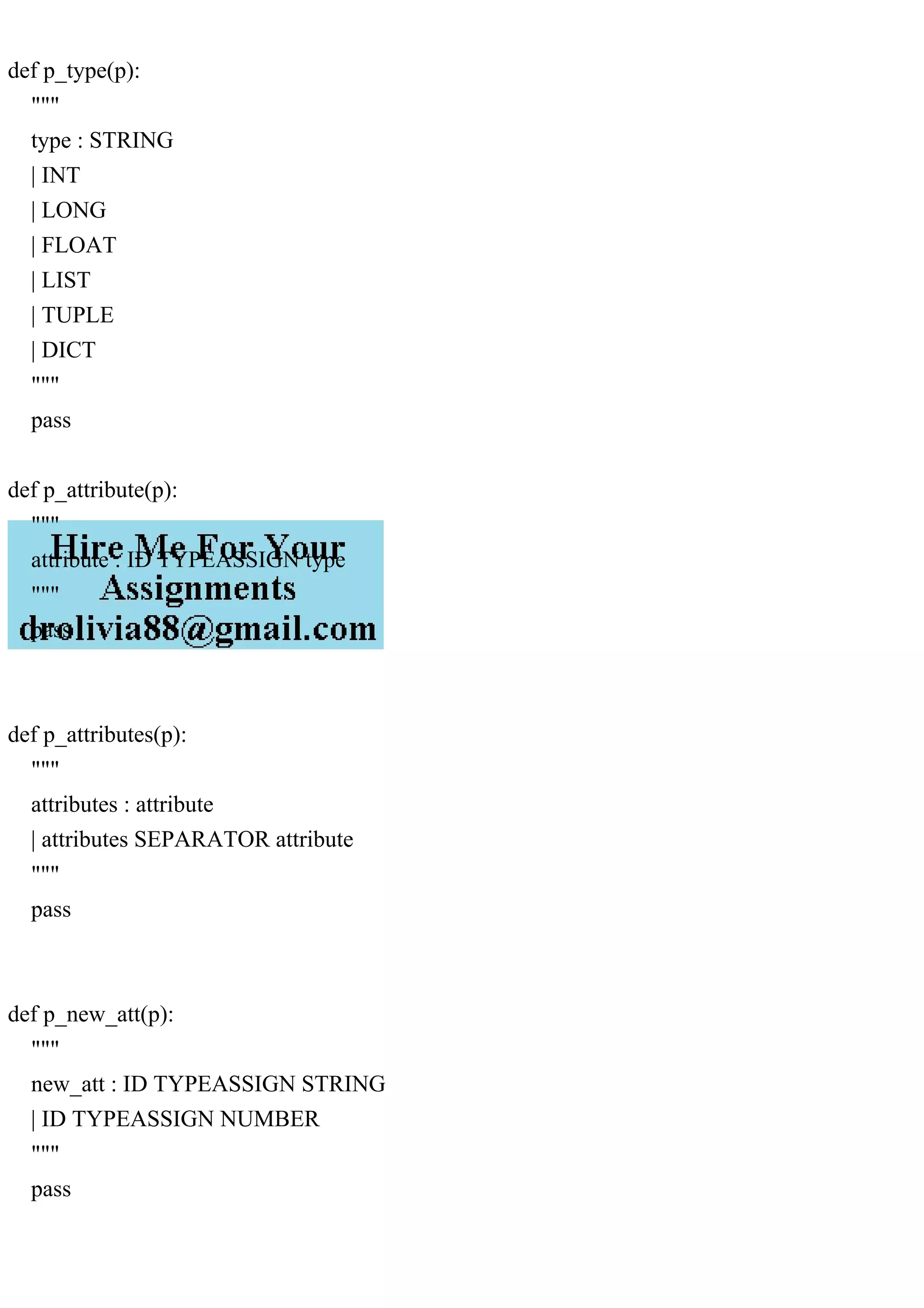
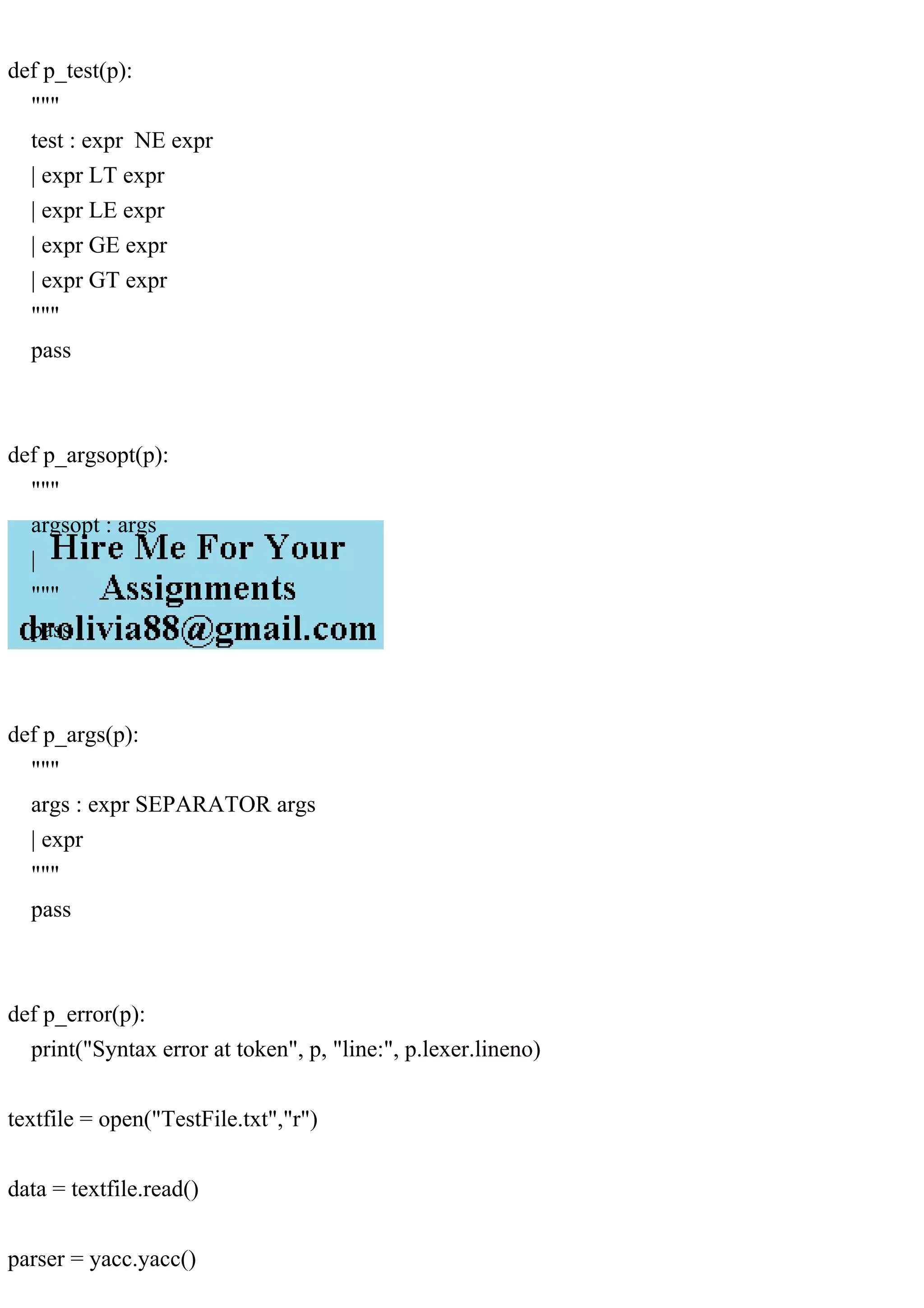
This document details an assignment for implementing semantics in a small programming language for blockchain applications. It outlines the requirements for validity checks on blockchain attributes, error handling during parsing, and the implementation of arithmetic expressions. Additionally, it includes definitions of tokens and constructs necessary for the language's lexical analysis and parsing.


![t_ignore_WHITESPACE = r's+'
keywords = {
'BLOCK': 'KEYWORD',
'VAR': 'KEYWORD',
'ADD': 'KEYWORD',
'PRINT': 'KEYWORD',
'VIEW': 'KEYWORD',
'RUN': 'KEYWORD',
'MINE': 'KEYWORD',
'EXPORT': 'KEYWORD',
'STR':'KEYWORD',
'INT': 'KEYWORD',
'LONG': 'KEYWORD',
'FLOAT': 'KEYWORD',
'LIST': 'KEYWORD',
'TUPLE': 'KEYWORD',
'DICT':'KEYWORD',
}
tokens1 = ['ID',
'BLOCK','VAR','ADD','PRINT','VIEW','RUN','MINE','EXPORT','STRING','LONG','FLOAT','L
IST','TUPLE','DICT','NUMBER','ASSIGN','TYPEASSIGN','SEPARATOR','LPAREN','RPARE
N','NE','LT','GT','LE','GE','PLUS','MINUS','STAR','SLASH', 'PCT',
'COMMENT','WHITESPACE']
+ list(keywords.values())
# dictionary to store values
values = {}
def t_KEYWORD(t):
r'DEF | VAR | INT | IF | ELSE'
t.type = keywords.get(t.value, 'KEYWORD')
return t](https://image.slidesharecdn.com/youhavealreadyimplementedalexicalanalyzerinassignment1and-230329152656-afaf31d6/75/You-have-already-implemented-a-lexical-analyzer-in-Assignment-1-and-pdf-3-2048.jpg)
![def t_ID(t):
r'[a-zA-Z_][a-zA-Z_0-9]*'
t.type = keywords.get(t.value, 'ID')
return t
def t_NUM(t):
r'[0-9]+'
t.type = keywords.get(t.value, 'INT')
return t
def t_COMMENT(t):
r'//.'
t.type = keywords.get(t.value, 'COMMENT')
pass
def t_newline(t):
r'n+'
t.lexer.lineno += len(t.value)
def t_error(t):
print("Illegal character '%s'" % t.value[0])
t.lexer.skip(1)
def p_block(p):
"""
block : BLOCK ID ASSIGN LPAREN attributes RPAREN
| ADD ID ASSIGN LPAREN new_atts RPAREN
| PRINT ID
| RUN ID
| MINE ID
| EXPORT ID
| VIEW ID
"""
pass](https://image.slidesharecdn.com/youhavealreadyimplementedalexicalanalyzerinassignment1and-230329152656-afaf31d6/75/You-have-already-implemented-a-lexical-analyzer-in-Assignment-1-and-pdf-4-2048.jpg)