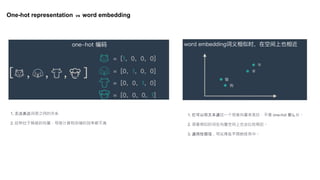
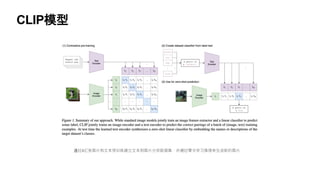
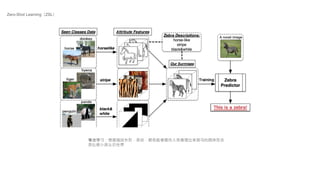
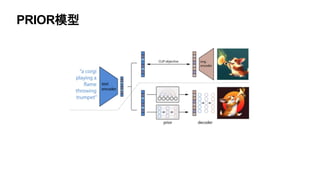
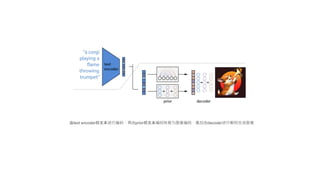
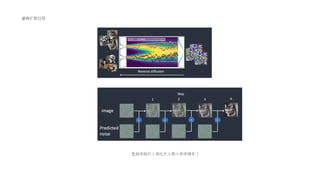
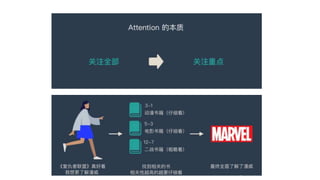
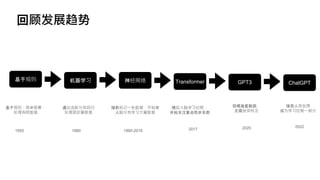
文档探讨了大语言模型的发展,特别是生成图像的技术,包括无监督学习和注意力机制的应用。详细讨论了文本编码与图像编码的转换过程,并比较了不同的学习模型。最后回顾了从基于规则的系统到神经网络和Transformer架构的发展趋势。