Download as PDF, PPTX


![10.3 Defining parameterless methods
As a next step, we’ll add methods to Element that reveal its width and height, as shown in Listing 10.2.
abstract class Element:
def contents: Vector[String]
def height: Int = contents.length
def width: Int = if height == 0 then 0 else contents(0).length
Listing 10.2 · Defining parameterless methods width and height.
The height method returns the number of lines in contents.
The width method returns the length of the first line, or if there are no lines in the element, returns zero. (This means you cannot
define an element with a height of zero and a non-zero width.)
Note that none of Element’s three methods has a parameter list, not even an empty one.
For example, instead of:
def width(): Int
the method is defined without parentheses:
def width: Int
Such parameterless methods are quite common in Scala.
By contrast, methods defined with empty parentheses, such as ‘def height(): Int’, are called empty-paren methods.
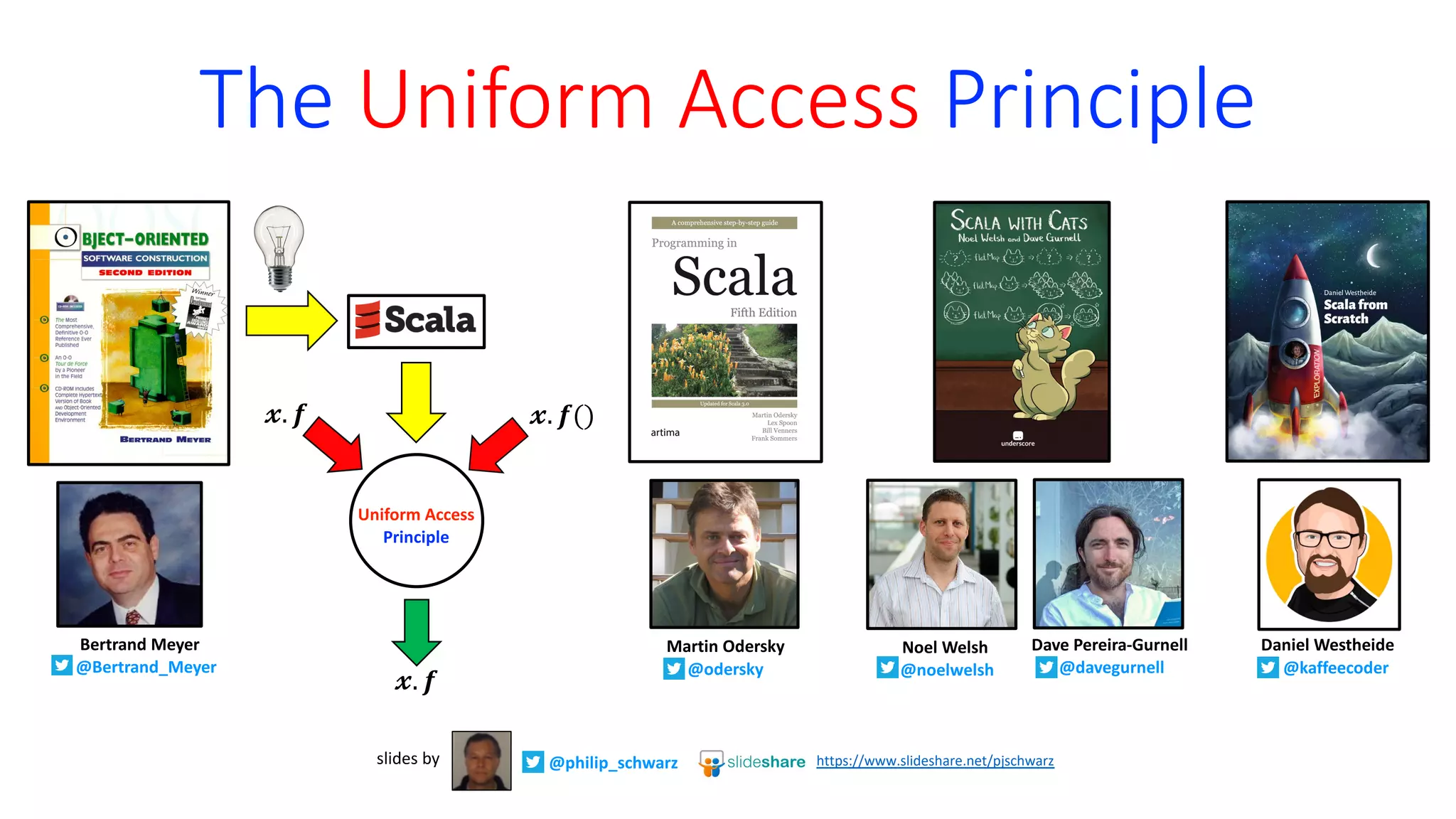
Martin Odersky
@odersky](https://image.slidesharecdn.com/the-uniform-access-principle-220417064157/75/The-Uniform-Access-Principle-6-2048.jpg)
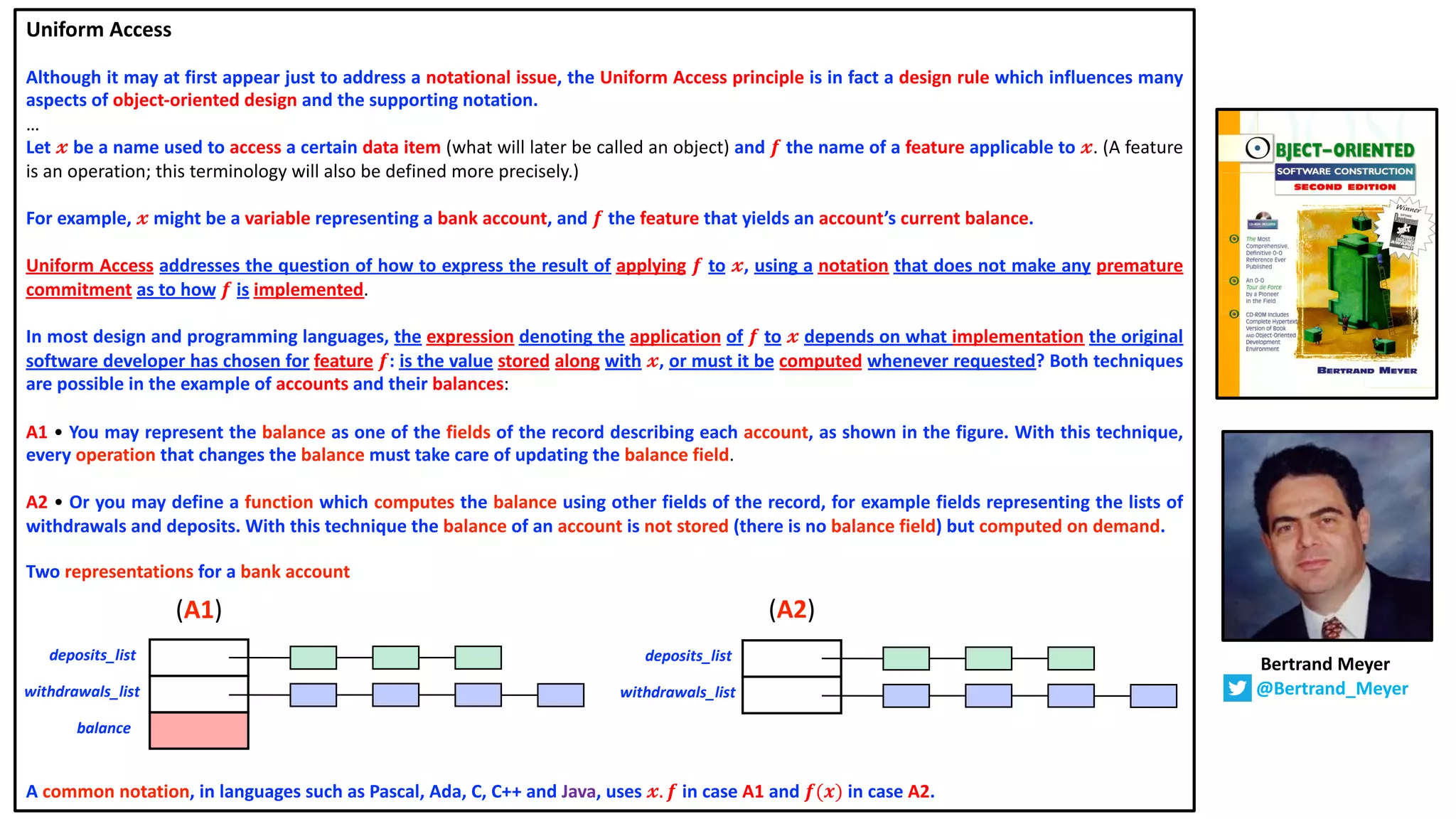
![The recommended convention is to use a parameterless method whenever there are no parameters and the method accesses
state only by reading fields of the containing object (in particular, it does not change mutable state).
This convention supports the uniform access principle,1 which says that client code should not be affected by a decision to
implement an attribute as a field or method.
For instance, we could implement width and height as fields, instead of methods, simply by changing the def in each definition
to a val:
abstract class Element:
def contents: Vector[String]
val height: Int = contents.length
val width: Int = if height == 0 then 0 else contents(0).length
The two pairs of definitions are completely equivalent from a client’s point of view.
The only difference is that field accesses might be slightly faster than method invocations because the field values are pre-
computed when the class is initialized, instead of being computed on each method call.
On the other hand, the fields require extra memory space in each Element object.
So it depends on the usage profile of a class whether an attribute is better represented as a field or method, and that usage
profile might change over time.
The point is that clients of the Element class should not be affected when its internal implementation changes.
In particular, a client of class Element should not need to be rewritten if a field of that class gets changed into an access
function, so long as the access function is pure (i.e., it does not have any side effects and does not depend on mutable state).
1 Meyer, Object-Oriented Software Construction [Mey00]
Bill Venners
@bvenners](https://image.slidesharecdn.com/the-uniform-access-principle-220417064157/75/The-Uniform-Access-Principle-7-2048.jpg)





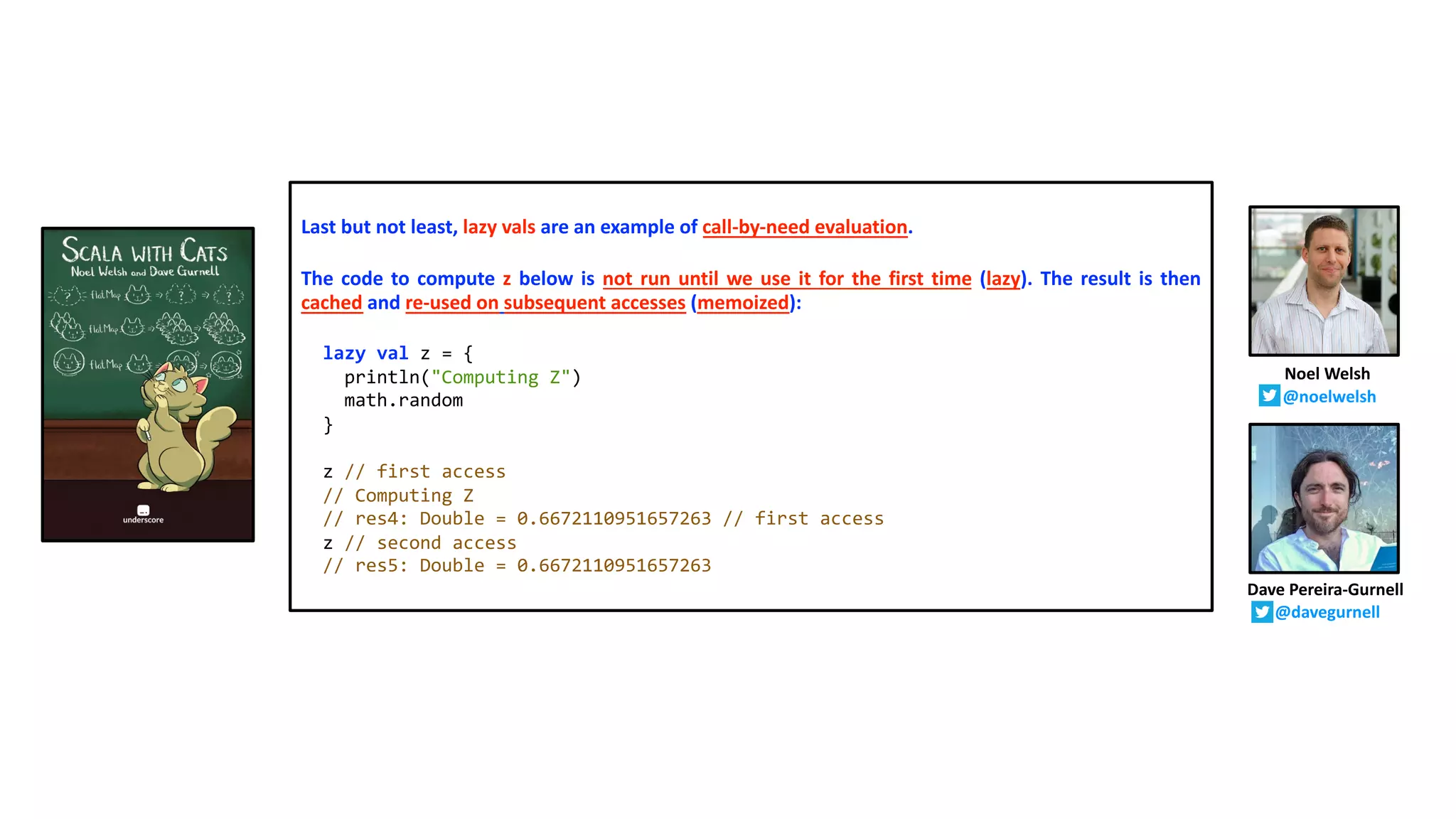

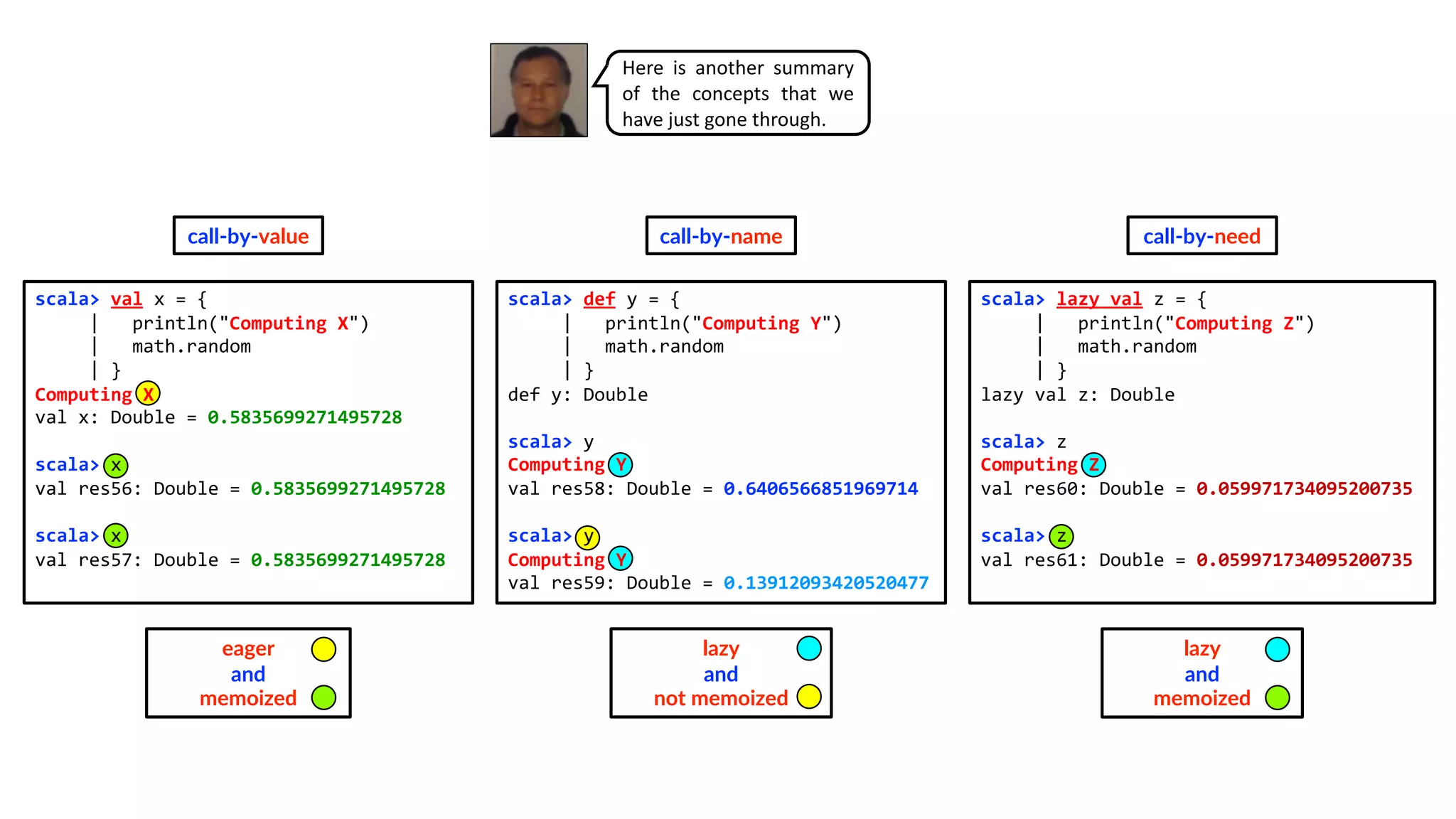



![Uniform access principle revisited
In Section 3.1, you learned about the uniform access principle.
Methods and values share the same namespace, so it doesn’t make a difference for a user of a class whether a field of that class
is defined as a value or as a parameterless method.
Now that you have learned about lazy values, you should be aware that it also doesn’t matter whether a field is a strict value or a
lazy value — the uniform access principle means that all three cases are the same from a consumer’s point of view.
Going back to our boardgame sbt project from Chapter 3, you may choose to override the toString method not as a regular,
strict val, but as a lazy val, like this:
class Position(val x: Int, val y: Int) {
// rest of the class body omitted
override lazy val toString: String =
"%s [x: %d, y: %d]".format(super.toString, x, y)
}
This can make sense if the computation of the String is quite expensive, and it’s unclear whether anyone will never call toString
on instances of the respective class.
The same is true for any other fields in classes you define: You can be flexible about whether to use a val, lazy val, or a def. Which
of the three makes most sense depends a lot on your specific use case.
The other side of the coin is that, just as with by-name parameters, when looking at some code accessing a field, there is no way
of knowing the evaluation strategy for that field without navigating to the source code in which the field is defined.
Daniel Westheide
@kaffeecoder](https://image.slidesharecdn.com/the-uniform-access-principle-220417064157/75/The-Uniform-Access-Principle-20-2048.jpg)
![class Position(val x: Int, val y: Int) {
// rest of the class body omitted
override def toString: String =
"%s (x: %d, y: %d)".format(super.toString, x, y)
}
class Position(val x: Int, val y: Int) {
// rest of the class body omitted
override val toString: String =
"%s (x: %d, y: %d)".format(super.toString, x, y)
}
class Position(val x: Int, val y: Int) {
// rest of the class body omitted
override lazy val toString: String =
"%s [x: %d, y: %d]".format(super.toString, x, y)
}
Daniel Westheide
@kaffeecoder
scala> val pos = new Position(3, 2)
val pos: Position = Position@28a2283d (x: 3, y: 2)
scala> val s = pos.toString
val s: String = Position@385d7101 (x: 3, y: 2)
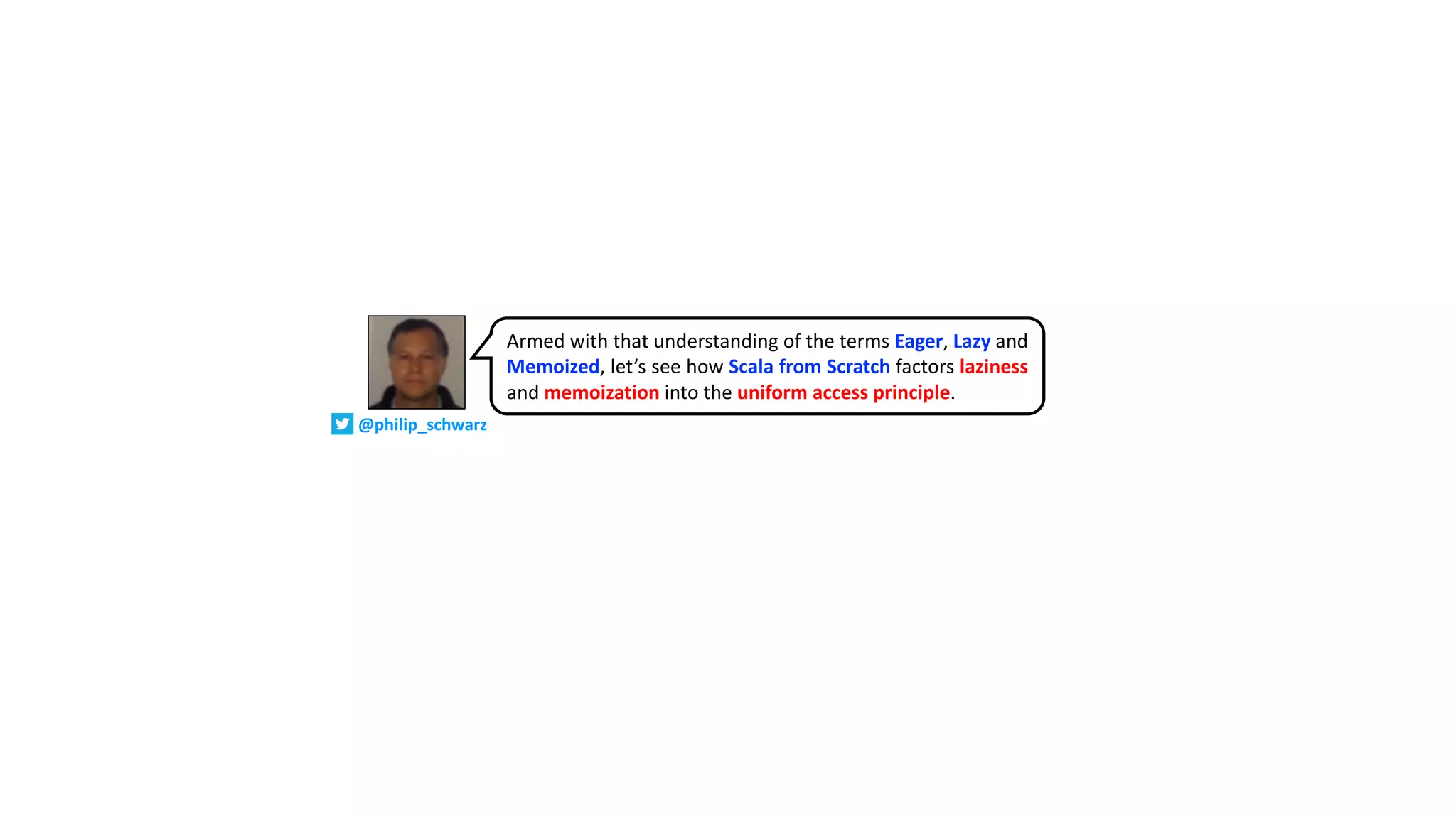
This is what we call the uniform access principle.
Parameterless methods, values and lazy values
defined in a class are accessed in a uniform way,
and you can consider all of them to be fields, or
properties.
You can be flexible about whether to use a val, lazy
val, or a def.
Which of the three makes most sense depends a lot
on your specific use case.
parameterless
method
value
lazy
value
uniform
access
eager
and
memoized
lazy
and
not memoized
lazy
and
memoized
Here is a recap](https://image.slidesharecdn.com/the-uniform-access-principle-220417064157/75/The-Uniform-Access-Principle-21-2048.jpg)

The document discusses the Uniform Access Principle, which states that all services offered by a module should be available through a uniform notation that does not reveal whether they are implemented through storage or computation. It provides examples of how different languages do or do not follow this principle, and explains that following this principle helps avoid breaking client code when implementation details change. It also discusses how Scala supports the Uniform Access Principle for parameterless methods.





















































































