Downloaded 19 times



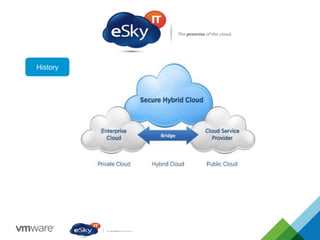




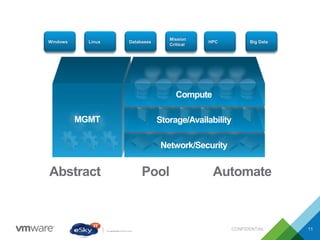
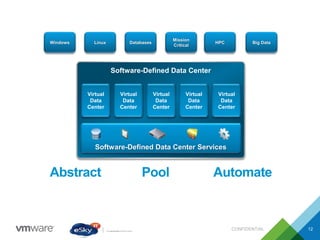


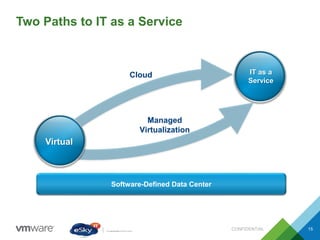
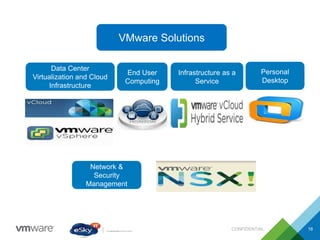

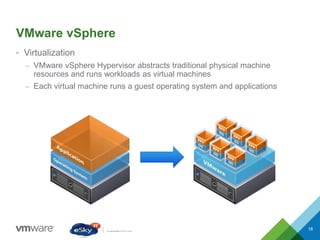


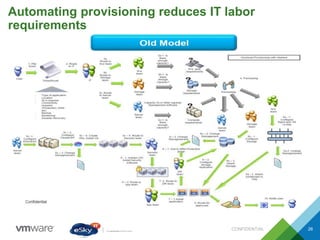
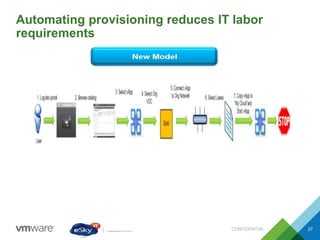
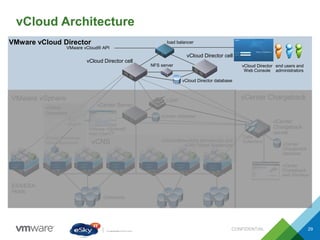


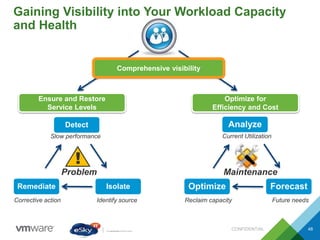

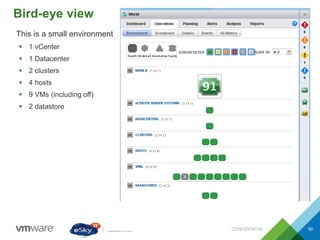
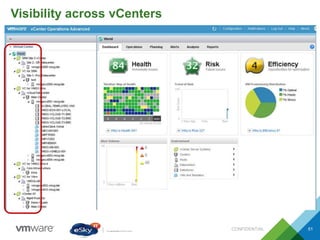
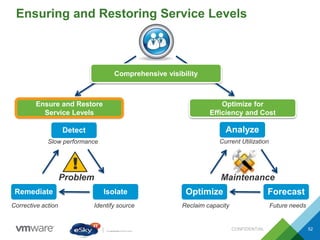
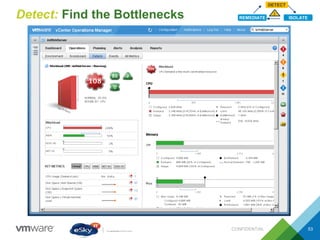

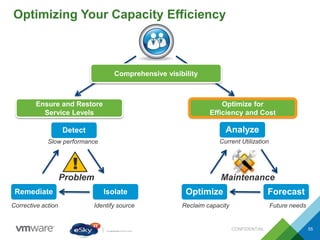

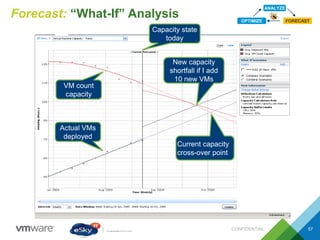
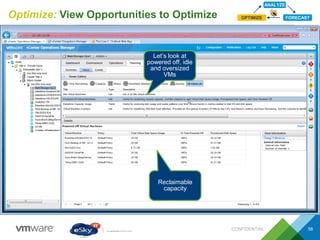

























This document provides an agenda and overview of VMware solutions that can be presented, including profiles of eSky IT and VMware's vision, as well as discussions of VMware vSphere, vCloud Suite, vCenter Operation Manager, and VMware Health Check Service. Key aspects of the VMware software-defined data center approach are explained such as abstracting, pooling, and automating infrastructure resources.


























































