Download to read offline




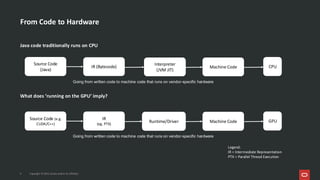

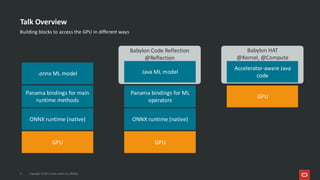
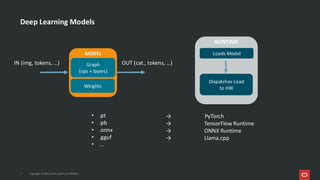


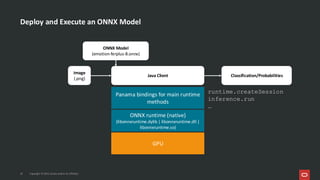

![What’s Inside an ONNX Model
Model metadata
• version, description, ...
Graph structure
• operators and tensors
Initializers (weights)
• can be large chunks of binary data (float32, int64, etc.)
Inputs and outputs
• Example: input is float[1, 1, 64, 264], output is float[1, 8].
13 Copyright © 2025, Oracle and/or its affiliates
https://netron.app/](https://image.slidesharecdn.com/writinggpu-readyaimodelsinpurejavawithbabylon-251106152343-f7a06d62/85/Writing-GPU-Ready-AI-Models-in-Pure-Java-with-Babylon-13-320.jpg)
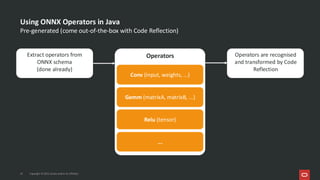
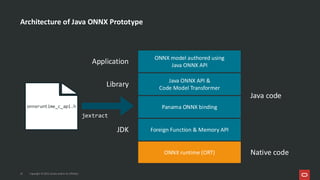


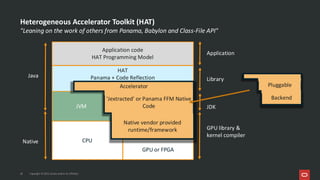
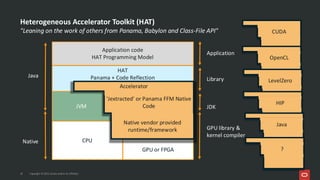
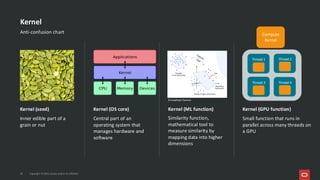

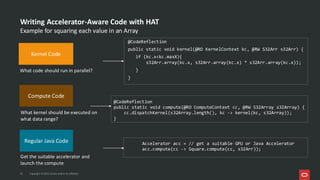
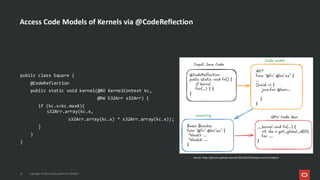

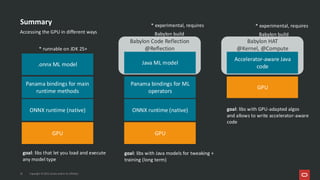


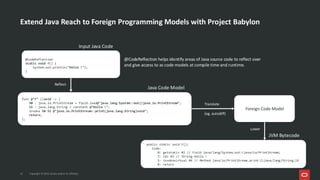
Project Babylon introduces the experimental Code Reflection technology that lets you define machine learning logic in plain Java code, without needing Python or external model files. It then uses Foreign Function and Memory (FFM) API to connect your code to native runtimes like ONNX Runtime for fast inference, including GPU acceleration. Furthermore, the Heterogeneous Accelerator Toolkit (HAT) provides a developer-facing programming model for writing and composing compute kernels, which can be more broadly applied-allowing Java libraries to seamlessly harness GPU power for high-performance computing tasks. Presented at JFall 2025 by Ana-Maria Mihalceanu and Lize Raes



































































