Download to read offline



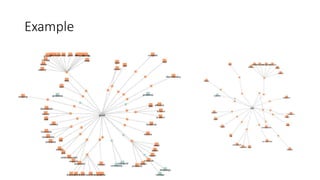
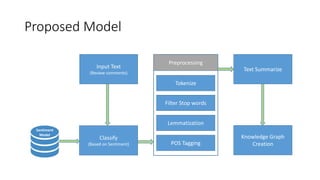

The document proposes a model to summarize text, extract important keywords, and create a knowledge graph from large amounts of text such as customer reviews. The goal is to analyze the text to determine both positive and negative sentiments about a product based on what customers say. The proposed model would preprocess the input text through steps like tokenization, stopword filtering, lemmatization and part-of-speech tagging. It would then summarize the text, classify the sentiment, and use the information to build a knowledge graph.















































