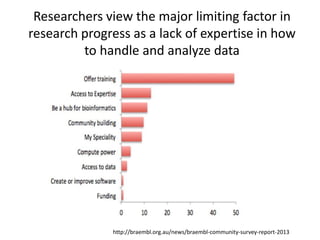
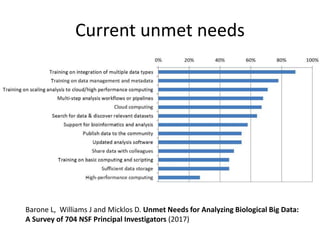
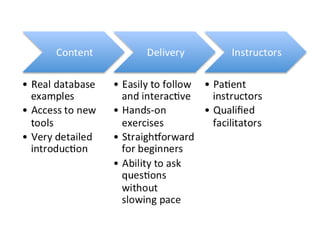
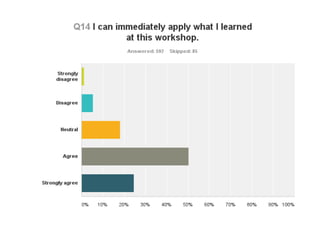
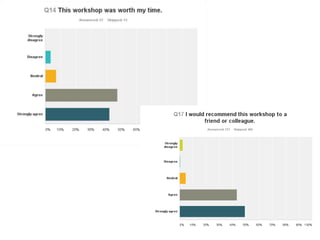
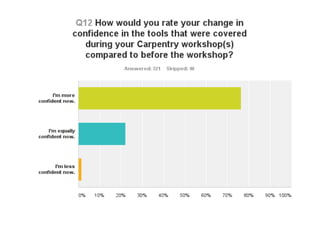
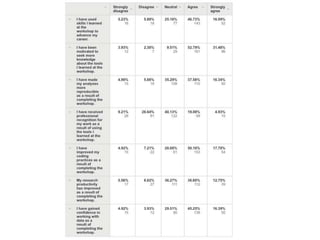
The document discusses the importance of democratizing data skills to empower researchers in managing and analyzing data effectively. It highlights initiatives such as Software and Data Carpentry, which provide hands-on workshops aimed at teaching foundational data analysis skills and fostering better practices in research. The goal is to increase confidence in computational work and improve the ability to work with data through collaborative and domain-specific training programs.