
Recommended
More Related Content
What's hot
What's hot (13)
More from 민석 김
More from 민석 김 (15)
VAE 처음부터 알아보기
- 2. VAE 알아보기 KL-divergence .. 정보이론 .. Manifold .. Variational inference 몰라요. Inference 알고리즘 몰라요.
- 6. 이전 글에서 나는 머신러닝이 주어진 데이터를 가장 잘 설명하는 ‘함수’를 찾는 알고리즘을 디자인하는 것이라 설명했다. 그러나 머신러닝은 확률의 관점에서도 설명이 가능하다. 머신러닝을 probability density를 찾는 과정으로 생각하는 것 이다. 즉, 함수를 가정하는 것이 아니라 확률 분포를 가정하고, 적절한 확률 분포의 parameter를 유추하는 과정으로 생 각하는 것이다. 주어진 데이터가 gaussian distribution으로 drawn되었다고 가정하고, 데이터와 현상을 가장 잘 설명하는 mean과 covariance를 찾는 과정과 비슷한 것이라고 생각하면 된다. 즉, 앞에서 설명한 방식은 function parameter를 찾는 방식이라면, 이제는 probability density function parameter를 찾는 것으로 바뀌는 것이다. http://sanghyukchun.github.io/58/
- 11. BAYES
- 14. Variational Inference for Machine Learning Shakir Mohamed / Google Deepmind http://nolsigan.com/blog/what-is-variational-autoencoder/ Posterior Evidence Likelihood Prior
- 15. Posterior Evidence Likelihood Prior 모든 가능한 Z에 대해, p(x,z)와 p(z)를 구해야 함 각각은 observation(likelihood), 현상에 대한 사전정보 (prior), 주어진 데이터에 대한 현상의 확률 (posterior)을 의미한다. http://nolsigan.com/blog/what-is-variational-autoencoder/
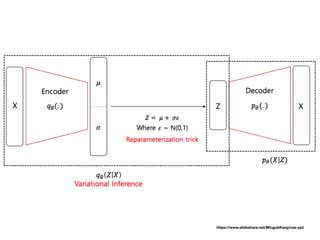
- 16. 우리의 variational posterior q(z∣x) 가 진짜 posterior p(z∣x) 를 얼마나 잘 근사하는지 어떻게 알 수 있을까?
- 17. 확률과 정보량
- 18. 확률에 대한 정보량 이산확률분포에 대한 평균정보량 Variational Inference / norman3.github.io
- 19. Variational Inference / norman3.github.io P, Q의 평균정보량 P의 평균정보량
- 20. Variational Inference / norman3.github.io
- 22. 하나의 이벤트 집합에서 P, Q 두개의 확률분포에 대한 평균정보량을 크로스 엔트로피로 함. p, q의 크로스 엔트로피 p의 엔트로피 https://en.wikipedia.org/wiki/Cross_entropy
- 24. 우리의 variational posterior q(z∣x) 가 진짜 posterior p(z∣x) 를 얼마나 잘 근사하는지 어떻게 알 수 있을까?
- 25. 근사추론의 방법
- 31. http://nolsigan.com/blog/what-is-variational-autoencoder/ Tutorial on Variational Autoencoders / CARL DOERSCH arXiv:1606.05908v2
- 32. Variational Inference / David M. Blei
- 33. 우리는 q와 그에 대한 lambda를 바꾸고 다루고 있는데, Variational Inference / David M. Blei http://nolsigan.com/blog/what-is-variational-autoencoder/ 좋은 posterior 근사를 얻는 방법으로..
- 34. minibatch..
- 35. 뉴럴넷
- 41. Tutorial on Variational Autoencoders / CARL DOERSCH arXiv:1606.05908v2
- 42. MLE 로 parameter를 추정하는데, 앞서본 것처럼 ELBO 최대화해서.. 추정 (b)를 계산할 때, 실제 코드에 사용하는 식
- 49. http://pyro.ai/examples/vae.html Notes on Variational Autoencoders
- 50. Variational Inference for Machine Learning Shakir Mohamed / Google Deepmind Non-independent : Markovian https://stackoverflow.com/questions/13058379/example-for-non-iid-data https://www.quora.com/What-is-non-stationary-data?utm_medium=organic
- 51. E[𝑓]= Sigma( 𝑝(𝑥)𝑓(𝑥) ) E[𝑓]= Integral( 𝑝(𝑥)𝑓(𝑥)𝑑𝑥 )