
Recommended
More Related Content
What's hot
What's hot (13)
Similar to Week10 Web Presentation
Similar to Week10 Web Presentation (20)
Recently uploaded
Recently uploaded (20)
Week10 Web Presentation
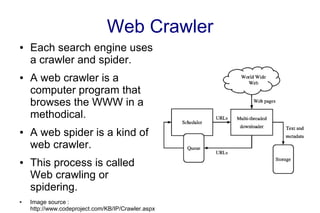
- 1. Web Crawler ● Each search engine uses a crawler and spider. ● A web crawler is a computer program that browses the WWW in a methodical. ● A web spider is a kind of web crawler. ● This process is called Web crawling or spidering. ● Image source : http://www.codeproject.com/KB/IP/Crawler.aspx
- 2. Spider A spider is a program that crawls the Internet in a specific way for a specific purpose. Spiders are the basis for modern search engines, such as Google and AltaVista. These spiders automatically retrieve data from the Web and pass it on to other applications that index the contents of the Web site for the best set of search terms. Source : http://www.ibm.com/developerworks/linux/library/l-spider/
- 3. Information Indexing Documents from an Indexing Software Index agent, are indexed by Agents an indexing software. Extract words or something Database Documents ● Information is putted into a certain database ● There are many different types of indexing ● The kind of index built how the information will be displayed.
- 4. Searching and Visiting If you visit web pages related your searching keywords, you type those in a web page. A particular search engine allow you to use several keywords for searching.
- 5. Searching An engine searched Your keyword from the database. Results are returned by HTML document. There are some additional information.
- 6. Visiting If you are interested in a title of the result page, you click the link and go to directly. Search engines or databases do not store the documents of the indexed sites.