate fi:
Option Compare Binary, ordinea este cea a reprezentării interne binare, determinată în
Windows de codul de pagină.
Option Compare Text, compararea este insenzitivă la capitalizarea textului, ordinea este
determinată de setările locale ale sistemului.
Construcţia şablonului poate cuprinde caractere wildcard, liste de caractere, domenii de caractere:
• un caracter oarecare
• oricâte caractere (chiar nici unul)
• # o cifră oarecare (0–9).
• [charlist] oricare dintre caracterele enumerate în listă, un domeniu de litere poate fi dat
prin utilizarea cratimei.
• [!charlist] orice caracter care nu este în listă
Observaţie. Pentru a utiliza în şablon caracterele speciale cu valoare de wildcard se vor utiliza construcţii
de tip listă: [[], [?] etc. Paranteza dreapta va fi indicată singură: ].
Pentru alte observaţii utile se va studia Help – Like operator.
Operatori de concatenare
Pentru combinarea şirurilor de caractere se pot utiliza operatorii & şi +.
În sintaxa
expression1 & expression2
unde operanzii sunt expresii oarecare, rezultatul este:
de tip String, dacă ambii operanzi sunt String
de tip Variant(String) în celelalte cazuri
Null, dacă ambii operanzi sunt Null.
Înainte de concatenare, operanzii care nu sunt şiruri se convertesc la Variant(String). Expresiile
Null sau Empty sunt tratate ca şiruri de lungime zero ("").
59](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-57-2048.jpg)
![Operatori logici
Pentru operaţiile logice sunt utilizaţi următorii operatori, uzuali în programare.
Operator Semnificaţie Observaţii
And conjuncţia logică Null cu False dă False, Null cu True sau cu Null dă Null.
Operatorul And realizează şi operaţia de conjuncţie bit cu
bit pentru expresii numerice.
Eqv echivalenţa logică Dacă o expresie este Null, rezultatul este Null. Eqv
realizează şi compararea bit cu bit a două expresii
numerice, poziţionând cifrele binare ale rezultatului după
regulile de calcul ale echivalenţei logice: 0 Eqv 0 este 1
etc.
Imp implicaţia logică True Imp Null este Null, False Imp * este True, Null Imp
True este True, Null Imp False (sau Null) este Null.
Operatorul Imp realizează şi compararea bit cu bit a două
expresii numerice, poziţionând cifrele binare ale
rezultatului după regulile de calcul ale implicaţiei logice: 1
Imp 0 este 0, în rest rezultatul este 1.
Not negaţia logică Not Null este Null. Prin operatorul Not se poate inversa bit
cu bit valorile unei variabile, poziţionându-se
corespunzător un rezultat numeric.
Or disjuncţia logică Null Or True este True, Null cu False (sau Null) este Null.
Operatorul Or realizează şi o comparaţie bit cu bit a două
expresii numerice poziţionând biţii corespunzători ai
rezultatului după regulile lui Or logic.
Xor disjuncţia Dacă un operand este Null, atunci rezultatul este Null. Se
exclusivă poate efectua operaţia de sau exclusiv şi bit cu bit pentru
două expresii numerice [b1+b2(mod 2)].
Instrucţiuni de atribuire
Atribuirea se poate efectua prin instrucţiunea Let (pentru valori atribuite variabilelor şi
proprietăţilor), Set (pentru atribuirea de obiecte la o variabilă de tip obiect), Lset şi Rset (pentru atribuiri
speciale de şiruri sau tipuri definite de utilizator).
Instrucţiunea Let
Atribuie valoarea unei expresii la o variabilă sau proprietate.
[Let] varname = expression
unde varname este nume de variabilă sau de proprietate.
Este de remarcat forma posibilă (şi de fapt general utilizată) fără cuvântul Let.
Observaţii. Valoarea expresiei trebuie să fie compatibilă ca tip cu variabila (sau proprietatea): valori
numerice nu pot fi atribuite variabilelor de tip String şi nici reciproc.
Variabilele Variant pot primi valori numerice sau String, reciproc nu este valabil decât dacă
valoarea expresiei Variant poate fi interpretată compatibilă cu tipul variabilei: orice Variant poate fi
atribuit unei variabile de tip String (cu excepţia Null), doar Variant care poate fi interpretat nuric poate fi
atribuit unei variabile de tip numeric.
La atribuirea valorilor numerice pot avea loc conversii la tipul numeric al variabilei.
Atribuirea valorilor de tip utilizator poate fi efectuată doar dacă ambii termeni au acelaşi tip
definit. Pentru alte situaţii se va utiliza instrucţiunea Lset.
Nu se poate utiliza Let (cu sau fără cuvântul Let) pentru legarea de obiecte la variabile obiect. Se
va utiliza în această situaţie instrucţiunea Set.
60](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-58-2048.jpg)


![Exit
Prin instrucţiunea Exit, sub una din multiplele ei forme, se întrerupe o ramură de execuţie (cum ar
fi o procedură, o structură iterativă etc.) pentru a se continua nivelul apelant. Sintaxa este
Exit Do
Exit For
Exit Function
Exit Property
Exit Sub
şi efectele sunt prezentate la structurile respective. Nu trebuie confundată cu instrucţiunea End.
Stop
Efectul instrucţiunii este dependent de modul de execuţiei a programului. Dacă se execută varianta
compilată a programului (fişierul .exe) atunci instrucţiunea este similară instrucţiunii End (suspendă
execuţia şi închide fişierele deschise). Dacă execuţia este din mediul VBA, atunci se suspendă execuţia
programului, dar nu se închid fişierele deschise şi nu se şterge valoarea variabilelor. Execuţia poate fi
reluată din punctul de suspendare.
Stop
Instrucţiunea este similară introducerii unui punct de oprire (Breakpoint) în codul sursă.
Structuri iterative (Do...Loop, For...Next, For Each...Next, While...Wend, With)
Prin intermediul construcţiilor de tip bloc prezentate în această secţiune se poate repeta, în mod
controlat, un grup de instrucţiuni. În cazul unui număr nedefinit de repetiţii, condiţia de oprire poate fi
testată la începutul sau la sfârşitul unui ciclu, prin alegerea structurii adecvate.
Do…Loop
Se vor utiliza structuri Do…Loop pentru a executa un grup de instrucţiuni de un număr de ori
nedefinit aprioric. Dacă se cunoaşte numărul de cicluri, se va utiliza structura For…Next.
Înainte de continuare se va testa o condiţie (despre care se presupune că poate fi modificată în
instrucţiunile executate). Diferitele variante posibile pentru Do…Loop diferă după momentul evaluării
condiţiei şi decizia luată.
Do [{While | Until} condition]
[statements]
[Exit Do]
[statements]
Loop
sau
Do
[statements]
[Exit Do]
[statements]
Loop [{While | Until} condition]
unde
condition este o expresie care valoare de adevăr True sau False. O condiţie care este Null
se consideră False.
statements sunt instrucţiounile care se repetă atâta timp (while) sau până când (until)
condiţia devine True.
Dacă decizia este de a nu continua ciclarea, atunci se va executa prima instrucţiune care urmează
întregii structuri (deci de după linia care începe cu Loop).
Se poate abandona ciclarea oriunde în corpul structurii prin utilizarea comenzii Exit Do (cu
această sintaxă). Dacă apare o comandă Exit Do se poate omite chiar şi condiţia din enunţ întrucât
execuţia se va termina prin această decizie.
63](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-61-2048.jpg)
![Structurile Do pot fi inserate (dar complet) unele în altele. O terminare (prin orice metodă) a unei
bucle transferă controlul la nivelul Do imediat superior.
Execuţia structurilor este explicată în tabelul următor
Do While…Loop Testează condiţia la începutul buclei, execută bucla
numai dacă rezultatul este True şi continuă astfel
până când o nouă evaluare produce False.
Do Until…Loop Testează condiţia la începutul buclei, execută bucla
numai dacă rezultatul este False şi continuă astfel
până când o nouă evaluare produce True.
Do…Loop While Se execută întotdeauna bucla o dată, se testează
condiţia la sfârşitul buclei şi se repetă bucla atât
timp cât condiţia este True. Oprirea este pe
condiţie falsă.
Do…Loop Until Se execută întotdeauna bucla o dată, se testează
condiţia la sfârşitul buclei şi se repetă bucla atât
timp cât condiţia este False. Oprirea este pe
condiţie adevărată.
For…Next
Atunci când se cunoaşte numărul de repetări ale unui bloc de instrucţiuni, se va folosi structura
For…Next. Structura utilizează o variabilă contor, a cărei valoare se modifică la fiecare ciclu, oprirea
fiind atunci când se atinge o valoare specificată. Sintaxa este:
For counter = start To end [Step step]
[statements]
[Exit For]
[statements]
Next [counter]
unde
counter este variabila contor (numără repetările), de tip numeric. Nu poate fi de tip
Boolean sau element de tablou.
start este valoarea iniţială a contorului.
end este valoarea finală a contorului.
step este cantitatea care se adună la contor la fiecare pas. În cazul în care nu se specifică
este implicit 1. Poate fi şi negativă.
statements sunt instrucţiunile care se repetă. Dacă nu se specifică, atunci singura acţiune
este cea de modificare a contorului de un număr specificat de ori.
Acţiunea este dictată de pasul de incrementare şi relaţia dintre valoarea iniţială şi cea finală.
Instrucţiunile din corpul structurii se execută dacă
counter <= end pentru step >= 0 sau
counter >= end pentru step < 0.
După ce toate instrucţiunile s-au executat, valoarea step este adăugată la valoarea contorului şi
instrucţiunile se execută din nou după acelaşi test ca şi prima dată, sau bucla For…Next este terminată şi
se execută prima instrucţiune de după linia Next.
Specificarea numelui contorului în linia Next poate clarifica textul sursă, mai ales în cazul când
există structuri For…Next îmbricate.
Corpul unei bucle For…Next poate include (complet) o altă structură For…Next. În asemenea
situaţii, structurile îmbricate trebuie să aibă variabile contor diferite.
64](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-62-2048.jpg)
![Instrucţiunile Exit For pot fi plasate oriunde în corpul unei bucle şi provoacă abandonarea ciclării.
Controlul execuţiei se transferă la prima instrucţiune de după linia Next.
For Each…Next
Similară structurii For…Next, structura For Each…Next repetă un grup de instrucţiuni pentru
fiecare element dintr-o colecţie de obiecte sau dintr-un tablou (cu excepţia celor de un tip utilizator). Este
utilă atunci când nu se cunoaşte numărul de elemente sau dacă se modifică, în timpul execuţiei, conţinutul
colecţiei.
Sintaxa este:
For Each element In group
[statements]
[Exit For]
[statements]
Next [element]
unde
element este variabila utilizată pentru parcurgerea elementelor. Dacă se parcurge o colecţie
de obiecte, atunci element poate fi Variant, o variabilă generică de tip Object, sau o
variabilă obiect specifică pentru biblioteca de obiecte referită. Pentru parcurgerea unui
tablou, element poate fi doar o variabilă de tip Variant.
group este numele colecţiei de obiecte sau al tabloului.
statements este grupul de istrucţiuni executate pentru fiecare element.
Execuţia unei structuri For Each…Next este:
Se defineşte element ca numind primul element din grup (dacă nu există nici un element, se
transferă controlul la prima instrucţiune de după Next – se părăseşte bucla fără executarea
instrucţiunilor).
Se execută instrucţiunile din corpul buclei For.
Se testează dacă element este ultimul element din grup. Dacă răspunsul este afirmatif, se
părăseşte bucla.
Se defineşte element ca numind următorul element din grup.
Se repetă paşii 2 până la 4.
Instrucţiunile Exit For sunt explicate la For…Next.
Buclele ForEach...Next pot fi îmbricate cu condiţia ca elementele utilizate la iterare să fie diferite.
Observaţie. Pentru ştergerea tuturor obiectelor dintr-o colecţie se va utiliza For…Next şi nu For Each…
Next. Se va utiliza ca număr de obiecte colecţie.Count.
While…Wend
Execută un grup de instrucţiuni atât timp cât este adevărată o condiţie. Sintaxa
While condition
[statements]
Wend
Este recomandat să se utilizeze o structură Do…Loop în locul acestei structuri.
With
Programarea orientată pe obiecte produce, datorită calificărilor succesive, construcţii foarte
complexe atunci când se numesc proprietăţile unui obiect. În cazul modificărilor succesive ale mai multor
proprietăţi ale aceluiaşi obiect, repetarea zonei de calificare poate produce erori de scriere şi conduce la
un text greu de citit. Codul este simplificat prin utilizarea structurii With…End With. O asemenea
structură execută o serie de instrucţiuni pentru un obiect sau pentru o variabilă de tip utilizator. Sintaxa
este:
With object
[statements]
65](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-63-2048.jpg)
![End With
unde
object este numele unui obiect sau a unui tip definit de utilizator
statements sunt instrucţiunile care se execută pentru entitatea precizată.
Permiţând omiterea recalificărilor din referinţele la obiectul precizat, orice construcţie de tipul
".nume" este interpretată în instrucţiunile structurii drept "object.nume".
Într-un bloc With nu se poate schimba obiectul procesat.
La plasarea unui bloc With în interiorul altui bloc With, obiectul extern este mascat complet, deci
calificările eventuale la acest obiect vor fi efectuate.
Nu se recomandă saltul în şi dintr-un bloc With.
Structuri de decizie (If…Then…Else, Select Case)
Ramificarea firului execuţiei după rezultatul verificării unei condiţii este o necesitate frecventă în
orice implementare.
Pe lângă structurile prezentate, se pot utiliza trei funcţii care realizează alegeri în mod liniarizat
(pe o linie de cod): Choose(), Iif(), Switch().
If…Then…Else
O asemenea structură, întâlnită de altfel în toate limbajele de programare, execută un grup de
instrucţiuni ca răspuns la îndeplinirea unei condiţii (compusă sau nu din mai multe condiţii testate
secvenţial). Sintaxa permite o mare varietate de forme:
If condition Then [statements] [Else elsestatements]
sau
If condition Then
[statements]
[ElseIf condition-n Then
[elseifstatements] ...
[Else
[elsestatements]]
End If
unde
condition are una din formele: expresie numerică sau şir care se poate evalua True sau
False (Null este interpretat False);
expresie de forma TypeOf objectname Is objecttype, evaluată True dacă objectname este
de tipul obiect specificat în objecttype.
statements, elsestatements, elseifstatements sunt blocurile de instrucţiuni executate atunci
când condiţiile corespunzătoare sunt True.
La utilizarea primei forme, fără clauza Else, este posibil să se scrie mai multe instrucţiuni,
separate de ":", pe aceeaşi linie.
Verificarea condiţiilor implică evaluarea tuturor subexpresiilor, chiar dacă prin jocul operanzilor
şi operatorilor rezultatul poate fi precizat mai înainte (de exemplu OR cu primul operand True).
Select Case
Instrucţiunea Select Case se poate utiliza în locul unor instrucţiuni ElseIf multiple (dintr-o
structură If…Then…ElseIf) atunci când se compară aceeaşi expresie cu mai multe valori, diferite între
ele. Instrucţiunea Select Case furnizează, prin urmare, un sistem de luare a deciziilor similar instrucţiunii
If…Then…ElseIf. Totuşi, Select Case produce un un cod mai eficient şi mai inteligibil. Sintaxa este:
Select Case testexpression
[Case expressionlist-n
[statements-n]] ...
[Case Else
[elsestatements]]
66](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-64-2048.jpg)
![End Select
unde
testexpression este o expresie numerică sau şir.
expressionlist-n este lista, separată prin virgule, a uneia sau mai multe expresii de forma:
expression.
expression To expression. Cuvântul To introduce un interval de valori, valoarea minimă
fiind prima specificată.
Is comparisonoperator expression. Se va utiliza Is cu operatori de comparare (exceptând
Is şi Like) pentru a specifica un domeniu de valori.
statements-n reprezintă una sau mai multe instrucţiuni care se vor executa dacă
testexpression este egală cu un element din expressionlist-n.
elsestatements reprezintă una sau mai multe instrucţiuni care se vor executa dacă
testexpression nu este egală cu nici un element din listele liniilor Case.
Dacă testexpression se potriveşte cu un element dintr-o listă Case, se vor executa instrucţiunile
care urmează această clauză Case până la următoarea clauză Case, sau până la End Select. Control
execuţiei trece apoi la instrucţiunea care urmează liniei finale End Select. Rezultă că dacă testexpression
se regăseşte în mai multe liste, doar prima potrivire este considerată.
Clauza Case Else are semnificaţia uzuală "altfel, în rest, în caz contrar etc.", adică introduce
instrucţiunile care se execută atunci când expresia de test nu se potriveşte nici unui element din listele
clauzelor Else. Dacă aceasta este situaţia şi nu este specificată o clauză Case Else, atunci execuţia
urmează cu prima instrucţiune de după End Select.
Instrucţiunile Select Case pot fi scufundate unele în altele, structurile interioare fiind complete
(fiecare structură are End Select propriu, includerea este completă).
Apeluri de proceduri şi programe
În această secţiune se prezintă doar funcţia Shell(), deoarece despre proceduri şi apelul lor s-a
discutat în capitolul 1.
Funcţia Shell()
Execută un program executabil şi returnează un Variant(Double) reprezentând ID-ul de task al
programului în caz de succes; în caz contrar returnează zero. Sintaxa este
Shell(pathname[,windowstyle])
unde
pathname este Variant (String). Conţine numele programului care se execută, argumentele
necesare şi poate da calea completă (dacă este nevoie).
windowstyle este Variant (Integer) şi precizează stilul ferestrei în care se va executa
programul (implicit este minimizat, cu focus).
Valorile posibile pentru argumentul windowstyle sunt
Constanta numită Valoarea Semnificaţia
VbHide 0 Fereastra este ascunsă iar focus-ul este pe fereastra ascunsă.
VbNormalFocus 1 Fereastra are focus-ul şi este dimensionată şi poziţionată normal.
VbMinimizedFocus 2 Fereastra este afişată ca o icoană (minimizată) dar are focus-ul.
VbMaximizedFocus 3 Fereastră maximizată, cu focus.
VbNormalNoFocus 4 Fereastra este normală (restaurată la mărimea şi poziţia cea mai recentă)
dar nu are focus-ul. Fereastra activă curentă îşi păstrează focus-ul.
VbMinimizedNoFocu 6 Fereastră minimizată, fără focus. Fereastra activă curentă îşi păstrează
s focus-ul.
67](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-65-2048.jpg)

![CAPITOLUL VIII
REGULI IMPORTANTE PRIVIND ALEGEREA UNUI LIMBAJ DE PROGRAMARE
Prezentăm în continuare mai multe reguli importante, majoritatea dintre ele prezente şi explicate
în secţiunile anterioare.
1. Defineşte complet problema.
Această indicaţie, foarte importantă în activitatea de programare, pare fără sens pentru unii cititori.
Dar nu se poate rezolva o problemă dacă nu se cunoaşte această problemă. Specificarea corectă şi
completă a problemei nu este o sarcină trivială, ci una foarte importantă şi adeseori chiar dificilă.
Programul trebuie să respecte această specificaţie, să fie construit având tot timpul în faţă această
specificaţie, să i se demonstreze corectitudinea în raport cu această specificaţie, să fie testat şi validat
ţinând seama de această specificaţie.
2. Gândeşte mai întâi, programează pe urmă.
Începând cu scrierea specificaţiilor problemei, trebuie pusă în prim plan gândirea. Este specificaţia
problemei corectă? Între metodele de rezolvare posibile, care ar fi cea mai potrivită scopului urmărit? În
paralel cu proiectarea algoritmului demonstrează corectitudinea lui. Verifică corectitudinea fiecărui pas
înainte de a merge mai departe.
3. Nu folosi variabile neiniţializate.
Este vorba de prezenţa unei variabile într-o expresie fără ca în prealabil această variabilă să fi
primit valoare. Este o eroare foarte frecventă a programatorilor începători (dar nu numai a lor). Destule
compilatoare permit folosirea variabilelor neiniţializate, neverificând dacă o variabilă a fost iniţializată
înaintea folosirii ei. Alte compilatoare iniţializează automat variabilele numerice cu valoarea zero. Cu
toate acestea nu e bine să ne bazăm pe o asemenea iniţializare ci să atribuim singuri valorile iniţiale
corespunzătoare variabilelor. Programul realizat trebuie să fie portabil, să nu se bazeze pe specificul unui
anumit compilator.
4. Verifică valoarea variabilei imediat după obţinerea acesteia.
Dacă o variabilă întreagă trebuie să ia valori într-un subdomeniu c 1..c2 verifică respectarea acestei
proprietăţi. Orice încălcare a ei indică o eroare care trebuie înlăturată. Valoarea variabilei poate fi
calculată sau introdusă de utilizator. În primul caz, verificarea trebuie făcută după calcul, în al doilea caz
se recomandă ca verificarea să urmeze imediat după citirea valorii respectivei variabile.
5. Cunoaşte şi foloseşte metodele de programare.
Este vorba de programarea Top-Down, Rafinarea în paşi succesivi, Divide et impera [Gries85]),
Bottom-up şi mixtă, programarea modulară, programarea structurată şi celelalte metode prezentate în
acest curs, sau alte metode ce vor fi asimilate ulterior.
Aceste metode încurajează reutilizarea, reducând costul realizării programelor. De asemenea,
folosirea unor componente existente (deci testate) măreşte gradul de fiabilitate a produselor soft realizate
şi scurtează perioada de realizare a acestora. Evident, dacă o parte din SUBPROGRAMii necesari
programului sunt deja scrişi şi verificaţi, viteza de lucru va creşte prin folosirea lor. Foloseşte deci
bibliotecile de componente reutilizabile existente şi construieşte singur astfel de biblioteci, care să
înglobeze experienţa proprie.
69](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-67-2048.jpg)



![CAPITOLUL IX
METODA BACKTRACKING
La dispoziţia celor care rezolvă probleme cu ajutorul calculatorului există mai multe metode.
Dintre acestea cel mai des utilizate sunt:
– metoda Greedy;
– metoda Divide et impera;
– metoda Branch and Bound;
– metoda Backtracking;
Metoda backtracking se aplică problemelor în care soluţia poate fi reprezentată sub forma unui
vector – x = (x1, x2, x3, …xk,… xn) € S, unde S este mulţimea soluţiilor problemei şi S = S1 x S2 x… x
Sn, şi Si sunt mulţimi finite având s elemente si xi € si , (¥)i = 1..n.
Pentru fiecare problemă se dau relaţii între componentele vectorului x, care sunt numite condiţii
interne; soluţiile posibile care satisfac condiţiile interne se numesc soluţii rezultat. Metoda de generare a
tuturor soluţiilor posibile si apoi de determinare a soluţiilor rezultat prin verificarea îndeplinirii condiţiilor
interne necesită foarte mult timp.
Metoda backtracking evită această generare şi este mai eficientă. Elementele vectorului x,
primesc pe rând valori în ordinea crescătoare a indicilor, x[k] va primi o valoare numai daca au fost
atribuite valori elementelor x1.. x[k-1]. La atribuirea valorii lui x[k] se verifica îndeplinirea unor condiţii
de continuare referitoare la x1…x[k-1]. Daca aceste condiţii nu sunt îndeplinite, la pasul k, acest lucru
înseamnă ca orice valori i-am atribui lui x[k+1], x[k+1], .. x[n] nu se va ajunge la o soluţie rezultat.
Metoda backtracking construieşte un vector soluţie în mod progresiv începând cu prima
componentă a vectorului şi mergând spre ultima cu eventuale reveniri asupra atribuirilor anterioare.
Metoda se aplica astfel :
1) se alege prima valoare sin S1 si I se atribuie lui x1 ;
2) se presupun generate elementele x1…x[k-1], cu valori din S1..S[k-1]; pentru generarea lui x[k] se
alege primul element din S[k] disponibil si pentru valoarea aleasa se testează îndeplinirea
condiţiilor de continuare.
Pot apărea următoarele situaţii :
a) x[k] îndeplineşte condiţiile de continuare. Daca s-a ajuns la soluţia finală (k = n) atunci se
afişează soluţia obţinută. Daca nu s-a ajuns la soluţia finală se trece la generarea
elementului următor – x [k-1];
b) x[k] nu îndeplineşte condiţiile de continuare. Se încearcă următoarea valoare disponibila
din S[k]. Daca nu se găseşte nici o valoare în S[k] care să îndeplinească condiţiile de
continuare, se revine la elementul x[k-1] şi se reia algoritmul pentru o nouă valoare a
acestuia. Algoritmul se încheie când au fost luate in considerare toate elementele lui S1.
Problemele rezolvate prin această metodă necesită timp mare de execuţie, de aceea este indicat sa
se folosească metoda numai daca nu avem alt algoritm de rezolvare.
Dacă mulţimile S1,S2,…Sn au acelaşi număr k de elemente, timpul necesar de execuţie al
algoritmului este k la n. Dacă mulţimile S1, S2.. Sn nu au acelaşi număr de elemente, atunci se notează cu
„m” minimul cardinalelor mulţimilor S1…Sn si cu „M”, maximul. Timpul de execuţie este situat în
intervalul [m la n .. M la n]. Metoda backtracking are complexitatea exponenţială, in cele mai multe
cazuri fiind ineficientă. Ea insa nu poate fi înlocuită cu alte variante de rezolvare mai rapide în situaţia în
care se cere determinarea tuturor soluţiilor unei probleme.
Generarea permutărilor. Se citeşte un număr natural n. Să se genereze toate permutările
mulţimii {1, 2, 3, …,n}.
Generarea permutărilor se va face ţinând cont că orice permutare va fi alcătuită din elemente
distincte ale mulţimii A. Din acest motiv, la generarea unei permutări, vom urmări ca numerele să fie
distincte.
73](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-71-2048.jpg)
















![PROBLEMA COLORĂRII HĂRŢILOR
Enunţ:
Fiind dată o hartă cu n ţări, se cer toate soluţiile de colorare a hărţii, utilizând cel mult patru culori,
astfel încât două ţări de frontieră comună să fie colorate diferit. Este demonstrat faptul că sunt suficiente
numai patru culori pentru ca orice hartă să poată fi colorată.
Rezolvare:
Pentru exemplificare, vom considera următoarea hartă unde ţările sunt numerotate cu cifre
cuprinse între 1 şi 5:
1
4
3
2
5
Figura 9.1 Harta ţărilor
O soluţie a acestei probleme este următoarea:
ţara 1 – culoarea 1
ţara 2 – culoarea 2
ţara 3 – culoarea 1
ţara 4 – culoarea 3
ţara 5 – culoarea 4
Harta este furnizată programului cu ajutorul unei matrice An,n
1, dacă ţara i se învecinează cu ţara j;
A(i,j) =
0 , altfel
Matricea A este simetrică. Pentru rezolvarea problemei se utilizează stiva st, unde nivelul k al
stivei simbolizează ţara k, iar st[k] culoarea ataşată ţării k. Stiva are înălţimea n şi pe fiecare nivel ia
valori între 1 şi 4.
Sub back_col()
Dim k As Integer
k = 1
init k, st
While k > 0
Do
succesor_col am_suc, st, k
If am_suc = True Then
valid_col ev, st, k
End If
Loop Until (Not am_suc) Or (am_suc And ev)
If am_suc Then
If solutie(k) Then
tipar_col
Else
k = k + 1
init k, st
End If
90](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-88-2048.jpg)

![CAPITOLUL X
METODA DIVIDE ET IMPERA
Metoda de programare DIVIDE ET IMPERA consta in impartirea problemei initiale de
dimensiuni [n] in doua sau mai multe probleme de dimensiuni reduse. In general se executa impartirea in
doua subprobleme de dimensiuni aproximativ egale si anume [n/2]. Impartirea in subprobleme are loc
pana cand dimensiunea acestora devine suficient de mica pentru a fi rezolvate in mod direct(cazul de
baza). Dupa rezolvarea celor doua subprobleme se executa faza de combinare a rezultatelor in vederea
rezolvarii intregii probleme.
Metoda DIVIDE ET IMPERA se poate aplica in rezolvarea unei probleme care indeplineste
urmatoarele conditii:
se poate descompune in (doua sau mai multe) suprobleme;
aceste suprobleme sunt independente una fata de alta (o subproblema nu se rezolva pe
baza alteia si nu se foloseste rezultate celeilalte);
aceste subprobleme sunt similare cu problema initiala;
la randul lor subproblemele se pot descompune (daca este necesar) in alte subprobleme
mai simple;
aceste subprobleme simple se pot solutiona imediat prin algoritmul simplificat.
Deoarece putine probleme indeplinesc conditiile de mai sus ,aplicarea metodei este destul de rara.
Dupa cum sugereaza si numele "desparte si stapaneste "etapele rezolvarii unei probleme (numita
problema initiala) in DIVIDE ET IMPERA sunt :
descompunerea problemei initiale in subprobleme independente, smilare problemei de
baza, de dimensiuni mai mici;
descompunerea treptata a subproblemelor in alte subprobleme din ce in ce mai simple,
pana cand se pot rezolva imediata ,prin algoritmul simplificat;
rezolvarea subproblemelor simple;
combinarea solutiilor gasite pentru construirea solutiilor subproblemelor de dimensiuni
din ce in ce mai mari;
combinarea ultimelor solutii determina obtinerea solutiei problemei initiale
Metoda DIVIDE ET IMPERA admite o implementare recursiva, deorece subproblemele sunt
similare problemei initiale, dar de dimensiuni mai mici.
Principiul fundamental al recursivitatii este autoapelarea unui subprogram cand acesta este activ;
ceea ce se intampla la un nivel, se intampla la orice nivel, avand grija sa asiguram conditia de terminare
ale apelurilor repetate. Asemanator se intampla si in cazul metodei DIVITE ET IMPERA; la un anumit
nivel sunt doua posibilitati:
s-a ajuns la o (sub)problema simpla ce admite o rezolvare imediata caz in care se
rezolva (sub)problema si se revine din apel (la subproblema anterioara, de dimensiuni mai
mari);
s-a ajuns la o (sub)problema care nu admite o rezolvare imediata, caz in care o
descompunem in doua sau mai multe subprobleme si pentru fiecare din ele se continua
apelurile recursive (ale procedurii sau functiei).
In etapa finala a metodei DIVIDE ET IMPERA se produce combinarea subproblemelor
(rezolvate deja) prin secventele de revenire din apelurile recursive.
Etapele metodei DIVIDE ET IMPERA (prezentate anterior) se pot reprezenta prin urmatorul
subprogram general (procedura sau functie )recursiv exprimat in limbaj natural:
Subprogram DIVIMP (PROB);
Daca PROBLEMA PROB este simpla
Atunci se rezolva si se obtine solutia SOL
Altfel pentru i=1,k executa DIVIMP(PROB) si se obtine SOL1;
92](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-90-2048.jpg)

![Sortare rapida (quicksort)
Un tablou V se completeaza cu n elemente numere reale .Sa se ordoneze crescator folosind
metoda de sortare rapida .
Solutia problemei se bazeaza pe urmatoarele etape implementate in programul principal:
se apeleaza procedura “quick” cu limita inferioara li=1 si limita superioara ls=n;
functia”poz” realizeaza mutarea elementului v[i] exact pe pozitia ce o va ocupa acesta
in vectorul final ordonat ; functia”poz” intoarce (in k ) pozitia ocupata de acest element;
in acest fel , vectorul V se imparte in doua parti: li …k-1 si k+1…ls;
pentru fiecare din aceste parti se reapeleaza procedura ”quick”, cu limitele modificate
corespunzator;
in acest fel, primul element din fiecare parte va fi pozitionat exact pe pozitia finala ce o
va ocupa in vectorul final ordonat (functia”poz”);
fiecare din cele doua parti va fi, astfel, inpartita in alte doua parti; procesul continua
pana cand limitele partilor ajung sa se suprapuna ,ceea ce indica ca toate elementele
vectorului au fost mutate exact pe pozitiile ce le vor ocupa in vectorul final ;deci vectorul
este ordonat ;
in acest moment se produc intoarcerile din apelurile recursive si programul isi termina
executia.
Observaţii:
– daca elementul se afla in stanga, atunci se compara cu elementele din dreapta lui si se
sar (j:=j-1) elementele mai mari decat el;
– daca elementul se afla in dreapta, atunci se compara cu elemente din stanga lui si se sar
(i:=i+1) elementele mai mici decat el.
Sortare prin interclasare(mergesort)
Tabloul unidimensional V se completeaza cu n numere reale. Sa se ordoneze crescator folosind
sortare prin interclasare.
Sortarea prin interclasare se bazeaza pe urmatoarea logica:
– vectorul V se imparte, prin injumatatiri succesive,in vectori din ce in ce mai mici;
– cand se ating vectorii de maxim doua elemente, fiecare dintre acestia se ordoneaza
printr-o simpla comparare a elementelor;
– cate doi astfel de mini-vectori ordonati se interclaseaza succesiv pana se ajunge iar la
vectorul V.
Observaţii:
– mecanismul general de tip Divide et Impera se gaseste implementat in procedura “divi”;
– astfel de abordare a problemei sortarii unii vector conduce la economie de timp de
calcul, deoarece operatia de interclasare a doi vectori deja ordonati este foarte rapida, iar
ordonarea independenta celor doua jumatati (mini-vectori) consuma in total aproximativ a
doua parte din timpul care ar fi necesar ordonarii vectorului luat ca intreg .
CONCLUZII LA TEHNICA DIVIDE ET IMPERA
Sortare prin insertie binara
Sa se ordoneze crescator un tablou unidimensional V de n numere reale, folosind sortarea prin
insertie binara.
Pentru fiecare element v[i] se procedeaza in patru pasi:
1. se considera ordonate elementele v[1],v[2],….,v[i-1];
2. se cauta pozitia k pe care urmeaza s-o ocupe v[i] intre elementele v[1],v[2],…,v[i-1]
(procedura “poz” prin cautare binara);
3. se deplaseaza spre dreapta elementele din pozitiile k,k+1,…,n (procedura “deplasare”);
94](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-92-2048.jpg)
![4. insereaza elementul v[i] in pozitia k (procedura”deplasare”);
Se obtine o succesiune de k+1 elemente ordonate crescator.
Analiza a complexitatii timp pentru algoritmii Divide et Impera
Algoritmii de tip Divide et Impera au buna comportare in timp, daca se indeplinesc urmatoarele
conditii:
– dimensiunile subprogramelor (in care se imparte problema initiala) sunt aproximativ
egale (“principiul balansarii”);
– lipsesc fazele de combinare a solutiilor subproblemelor (cautare binara).
95](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-93-2048.jpg)




![q2, iar B' se obtine in acelasi mod din B", rezulta ca L(A) = L(B') = L(B). Proprietatea este deci adevarata
pentru orice n.
La scrierea algoritmului care genereaza arborele strategiei greedy de interclasare vom folosi un
min-heap. Fiecare element al min-heap-ului este o pereche (q, i) unde i este numarul unui varf din
arborele strategiei de interclasare, iar q este lungimea sirului pe care il reprezinta. Proprietatea de min-
heap se refera la valoarea lui q.
Algoritmul interopt va construi arborele strategiei greedy. Un varf i al arborelui va fi memorat in
trei locatii diferite continand:
LU[i] = lungimea sirului reprezentat de varf
ST[i] = numarul fiului stang
DR[i] = numarul fiului drept
procedure interopt(Q[1 .. n])
{construieste arborele strategiei greedy de interclasare
a sirurilor de lungimi Q[i] = qi, 1 ≤ i ≤ n}
H ← min-heap vid
for i ← 1 to n do
(Q[i], i) => H {insereaza in min-heap}
LU[i] ← Q[i]; ST[i] ← 0; DR[i] ← 0
for i ← n+1 to 2n–1 do
(s, j) <= H {extrage radacina lui H}
(r, k) <= H {extrage radacina lui H}
ST[i] ← j; DR[i] ← k; LU[i] ← s+r
(LU[i], i) => H {insereaza in min-heap}
In cazul cel mai nefavorabil, operatiile de inserare in min-heap si de extragere din min-heap
necesita un timp in ordinul lui log n. Restul operatiilor necesita un timp constant. Timpul total pentru
interopt este deci in O(n log n).
Coduri Huffman
O alta aplicatie a strategiei greedy si a arborilor binari cu lungime externa ponderata minima este
obtinerea unei codificari cat mai compacte a unui text.
Un principiu general de codificare a unui sir de caractere este urmatorul: se masoara frecventa de
aparitie a diferitelor caractere dintr-un esantion de text si se atribuie cele mai scurte coduri, celor mai
frecvente caractere, si cele mai lungi coduri, celor mai putin frecvente caractere. Acest principiu sta, de
exemplu, la baza codului Morse. Pentru situatia in care codificarea este binara, exista o metoda eleganta
pentru a obtine codul respectiv. Aceasta metoda, descoperita de Huffman (1952) foloseste o strategie
greedy si se numeste codificarea Huffman. O vom descrie pe baza unui exemplu.
Fie un text compus din urmatoarele litere (in paranteze figureaza frecventele lor de aparitie):
S (10), I (29), P (4), O (9), T (5)
Conform metodei greedy, construim un arbore binar fuzionand cele doua litere cu frecventele cele
mai mici. Valoarea fiecarui varf este data de frecventa pe care o reprezinta.
Etichetam muchia stanga cu 1 si muchia dreapta cu 0. Rearanjam tabelul de frecvente:
S (10), I (29), O (9), {P, T} (45 = 9)
100](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-98-2048.jpg)




![{bucla greedy}
while U ≠ V do
gaseste {u, v} de cost minim astfel ca u ∈ V U si v ∈ U
A ← A ∪ {{u, v}}
U ← U ∪ {u}
return A
Pentru a obtine o implementare simpla, presupunem ca: varfurile din V sunt numerotate de la 1 la
n, V = {1, 2, ..., n}; matricea simetrica C da costul fiecarei muchii, cu C[i, j] = + ∞ , daca muchia {i, j} nu
exista. Folosim doua tablouri paralele. Pentru fiecare i ∈ V U, vecin[i] contine varful din U, care este
conectat de i printr-o muchie de cost minim; mincost[i] da acest cost. Pentru i ∈ U, punem mincost[i] = –
1. Multimea U, in mod arbitrar initializata cu {1}, nu este reprezentata explicit. Elementele vecin[1] si
mincost[1] nu se folosesc.
function Prim(C[1 .. n, 1 .. n])
{initializare; numai varful 1 este in U}
A←ø
for i ← 2 to n do vecin[i] ← 1
mincost[i] ← C[i, 1]
{bucla greedy}
repeat n–1 times
min ← + ∞
for j ← 2 to n do
if 0 < mincost[ j] < min then min ← mincost[ j]
k←j
A ← A ∪ {{k, vecin[k]}}
mincost[k] ← –1 {adauga varful k la U}
for j ← 2 to n do
if C[k, j] < mincost[ j] then mincost[ j] ← C[k, j]
vecin[ j] ← k
return A
Bucla principala se executa de n–1 ori si, la fiecare iteratie, buclele for din interior necesita un
timp in O(n). Algoritmul Prim necesita, deci, un timp in O(n2). Am vazut ca timpul pentru algoritmul lui
Kruskal este in O(m log n), unde m = #M. Pentru un graf dens (adica, cu foarte multe muchii), se deduce
ca m se apropie de n(n–1)/2. In acest caz, algoritmul Kruskal necesita un timp in O(n2 log n) si algoritmul
Prim este probabil mai bun. Pentru un graf rar (adica, cu un numar foarte mic de muchii), m se apropie de
n si algoritmul Kruskal necesita un timp in O(n log n), fiind probabil mai eficient decat algoritmul Prim.
11.5 Cele mai scurte drumuri care pleaca din acelasi punct
Fie G = <V, M> un graf orientat, unde V este multimea varfurilor si M este multimea muchiilor.
Fiecare muchie are o lungime nenegativa. Unul din varfuri este desemnat ca varf sursa. Problema este sa
determinam lungimea celui mai scurt drum de la sursa catre fiecare varf din graf.
Vom folosi un algoritm greedy, datorat lui Dijkstra (1959). Notam cu C multimea varfurilor
disponibile (candidatii) si cu S multimea varfurilor deja selectate. In fiecare moment, S contine acele
varfuri a caror distanta minima de la sursa este deja cunoscuta, in timp ce multimea C contine toate
celelalte varfuri. La inceput, S contine doar varful sursa, iar in final S contine toate varfurile grafului. La
fiecare pas, adaugam in S acel varf din C a carui distanta de la sursa este cea mai mica.
105](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-103-2048.jpg)
![Spunem ca un drum de la sursa catre un alt varf este special, daca toate varfurile intermediare de-a
lungul drumului apartin lui S. Algoritmul lui Dijkstra lucreaza in felul urmator. La fiecare pas al
algoritmului, un tablou D contine lungimea celui mai scurt drum special catre fiecare varf al grafului.
Dupa ce adaugam un nou varf v la S, cel mai scurt drum special catre v va fi, de asemenea, cel mai scurt
dintre toate drumurile catre v. Cand algoritmul se termina, toate varfurile din graf sunt in S, deci toate
drumurile de la sursa catre celelalte varfuri sunt speciale si valorile din D reprezinta solutia problemei.
Presupunem, pentru simplificare, ca varfurile sunt numerotate, V = {1, 2, ..., n}, varful 1 fiind
sursa, si ca matricea L da lungimea fiecarei muchii, cu L[i, j] = + ∞ , daca muchia (i, j) nu exista. Solutia
se va construi in tabloul D[2 .. n]. Algoritmul este:
function Dijkstra(L[1 .. n, 1 .. n])
{initializare}
C ← {2, 3, ..., n} {S = V C exista doar implicit}
for i ← 2 to n do D[i] ← L[1, i]
{bucla greedy}
repeat n–2 times
v ← varful din C care minimizeaza D[v]
C ← C {v} {si, implicit, S ← S ∪ {v}}
for fiecare w ∈ C do
D[w] ← min(D[w], D[v]+L[v, w])
return D
Pentru graful din Figura 11.5, pasii algoritmului sunt prezentati in Tabelul 11.3.
Figura 11.5 Un graf orientat.
Pasul v C D
initializare — {2, 3, 4, 5} [50, 30, 100, 10]
1 5 {2, 3, 4} [50, 30, 20, 10]
2 4 {2, 3} [40, 30, 20, 10]
3 3 {2} [35, 30, 20, 10]
Tabelul 11.3 Algoritmul lui Dijkstra aplicat grafului din Figura 11.5.
Observam ca D nu se schimba daca mai efectuam o iteratie pentru a-l scoate si pe {2} din C. De
aceea, bucla greedy se repeta de doar n-2 ori.
Se poate demonstra urmatoarea proprietate:
Proprietatea 11.5. In algoritmul lui Dijkstra, daca un varf i
i) este in S, atunci D[i] da lungimea celui mai scurt drum de la sursa catre i;
ii) nu este in S, atunci D[i] da lungimea celui mai scurt drum special de la sursa catre i.
106](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-104-2048.jpg)
![La terminarea algoritmului, toate varfurile grafului, cu exceptia unuia, sunt in S. Din proprietatea
precedenta, rezulta ca algoritmul lui Dijkstra functioneaza corect.
Daca dorim sa aflam nu numai lungimea celor mai scurte drumuri, dar si pe unde trec ele, este
suficient sa adaugam un tablou P[2 .. n], unde P[v] contine numarul nodului care il precede pe v in cel
mai scurt drum. Pentru a gasi drumul complet, nu avem decat sa urmarim, in tabloul P, varfurile prin care
trece acest drum, de la destinatie la sursa. Modificarile in algoritm sunt simple:
– initializeaza P[i] cu 1, pentru 2 ≤ i ≤ n
– continutul buclei for cea mai interioara se inlocuieste cu
if D[w] > D[v] + L[v, w] then D[w] ← D[v] + L[v, w]
P[w] ← v
– bucla repeat se executa de n -1 ori
Sa presupunem ca aplicam algoritmul Dijkstra asupra unui graf cu n varfuri si m muchii.
Initializarea necesita un timp in O(n). Alegerea lui v din bucla repeat presupune parcurgerea tuturor
varfurilor continute in C la iteratia respectiva, deci a n -1, n -2, ..., 2 varfuri, ceea ce necesita in total un
timp in O(n2). Bucla for interioara efectueaza n-2, n-3, ..., 1 iteratii, totalul fiind tot in O(n2). Rezulta ca
algoritmul Dijkstra necesita un timp in O(n2).
Incercam sa imbunatatim acest algoritm. Vom reprezenta graful nu sub forma matricii de
adiacenta L, ci sub forma a n liste de adiacenta, continand pentru fiecare varf lungimea muchiilor care
pleaca din el. Bucla for interioara devine astfel mai rapida, deoarece putem sa consideram doar varfurile
w adiacente lui v. Aceasta nu poate duce la modificarea ordinului timpului total al algoritmului, daca nu
reusim sa scadem si ordinul timpului necesar pentru alegerea lui v din bucla repeat. De aceea, vom tine
varfurile v din C intr-un min-heap, in care fiecare element este de forma (v, D[v]), proprietatea de min-
heap referindu-se la valoarea lui D[v]. Numim algoritmul astfel obtinut Dijkstra-modificat. Sa il analizam
in cele ce urmeaza.
Initializarea min-heap-ului necesita un timp in O(n). Instructiunea “C ← C {v}” consta in
extragerea radacinii min-heap-ului si necesita un timp in O(log n). Pentru cele n–2 extrageri este nevoie
de un timp in O(n log n).
Pentru a testa daca “D[w] > D[v]+L[v, w]”, bucla for interioara consta acum in inspectarea
fiecarui varf w din C adiacent lui v. Fiecare varf v din C este introdus in S exact o data si cu acest prilej
sunt testate exact muchiile adiacente lui; rezulta ca numarul total de astfel de testari este de cel mult m.
Daca testul este adevarat, trebuie sa il modificam pe D[w] si sa operam un percolate cu w in min-heap,
ceea ce necesita din nou un timp in O(log n). Timpul total pentru operatiile percolate este deci in
O(m log n).
In concluzie, algoritmul Dijkstra-modificat necesita un timp in O(max(n, m) log n). Daca graful
este conex, atunci m ≥ n si timpul este in O(m log n). Pentru un graf rar este preferabil sa folosim
algoritmul Dijkstra-modificat, iar pentru un graf dens algoritmul Dijkstra este mai eficient.
Este usor de observat ca, intr-un graf G neorientat conex, muchiile celor mai scurte drumuri de la
un varf i la celelalte varfuri formeaza un arbore partial al celor mai scurte drumuri pentru G. Desigur,
acest arbore depinde de alegerea radacinii i si el difera, in general, de arborele partial de cost minim al lui
G.
Problema gasirii celor mai scurte drumuri care pleaca din acelasi punct se poate pune si in cazul
unui graf neorientat.
11.6 Euristica greedy
Pentru anumite probleme, se poate accepta utilizarea unor algoritmi despre care nu se stie daca
furnizeaza solutia optima, dar care furnizeaza rezultate “acceptabile”, sunt mai usor de implementat si
mai eficienti decat algoritmii care dau solutia optima. Un astfel de algoritm se numeste euristic.
Una din ideile frecvent utilizate in elaborarea algoritmilor euristici consta in descompunerea
procesului de cautare a solutiei optime in mai multe subprocese succesive, fiecare din aceste subprocese
constand dintr-o optimizare. O astfel de strategie nu poate conduce intotdeauna la o solutie optima,
107](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-105-2048.jpg)



























![Bibliografie
[1.] Brassard, G., Bratley, P. “Algorithmics - Theory and Practice”, Prentice-Hall, Englewood Cliffs,
1988.
[2.] Cormen, T.H., Leiserson, C.E., Rivest, R.L. “Introduction to Algorithms”, The MIT Press,
Cambridge, Masshusetts, 1992 (eighth printing).
[3.] Ellis, M., Stroustrup, B. “The Annotated C++ Reference Manual”, Addison-Wesley, Reading,
1991.
[4.] Graham, R.L., Knuth, D.E., Patashnik, O. “Concrete Mathematics”, Addison-Wesley, Reading,
1989.
[5.] Horowitz, E., Sahni, S. “Fundamentals of Computer Algorithms”, Computer Science Press,
Rockville, 1978.
[6.] Knuth, D.E. “Tratat de programarea calculatoarelor. Algoritmi fundamentali”, Editura Tehnica,
Bucuresti, 1974.
[7.] Knuth, D.E. “Tratat de programarea calculatoarelor. Sortare si cautare”, Editura Tehnica,
Bucuresti, 1976.
[8.] Lippman, S. B. “C++ Primer”, Addison-Wesley, Reading, 1989.
[9.] Livovschi, L., Georgescu, H. “Sinteza si analiza algoritmilor”, Editura Stiintifica si Enciclopedica,
Bucuresti, 1986.
[10.] Morariu N, Limbaje de programare, curs ID,2003
[11.] Sedgewick, R. “Algorithms”, Addison-Wesley, Reading, 1988.
[12.] Sedgewick, R. “Algorithms in C”, Addison-Wesley, Reading, 1990.
[13.] Sethi, R. “Programming Languages. Concepts and Constructs”, Addison-Wesley, Reading, 1989.
[14.] Smith, J.H. “Design and Analysis of Algorithms”, PWS-KENT Publishing Company, Boston, 1989.
[15.] Standish, T.A. “Data Structure Techniques”, Addison-Wesley, Reading, 1979.
[16.] Stroustrup, B. “The C++ Programming Language”, Addison-Wesley, Reading, 1991.
[17.] Stroustrup, B. “The Design and Evolution of C++”, Addison-Wesley, Reading, 1994.
[18.] http://thor.info.uaic.ro/~dlucanu/
136](https://image.slidesharecdn.com/algoritmi-121014204617-phpapp02/75/Algoritmi-134-2048.jpg)

Cartea lui Valeriu Lupu abordează algoritmii din perspectiva unui curs de programare, concentrându-se pe concepte fundamentale precum greedy, divide et impera, programare dinamică și backtracking, evidențiind aspectele esteticii algoritmilor. De asemenea, oferă o introducere în limbajul Visual Basic și analizează metodele de implementare a algoritmilor prin exemple intuitive, accesibile și fără o bază matematică avansată. Cu un conținut fluid, cartea se dovedește utilă atât pentru începători, cât și pentru cei cu experiență limitată în programare.

































![крис касперски компьютерные вирусы изнутри и снаружи [2006, rus]](https://cdn.slidesharecdn.com/ss_thumbnails/2006rus-121014211832-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













