За мен
● ВеселинНиколов
● @dzver
● Работя в Automattic
● PHP, MySQL,
WordPress
3.
Работата ми преди
●MS SQL Server 2005
● MySQL < 5.1, 5.1
● 1-2-3 сървъра
● Сложни схеми
● Недостатъчни ресурси
4.
Работата ми преди
●Stored Procedures
● Triggers
● SQL Jobs живеещи в DB сървъра
● Конструирани заявки с много случаи
● Materialized Views
● Foreign Keys
● Продължителна замяна на логика с курсори
с логика без курсори
5.
Умножете по 1000
●Проблеми с натоварване и много работа по
оптимизиране на сложните заявки
● Денормализация
● Много промени в схемата
Шок
● Примитивни заявки,предимно primary key
lookups. Join decomposition.
● Редки и твърде скъпи промени в схемата
● Нови проблеми като replication lag и риск от
чупене услугата
9.
Работата ми сега
●MySQL
● Прости заявки
● Огромни обеми заявки
● Множество сървъри
● WordPress
● Memcached
10.
Често срещани проблеми
●Много на брой заявки
● Заявки по големи таблици без индекси
● Offsets
● Много сортиране
● Избиране на голям обем данни
11.
Често срещани проблеми
●Много на брой заявки
● Заявки по големи таблици без индекси
● Offsets
● Много сортиране
● Избиране на голям обем данни
12.
Много на бройзаявки
● Нещо много навътре в кода вика не-
кеширана заявка.
13.
Решения
● WordPress DebugBar
https://wordpress.org/plugins/debug-bar/
● WordPress Options API
http://codex.wordpress.org/Options_API
● Caching
wp_cache_set, wp_cache_get
14.
Debug Bar
● Втестова среда показва всички заявки
● Може да показва и всички hooks, remote
requests, memcached stats etc.
15.
Log
● MySQL SlowLog вече поддържа 0 сек
● Може да се ползва pt-query-digest
● SHOW FULL PROCESSLIST
● SHOW PROFILE
● MS SQL има безкрайно удобен
профайлър :-)
16.
Options API
● Таблицас keys и values
● Кеширана е като 1 масив за blog
● Масивът се съхранява в глобална
променлива (чрез object cache)
● Инвалидация на кеша при set/add/delete
=> 1 заявка на много хиляди requests
17.
Кеширане
● Не енужно да се кешира всичко
● Има много нива на кеширане
- Object Cache
- Query Cache
- Memcached
- Batcache
И понякога денормализация
18.
Кеширане. MySQL QueryCache
Query Cache = 0
● Кешът се инвалидира при всеки insert/update
● Овърхедът често е по-голям от ползите
● В някои случаи е полезен, но в рамките на
„десетки мегабайти“.
19.
Кеширане. Batcache
WordPress plugnза съхраняване на цели
страници в Memcache или APC
● http://evansolomon.me/notes/faster-wordpress-multisite-nginx-batcache/
● https://wordpress.org/plugins/batcache/
● http://xkcd.com/908/
20.
wp_cache_get, object cache
●wp_cache_get, wp_cache_add, wp_cache_set,
wp_cache_delete
● Object Cache за избягване на повторни
обръщения към Memcahce
21.
Често срещани проблеми
●Много на брой заявки
● Заявки по големи таблици без индекси
● Offsets
● Много сортиране
● Избиране на голям обем данни
22.
Липса на индекс
ALTER`table` ADD index ..
Всеки сложен проблем има едно просто решение,
което обикновено е грешно.
23.
Липса на индекс
●Индексите са скъпи
● Обновяването им натоварва сървъра
● Поддържането им в паметта е скъпо
● Допълнителен овърхед за query optimizer
● Не е голяма беля, ако не се събират в
паметта.
24.
Често срещани проблеми
●Много на брой заявки
● Заявки по големи таблици без индекси
● Твърде много индекси
● Offsets
● Много сортиране
● Избиране на голям обем данни
25.
Липса на индекс- решения
● Употреба на прости заявки
● Отбягване на комплексни JOINs
● EXPLAIN SELECT преди commit
● Primary Key само по `id`
данните са клъстърирани по PK, употреба на
комплексен PK може да е полезна в някои приложения
26.
Липса на индекс
Forjoin queries, the number of possible plans
investigated by the MySQL optimizer grows
exponentially with the number of tables
referenced in a query.
http://dev.mysql.com/doc/refman/5.7/en/controlling-query-plan-evaluation.html
27.
Малко за индексите
Прииндекси върху повече от 1 поле, редът
има значение:
INDEX foo(A, B, C)
● WHERE A = 3
● WHERE A = 3, B = 4, C = 5
● WHERE B = 5, C = 7
28.
Често срещани проблеми
●Много на брой заявки
● Заявки по големи таблици без индекси
● Твърде много индекси
● Offsets
● Много сортиране
● Избиране на голям обем данни
Offsets
Прости решения:
SELECT *FROM ...
WHERE `id` > 1093029 LIMIT 20
SELECT * FROM ...
WHERE `ts` BETWEEN '2014-04-11' AND
...
32.
Offsets
Сложно решение:
SELECT *FROM `table` JOIN (
SELECT `id` FROM `table`
ORDER BY `whatever`
LIMIT 5000,50
) as `b` USING `id`
33.
Често срещани проблеми
●Много на брой заявки
● Заявки по големи таблици без индекси
● Offsets
● Много сортиране
● Избиране на голям обем данни
34.
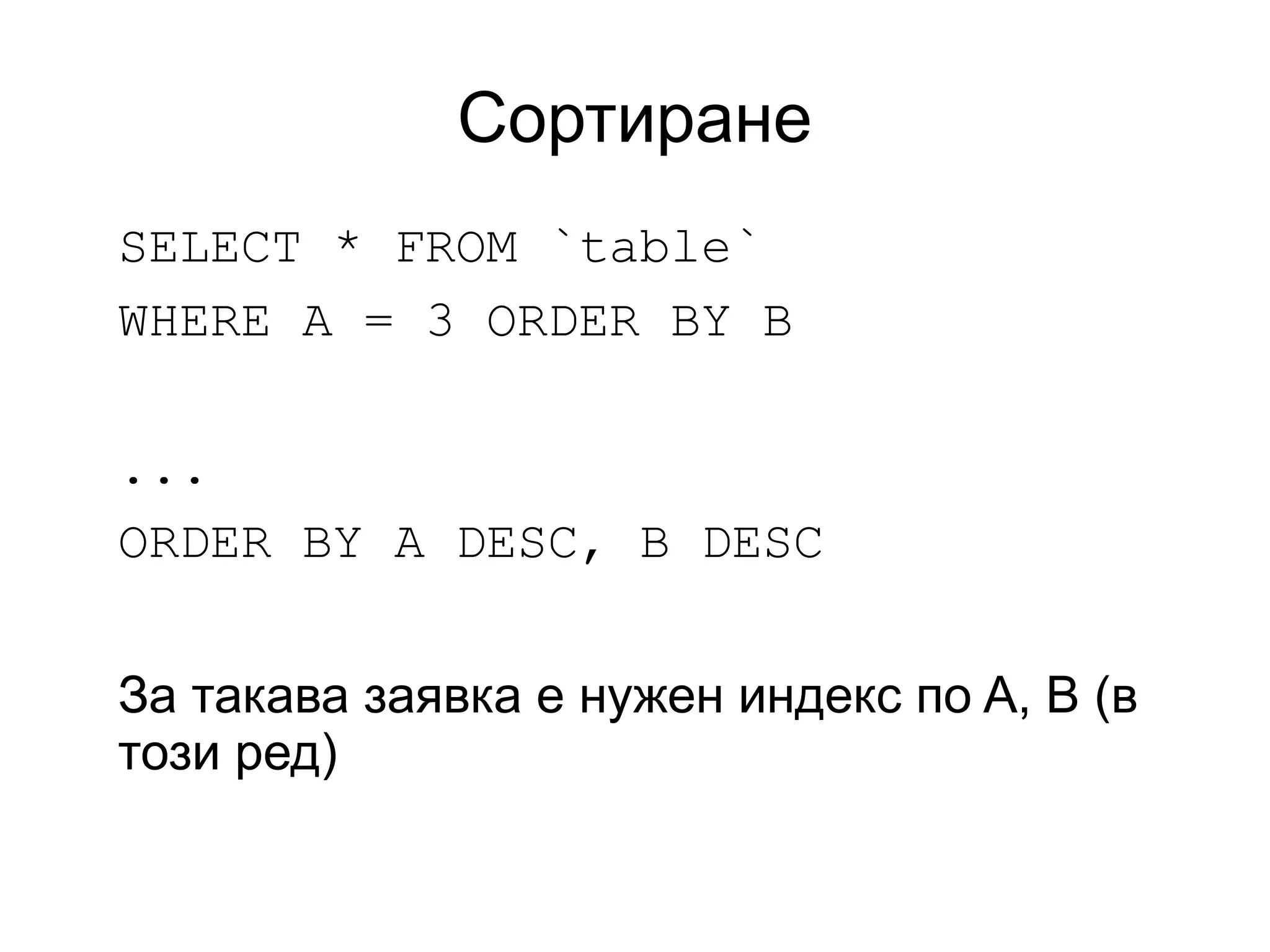
Сортиране
Using filesort; Usingtemporary;
● Не е rocket science
● Сортиране по индексирана колона
● Индексът е подреден
● Ако подходящ индекс за вашата заявка,
сървърът ползва filesort
35.
Сортиране
SELECT * FROM`table`
WHERE A = 3 ORDER BY B
...
ORDER BY A DESC, B DESC
За такава заявка е нужен индекс по A, B (в
този ред)
36.
Още малко заиндекси...
INDEX(A,B) няма да се ползва при:
● WHERE A > 5 ORDER BY B
● WHERE 1=1 ORDER BY B
● ORDER BY A DESC, B ASC
http://www.percona.com/files/presentations/WEBINAR-MySQL-Indexing-Best-Practices.pdf
Antipattern
Употребата на функциив заявките прави
безполезен Query Cache
SELECT * FROM `table`
WHERE my_date = current_date()
SELECT * FROM `table`
WHERE my_date = '2014-05-19'
39.
SELECT на многоданни
● Cronjobs, one-time scripts
● Вътрешно паджиниране по ID
● Работа с блокове от по 100-1000 записа
40.
WordPress.com специфики
● 500000 000+ таблици
● 600+ DB сървъра
● Master/Slave, partitions, shards, често
таблиците са на различни сървъри
● HyperDB to rule them all
41.
HyperDB
● HyperDB емощен DB клас
● Поддаржа репликация
● Парсва заявките, за да открие към кои
сървъри да се закачи
● Поддържа read и write servers
● Поддържа partitions
42.
HyperDB
● Обичайно четеот slaves (read servers)
● Винаги пише в masters
● При UPDATE/INSERT преминава към master
сървър за дадената таблица
43.
Replication Lag
● Мастърсървърът получава заявка
● Заявката се записва в бинлог
● Заявката се изпълнява на мастъра
● Слейвът създава thread, който се закача към
мастъра и изисква новите заявки
● Мастърът създава binlog dump за всеки слейв
● Слейв сървърът изпълнява заявките
http://barry.wordpress.com/2011/07/20/hyperdb-lag-detection/
44.
Replication Lag
Много нещамогат да се счупят:
● Слейвът може да не може да изпълни заявките със
същата скорост
● Бавни заявки на слейва или explicit locks могат да
принудят нишката, която синхронизира да чака
● Бавните заявки на мастъра ще са все така бавни и
на слейва
● Disk I/O, Network issues
45.
Replication Lag
Защо елошо:
● Възможно е да се прочетат стари данни
● Възможно е да се запишат стари данни
● HyperDB знае кои сървъри са лагнати, но
това не ни спасява да мислим заявките си.
46.
WordPress.com специфики
● Предпочитамеголямо количество малки
заявки пред малко количество големи
● Таблиците може да не се виждат една друга
в текущия connection на HyperDB
● Рядко ползваме JOINS
47.
WordPress.com специфики
● Употребатана дебели JOINS във вашия
проект може да е оправдана
● Избягвайте correlated subqueries
● Ако базата данни поддържа
материализирани изгледи, why not?
(CouchDB, MS SQL, PostgreSQL)
48.
Joins...
● Полетата, коитосе ползват в ON / USING
трябва да са с индекси
● GROUP BY / ORDER BY трябва да са по
една таблица
● Ползвайте JOIN вместо всякакви форми на
subquery
49.
Търсене
● LIKE '%foo%'- лоша идея.
● LIKE 'foo%' - възможен индекс
● MATCH ( name ) AGAINST ( 'foo' ) - Full Text
Search (поддържа се от MyISAM и InnoDB
MySQL 5.6+)
● SphinxSearch, Lucene, Solr, ElasticSearch