Downloaded 112 times







































![Coroutines in event loop
#!/usr/local/bin/python3.5
import asyncio
import aiohttp
async def get_page(url):
response = await aiohttp.request('GET', url)
body = await response.read()
print(body)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait([get_page('http://python.org'),
get_page('http://pycon.org')]))](https://image.slidesharecdn.com/webscrapingasyncio1-161106134948/85/Webscraping-with-asyncio-44-320.jpg)


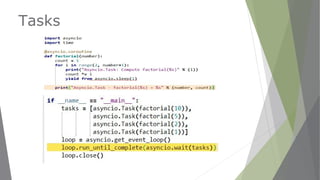









![Async Web crawler
import asyncio
import random
@asyncio.coroutine
def get_url(url):
wait_time = random.randint(1, 4)
yield from asyncio.sleep(wait_time)
print('Done: URL {} took {}s to get!'.format(url, wait_time))
return url, wait_time
@asyncio.coroutine
def process_results_as_come_in():
coroutines = [get_url(url) for url in ['URL1', 'URL2', 'URL3']]
for coroutine in asyncio.as_completed(coroutines):
url, wait_time = yield from coroutine
print('Coroutine for {} is done'.format(url))
def main():
loop = asyncio.get_event_loop()
print(“Process results as they come in:")
loop.run_until_complete(process_results_as_come_in())
if __name__ == '__main__':
main()
asyncio.as_completed](https://image.slidesharecdn.com/webscrapingasyncio1-161106134948/85/Webscraping-with-asyncio-60-320.jpg)
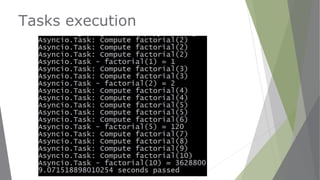
![Async Web crawler
import asyncio
import random
@asyncio.coroutine
def get_url(url):
wait_time = random.randint(1, 4)
yield from asyncio.sleep(wait_time)
print('Done: URL {} took {}s to get!'.format(url, wait_time))
return url, wait_time
@asyncio.coroutine
def process_once_everything_ready():
coroutines = [get_url(url) for url in ['URL1', 'URL2', 'URL3']]
results = yield from asyncio.gather(*coroutines)
print(results)
def main():
loop = asyncio.get_event_loop()
print(“Process results once they are all ready:")
loop.run_until_complete(process_once_everything_ready())
if __name__ == '__main__':
main()
asyncio.gather](https://image.slidesharecdn.com/webscrapingasyncio1-161106134948/85/Webscraping-with-asyncio-62-320.jpg)

![Async Web crawler
import asyncio
import random
@asyncio.coroutine
def get_url(url):
wait_time = random.randint(1, 4)
yield from asyncio.sleep(wait_time)
print('Done: URL {} took {}s to get!'.format(url, wait_time))
return url, wait_time
@asyncio.coroutine
def process_ensure_future():
tasks= [asyncio.ensure_future(get_url(url) )for url in ['URL1',
'URL2', 'URL3']]
results = yield from asyncio.wait(tasks)
print(results)
def main():
loop = asyncio.get_event_loop()
print(“Process ensure future:")
loop.run_until_complete(process_ensure_future())
if __name__ == '__main__':
main()
asyncio.ensure_future](https://image.slidesharecdn.com/webscrapingasyncio1-161106134948/85/Webscraping-with-asyncio-64-320.jpg)




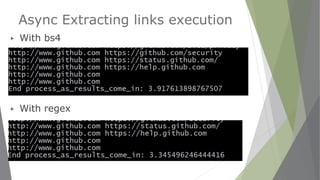








The document discusses using asyncio to perform asynchronous web scraping in Python. It begins with an overview of common Python web scraping tools like Requests, BeautifulSoup, Scrapy. It then covers key concepts of asyncio like event loops, coroutines, tasks and futures. It provides examples of building an asynchronous web crawler and downloader using these concepts. Finally, it discusses alternatives to asyncio for asynchronous programming like ThreadPoolExecutor and ProcessPoolExecutor.











































































































