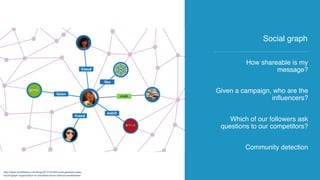
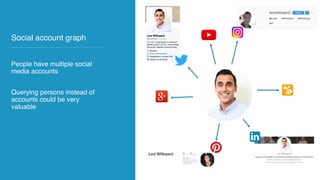
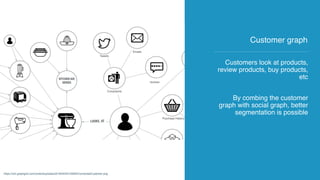
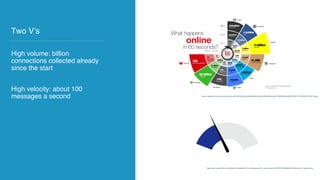
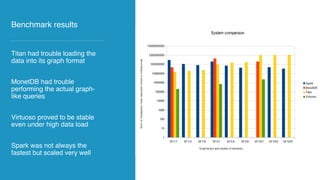
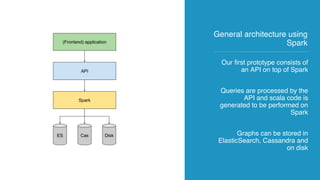
The document discusses the development of AI and data applications for social media monitoring and analytics by a startup founded in 2011. It highlights various graphs and data management challenges, such as data security and scalability, using technologies like Spark and Elasticsearch. Key requirements include SaaS for graph analytics and the ability to handle high-volume data traffic while ensuring customer data privacy.










![Namespaces to keep the data
model as general as possible
to cope with the different
graphs
Data definitions
Data model {
"_namespace": "com.obi4wan.social",
"_types": [
{
"_type": "message",
"_fields": {
"content": {
"_type": "generic.message"
},
"date": {
"_type": "generic.datetime"
},
"hashtags" : {
"_type": "com.obi4wan.social.hashtag",
"_structure": "list"
},
"author": {
"_type": "com.obi4wan.social.account"
}
}
}
]
}](https://image.slidesharecdn.com/presentationobi4wangraphs-180115152021/85/Use-case-processing-multiple-graphs-17-320.jpg)
![JSON base query language for
defining query steps
search: search using
elasticsearch
enrich: join previous step on
subgraph
Query plan
{
"queryplan": [
{
"graph": {
"v": "com.obi4wan.social.message"
}
},
{
"search": {
"field": "com.obi4wan.social.message.content",
"query": "fire OR smoke"
}
},
{
"enrich": {
"type": "com.obi4wan.social.account",
"on": {
"old": "com.obi4wan.social.message.author",
"nw": "com.obi4wan.social.account.url"
}
}
},
{
"enrich": {
"type": "com.obilytics.people.account",
"on": {
"old": "com.obi4wan.social.account.url",
"nw": "com.obilytics.people.account.url"
}
}
}
]
}](https://image.slidesharecdn.com/presentationobi4wangraphs-180115152021/85/Use-case-processing-multiple-graphs-18-320.jpg)



















![[Apache Kafka® Meetup by Confluent] Graph-based stream processing](https://cdn.slidesharecdn.com/ss_thumbnails/apachekafkameetupbyconfluentgraph-basedstreamprocessing-220406005250-thumbnail.jpg?width=640&height=640&fit=bounds)






![[263] s2graph large-scale-graph-database-with-hbase-2](https://cdn.slidesharecdn.com/ss_thumbnails/236s2graph-large-scale-graph-database-with-hbase-2-150915055019-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









