Download to read offline


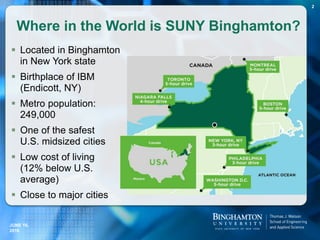


































![ Consider only fact statements (will be called doubtful
statements) with a single specified doubt unit (denoted in [
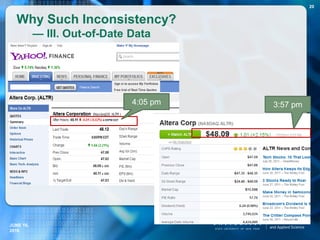
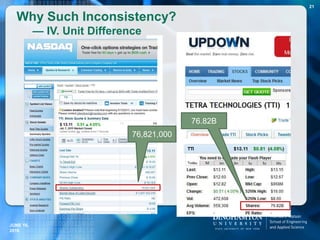
]) and a single truthful answer.
Example: China has [35] provinces.
doubtful statement = doubt unit + topic units
Example: For “China has [35] provinces”,
doubt unit = “35”
topic units = {“China”, “provinces”}
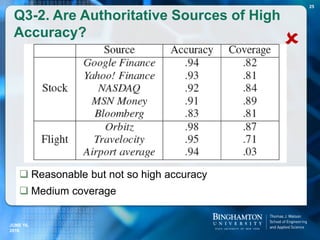
Restricted Fact Statements
62
JUNE 16,
2016](https://image.slidesharecdn.com/weiyimeng-webdatatruthfulnessanalysis-160616081621/85/Weiyi-meng-web-data-truthfulness-analysis-59-320.jpg)

























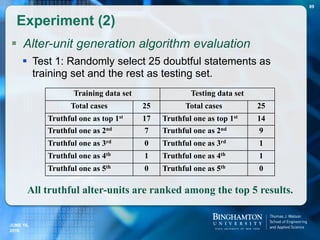


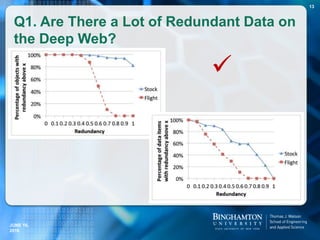
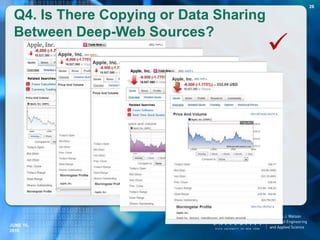
![T-verifier Answers.com Yahoo! answers
Total statements 50 50 50
Wrong results 5 4 12
Cannot find results 0 6 18
Correct Results 45 40 20
95
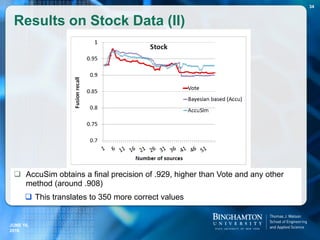
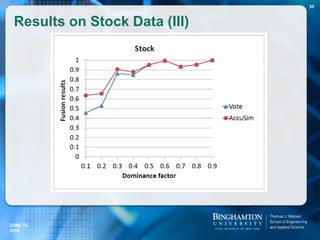
How does T-verifier compare with two
popular Web QA Systems?
Example Statement Answers.com can’t find result:
[800] people died when the Estonia sank in 1994.
Example Statement Answers.com gives wrong result:
[20] hexagons are on a soccer ball
Correct answer: 20, Answers.com gives: 32
JUNE 16,
2016](https://image.slidesharecdn.com/weiyimeng-webdatatruthfulnessanalysis-160616081621/85/Weiyi-meng-web-data-truthfulness-analysis-92-320.jpg)
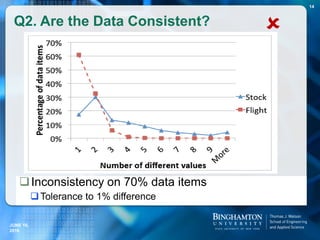
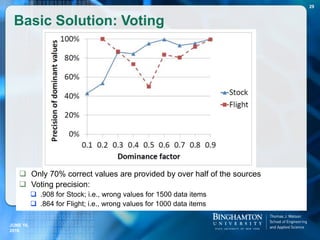
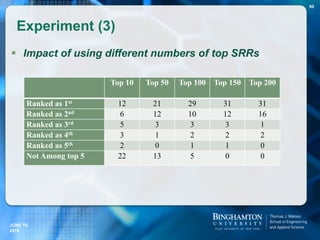
![ This type of statements will be called MTA statements.
Examples of MTA statements:
Doubtful Statements with Multiple
Truthful Alternatives
96
Type Doubtful statements Truthful alternatives
CC Barack Obama was born in [Kenya]. Honolulu, Hawaii, United States
MVA [Edwin Krebs] won the Nobel Prize in
medicine in 1992.
Edwin Krebs, Edmond Fischer
SFE [Peter Ustinov] has portrayed Hercule
Poirot.
Peter Ustinov, David Suchet,
Agatha Christie
DSC [U.S.] won team title at the 2011
World Gymnastics Championships.
U.S., China
TS [Bob Dole] served as the President of
the United States.
Barack Obama since Jan 2009,
George Bush from Jan 2001 to Jan
2009, …
JUNE 16,
2016](https://image.slidesharecdn.com/weiyimeng-webdatatruthfulnessanalysis-160616081621/85/Weiyi-meng-web-data-truthfulness-analysis-93-320.jpg)




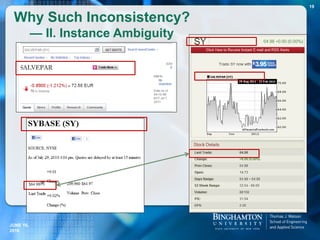
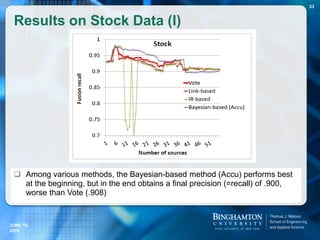
![Five types of MTA statements have been identified.
Type 1: Compatible Concepts (CC). For each MTA statement of
this type, its truthful alter-units are compatible to each other.
Usually, these alter-units either are equivalent to each other
(i.e., synonyms) or correspond to the same basic concept but
with different specificity/generality (i.e., hyponyms/hypernyms)
or with different granularity (i.e., one is a part of another).
Example 1: For “Barack Obama was born in [Honolulu]”, truthful
alternatives include “Honolulu”, “Hawaii”, “United States”, etc.
Example 2: For “Queen Elizabeth II resided in [United
Kingdom]”,
correct alter-units include “United Kingdom”, “England” and
“Great Britain”.
Different Types of MTA Statements (1)
101
JUNE 16,
2016](https://image.slidesharecdn.com/weiyimeng-webdatatruthfulnessanalysis-160616081621/85/Weiyi-meng-web-data-truthfulness-analysis-98-320.jpg)
![ Type 2: Multi-Valued Attributes (MVA). For each MTA
statement of this type, the truthful alter-units correspond to
different values of a multi-valued attribute in a relational
database. A multi-valued attribute may have multiple values for
a given entity (record).
Example: For “[Edwin Krebs] won the Nobel Prize in medicine in
1992”, two US biochemists “Edwin Krebs” and “Edmond”
Fischer” shared the 1992 Nobel Prize in medicine (they are
values of the multi-valued attribute “Recipients” of a Nobel
Prize record); therefore both of them are truthful alter-units.
Different Types of MTA Statements (2)
102
JUNE 16,
2016](https://image.slidesharecdn.com/weiyimeng-webdatatruthfulnessanalysis-160616081621/85/Weiyi-meng-web-data-truthfulness-analysis-99-320.jpg)
![ Type 3: Shared-Feature Entities (SFE). Many entities share a
common feature. In this case, when trying to find entities that
have this feature, multiple entities may be detected.
Example: For “[Peter Ustinov] has portrayed Hercule Poirot”, all
actors who have portrayed Hercule Poirot in different movies
(including remakes) are truthful alter-units. The truthful alter-
units include Peter Ustinov, David Suchet and Agatha Christie.
Difference between the SFE type and the MVA type: For the
former, multiple entities share a common feature, while for the
latter, the same entity has multiple values for an attribute.
In reality, values of the same multi-valued attribute are much
more likely to co-occur compared to the entities that share the
same feature.
Different Types of MTA Statements (3)
103
JUNE 16,
2016](https://image.slidesharecdn.com/weiyimeng-webdatatruthfulnessanalysis-160616081621/85/Weiyi-meng-web-data-truthfulness-analysis-100-320.jpg)
![ Type 4: Different Sub-Categories (DSC). Different sub-
categories related to some of the topic units of the doubtful
statement. A topic unit of a doubtful statement DS is a
term/phrase in DS different from the doubt unit. When a topic
unit is replaced by different sub-categories, the doubt unit may
have different truthful alter-units, making the doubtful statement
an MTA statement.
Example: For “[U.S.] won team title at the 2011 World
Gymnastics Championships”, topic unit “World” could be
replaced by “US”, “Europe”, etc. and “team” could be replaced
by “men’s team” or “women’s team”. Each replaced can lead to
a different truthful alter-unit.
Different Types of MTA Statements (4)
104
JUNE 16,
2016](https://image.slidesharecdn.com/weiyimeng-webdatatruthfulnessanalysis-160616081621/85/Weiyi-meng-web-data-truthfulness-analysis-101-320.jpg)
![ Type 5: Time-Sensitive (TS).
A fact statement is a time-sensitive statement if its truthfulness
changes over time with a fairly regular pattern on time or such
change is expected even though there is no such regularity.
Since there may be different truthful alter-units at different times
for such type of statements, they are MTA statements.
Example: A time-sensitive statement with a fairly regular pattern
is US presidents (serve 4 or 8 years).
Example: A time-sensitive statement with less regularity is “A
new world 100-meter track record was established by [Usain
Bolt]” because it is generally not predictable who will establish a
new record in the future.
Different Types of MTA Statements (5)
105
JUNE 16,
2016](https://image.slidesharecdn.com/weiyimeng-webdatatruthfulnessanalysis-160616081621/85/Weiyi-meng-web-data-truthfulness-analysis-102-320.jpg)












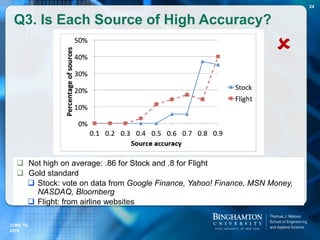
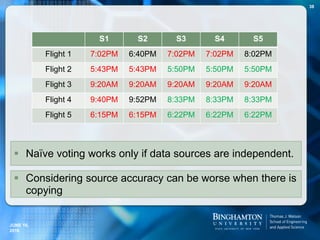
The document summarizes a talk on analyzing the truthfulness of web data. It discusses analyzing structured data from two domains - stock prices and flight statuses - from multiple online sources. It was found that there is a lot of redundant data across sources, but also significant inconsistencies. Various techniques were explored to resolve inconsistencies and find true values, such as voting methods that leverage source accuracy and ignore copied data. Detecting copying between sources is important for improving truth finding but also computationally challenging. Scaling up copy detection methods can help address this challenge.












































































