Download to read offline

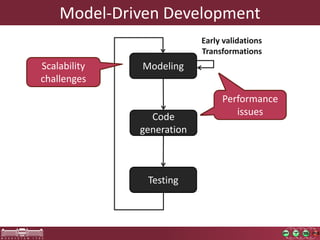




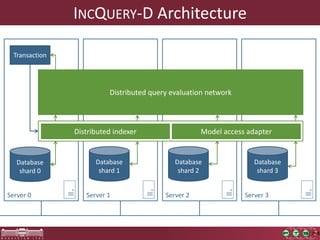
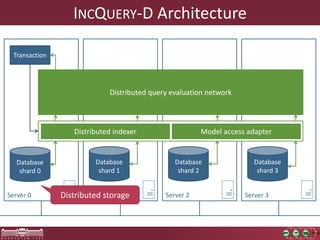
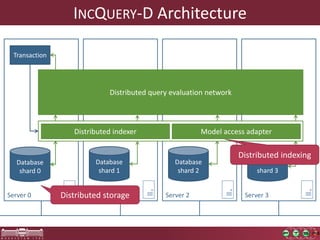
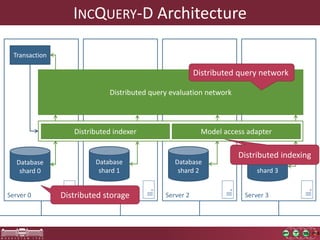
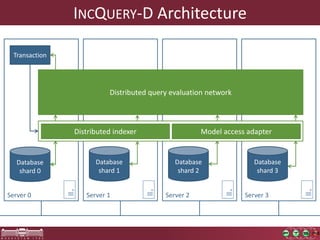
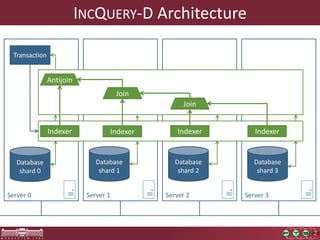
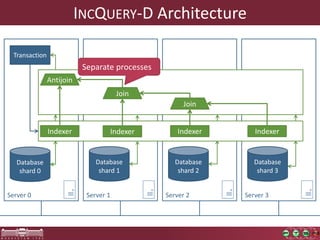
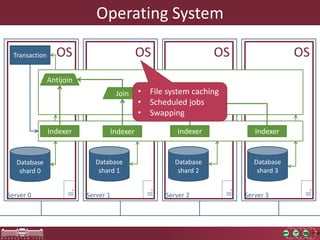
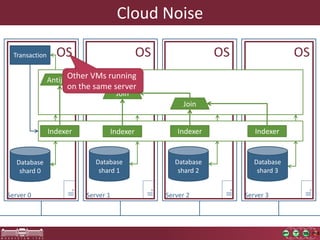
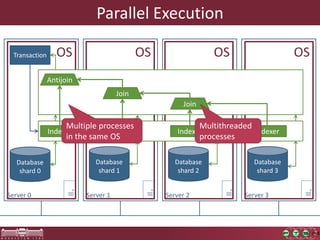

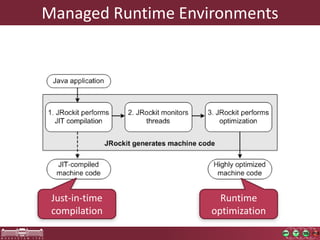
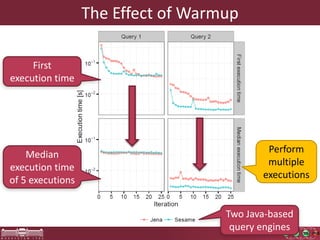



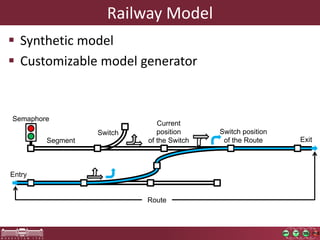

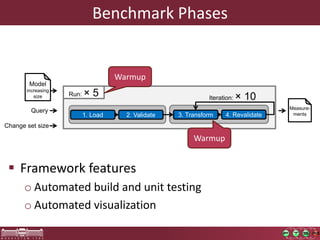
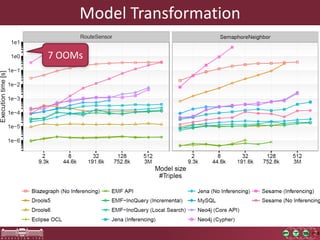



This document discusses the need for macrobenchmarks to evaluate the performance and scalability of large model querying systems. It presents the Train Benchmark, which measures the performance of validation queries on randomly generated railway network models of increasing sizes. The benchmark includes loading models, running validation queries to detect errors, transforming models by injecting faults, and revalidating. It aims to provide a realistic and scalable way to assess model querying tools for domains like software engineering, where models can contain billions of elements.


























































