Download to read offline



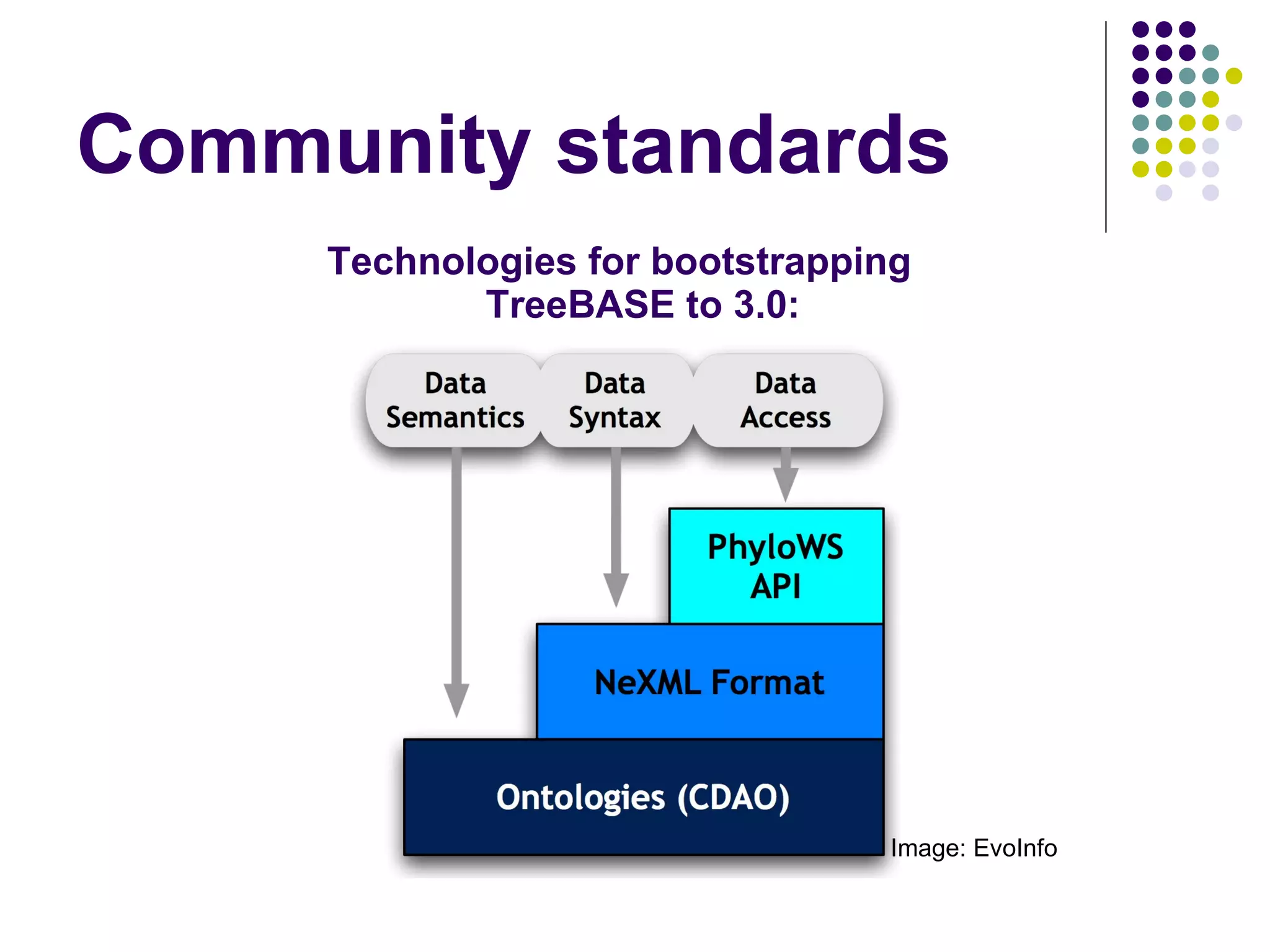







The document discusses plans to upgrade TreeBASE, a phylogenetic data resource, to version 3.0 to make it interoperable, flexible, and community-driven. Some key points are: 1) TreeBASE 3.0 will use a triples-based approach to describe data without constraints of a relational schema. 2) Technologies like PhyloWS and NeXML will provide programmatic access and allow data to be serialized in various formats. 3) Semantic annotations and links to external ontologies through CDAO will add well-defined semantics to phylogenetic objects and concepts.

















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



