Tabla de resultados de la encuesta
•Download as DOCX, PDF•
0 likes•57 views
resultados de la encuesta realizada a los ciudadanos
Report
Share
Report
Share

Recommended
Tabla de resultados de la encuesta (2)
resultados de una encuesta realizada a estudiantes y padres sonbre el ambiente
Tabla de resultados de la encuesta periodistas 11-6 (1)
Tabla de resultados de la encuesta periodistas 11-6 (1)
Recommended
Tabla de resultados de la encuesta (2)
resultados de una encuesta realizada a estudiantes y padres sonbre el ambiente
Tabla de resultados de la encuesta periodistas 11-6 (1)
Tabla de resultados de la encuesta periodistas 11-6 (1)
Tabla de resultados de la encuesta
Tabla de resultados de la encuesta realizada a los grados 11, sobre el medio ambiente
Graficos mas analisis correcciom
analisis de la encuenta realizada a estudiantes y adultos sobre la contaminacion ambiental en cali
Tecnologia, empresas de aseo
proyecto cts para cociencizar a las personas de dar un buen manejo a las basuras
Diagrama de pareto en excel.
diagrama de pareto, que es? como se hace? para que sirve? ejemplo de problema de pareto
Desarrollo de estadística tecnología
trabajo escrito de los diferentes tipos de estadisticas que existen, con la distribucion de frecuencias, y sus distintos tipos
哪里卖(usq毕业证书)南昆士兰大学毕业证研究生文凭证书托福证书原版一模一样
原版定制【Q微信:741003700】《(usq毕业证书)南昆士兰大学毕业证研究生文凭证书》【Q微信:741003700】成绩单 、雅思、外壳、留信学历认证永久存档查询,采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【Q微信741003700】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信741003700】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
More Related Content
What's hot
Tabla de resultados de la encuesta
Tabla de resultados de la encuesta realizada a los grados 11, sobre el medio ambiente
What's hot (11)
More from Alexandrarodas4
Graficos mas analisis correcciom
analisis de la encuenta realizada a estudiantes y adultos sobre la contaminacion ambiental en cali
Tecnologia, empresas de aseo
proyecto cts para cociencizar a las personas de dar un buen manejo a las basuras
Diagrama de pareto en excel.
diagrama de pareto, que es? como se hace? para que sirve? ejemplo de problema de pareto
Desarrollo de estadística tecnología
trabajo escrito de los diferentes tipos de estadisticas que existen, con la distribucion de frecuencias, y sus distintos tipos
More from Alexandrarodas4 (9)
Recently uploaded
哪里卖(usq毕业证书)南昆士兰大学毕业证研究生文凭证书托福证书原版一模一样
原版定制【Q微信:741003700】《(usq毕业证书)南昆士兰大学毕业证研究生文凭证书》【Q微信:741003700】成绩单 、雅思、外壳、留信学历认证永久存档查询,采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【Q微信741003700】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信741003700】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
一比一原版(爱大毕业证书)爱丁堡大学毕业证如何办理
毕业原版【微信:41543339】【(爱大毕业证书)爱丁堡大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
Learn SQL from basic queries to Advance queries
Dive into the world of data analysis with our comprehensive guide on mastering SQL! This presentation offers a practical approach to learning SQL, focusing on real-world applications and hands-on practice. Whether you're a beginner or looking to sharpen your skills, this guide provides the tools you need to extract, analyze, and interpret data effectively.
Key Highlights:
Foundations of SQL: Understand the basics of SQL, including data retrieval, filtering, and aggregation.
Advanced Queries: Learn to craft complex queries to uncover deep insights from your data.
Data Trends and Patterns: Discover how to identify and interpret trends and patterns in your datasets.
Practical Examples: Follow step-by-step examples to apply SQL techniques in real-world scenarios.
Actionable Insights: Gain the skills to derive actionable insights that drive informed decision-making.
Join us on this journey to enhance your data analysis capabilities and unlock the full potential of SQL. Perfect for data enthusiasts, analysts, and anyone eager to harness the power of data!
#DataAnalysis #SQL #LearningSQL #DataInsights #DataScience #Analytics
Enhanced Enterprise Intelligence with your personal AI Data Copilot.pdf
Recently we have observed the rise of open-source Large Language Models (LLMs) that are community-driven or developed by the AI market leaders, such as Meta (Llama3), Databricks (DBRX) and Snowflake (Arctic). On the other hand, there is a growth in interest in specialized, carefully fine-tuned yet relatively small models that can efficiently assist programmers in day-to-day tasks. Finally, Retrieval-Augmented Generation (RAG) architectures have gained a lot of traction as the preferred approach for LLMs context and prompt augmentation for building conversational SQL data copilots, code copilots and chatbots.
In this presentation, we will show how we built upon these three concepts a robust Data Copilot that can help to democratize access to company data assets and boost performance of everyone working with data platforms.
Why do we need yet another (open-source ) Copilot?
How can we build one?
Architecture and evaluation
Ch03-Managing the Object-Oriented Information Systems Project a.pdf
Object oriented system analysis and design
一比一原版(UIUC毕业证)伊利诺伊大学|厄巴纳-香槟分校毕业证如何办理
UIUC毕业证offer【微信95270640】☀《伊利诺伊大学|厄巴纳-香槟分校毕业证购买》GoogleQ微信95270640《UIUC毕业证模板办理》加拿大文凭、本科、硕士、研究生学历都可以做,二、业务范围:
★、全套服务:毕业证、成绩单、化学专业毕业证书伪造《伊利诺伊大学|厄巴纳-香槟分校大学毕业证》Q微信95270640《UIUC学位证书购买》
(诚招代理)办理国外高校毕业证成绩单文凭学位证,真实使馆公证(留学回国人员证明)真实留信网认证国外学历学位认证雅思代考国外学校代申请名校保录开请假条改GPA改成绩ID卡
1.高仿业务:【本科硕士】毕业证,成绩单(GPA修改),学历认证(教育部认证),大学Offer,,ID,留信认证,使馆认证,雅思,语言证书等高仿类证书;
2.认证服务: 学历认证(教育部认证),大使馆认证(回国人员证明),留信认证(可查有编号证书),大学保录取,雅思保分成绩单。
3.技术服务:钢印水印烫金激光防伪凹凸版设计印刷激凸温感光标底纹镭射速度快。
办理伊利诺伊大学|厄巴纳-香槟分校伊利诺伊大学|厄巴纳-香槟分校毕业证offer流程:
1客户提供办理信息:姓名生日专业学位毕业时间等(如信息不确定可以咨询顾问:我们有专业老师帮你查询);
2开始安排制作毕业证成绩单电子图;
3毕业证成绩单电子版做好以后发送给您确认;
4毕业证成绩单电子版您确认信息无误之后安排制作成品;
5成品做好拍照或者视频给您确认;
6快递给客户(国内顺丰国外DHLUPS等快读邮寄)
-办理真实使馆公证(即留学回国人员证明)
-办理各国各大学文凭(世界名校一对一专业服务,可全程监控跟踪进度)
-全套服务:毕业证成绩单真实使馆公证真实教育部认证。让您回国发展信心十足!
(详情请加一下 文凭顾问+微信:95270640)欢迎咨询!的鬼地方父亲的家在高楼最底屋最下面很矮很黑是很不显眼的地下室父亲的家安在别人脚底下须绕过高楼旁边的垃圾堆下八个台阶才到父亲的家很狭小除了一张单人床和一张小方桌几乎没有多余的空间山娃一下子就联想起学校的男小便处山娃很想笑却怎么也笑不出来山娃很迷惑父亲的家除了一扇小铁门连窗户也没有墓穴一般阴森森有些骇人父亲的城也便成了山娃的城父亲的家也便成了山娃的家父亲让山娃呆在屋里做作业看电视最多只能在门口透透气间
The affect of service quality and online reviews on customer loyalty in the E...
Journal of Management and Creative Business.published book./
一比一原版(Dalhousie毕业证书)达尔豪斯大学毕业证如何办理
原版定制【微信:41543339】【(Dalhousie毕业证书)达尔豪斯大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
Adjusting primitives for graph : SHORT REPORT / NOTES
Graph algorithms, like PageRank Compressed Sparse Row (CSR) is an adjacency-list based graph representation that is
Multiply with different modes (map)
1. Performance of sequential execution based vs OpenMP based vector multiply.
2. Comparing various launch configs for CUDA based vector multiply.
Sum with different storage types (reduce)
1. Performance of vector element sum using float vs bfloat16 as the storage type.
Sum with different modes (reduce)
1. Performance of sequential execution based vs OpenMP based vector element sum.
2. Performance of memcpy vs in-place based CUDA based vector element sum.
3. Comparing various launch configs for CUDA based vector element sum (memcpy).
4. Comparing various launch configs for CUDA based vector element sum (in-place).
Sum with in-place strategies of CUDA mode (reduce)
1. Comparing various launch configs for CUDA based vector element sum (in-place).
原版制作(swinburne毕业证书)斯威本科技大学毕业证毕业完成信一模一样
学校原件一模一样【微信:741003700 】《(swinburne毕业证书)斯威本科技大学毕业证》【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
Algorithmic optimizations for Dynamic Levelwise PageRank (from STICD) : SHORT...
Techniques to optimize the pagerank algorithm usually fall in two categories. One is to try reducing the work per iteration, and the other is to try reducing the number of iterations. These goals are often at odds with one another. Skipping computation on vertices which have already converged has the potential to save iteration time. Skipping in-identical vertices, with the same in-links, helps reduce duplicate computations and thus could help reduce iteration time. Road networks often have chains which can be short-circuited before pagerank computation to improve performance. Final ranks of chain nodes can be easily calculated. This could reduce both the iteration time, and the number of iterations. If a graph has no dangling nodes, pagerank of each strongly connected component can be computed in topological order. This could help reduce the iteration time, no. of iterations, and also enable multi-iteration concurrency in pagerank computation. The combination of all of the above methods is the STICD algorithm. [sticd] For dynamic graphs, unchanged components whose ranks are unaffected can be skipped altogether.
原版制作(Deakin毕业证书)迪肯大学毕业证学位证一模一样
学校原件一模一样【微信:741003700 】《(Deakin毕业证书)迪肯大学毕业证学位证》【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
一比一原版(UofS毕业证书)萨省大学毕业证如何办理
原版定制【微信:41543339】【(UofS毕业证书)萨省大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
The Building Blocks of QuestDB, a Time Series Database
Talk Delivered at Valencia Codes Meetup 2024-06.
Traditionally, databases have treated timestamps just as another data type. However, when performing real-time analytics, timestamps should be first class citizens and we need rich time semantics to get the most out of our data. We also need to deal with ever growing datasets while keeping performant, which is as fun as it sounds.
It is no wonder time-series databases are now more popular than ever before. Join me in this session to learn about the internal architecture and building blocks of QuestDB, an open source time-series database designed for speed. We will also review a history of some of the changes we have gone over the past two years to deal with late and unordered data, non-blocking writes, read-replicas, or faster batch ingestion.
做(mqu毕业证书)麦考瑞大学毕业证硕士文凭证书学费发票原版一模一样
原版定制【Q微信:741003700】《(mqu毕业证书)麦考瑞大学毕业证硕士文凭证书》【Q微信:741003700】成绩单 、雅思、外壳、留信学历认证永久存档查询,采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【Q微信741003700】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信741003700】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
一比一原版(Adelaide毕业证书)阿德莱德大学毕业证如何办理
原版定制【微信:41543339】【(Adelaide毕业证书)阿德莱德大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
Recently uploaded (20)
Data_and_Analytics_Essentials_Architect_an_Analytics_Platform.pptx
Data_and_Analytics_Essentials_Architect_an_Analytics_Platform.pptx
Enhanced Enterprise Intelligence with your personal AI Data Copilot.pdf
Enhanced Enterprise Intelligence with your personal AI Data Copilot.pdf
Ch03-Managing the Object-Oriented Information Systems Project a.pdf
Ch03-Managing the Object-Oriented Information Systems Project a.pdf
Influence of Marketing Strategy and Market Competition on Business Plan
Influence of Marketing Strategy and Market Competition on Business Plan
The affect of service quality and online reviews on customer loyalty in the E...
The affect of service quality and online reviews on customer loyalty in the E...
Adjusting primitives for graph : SHORT REPORT / NOTES
Adjusting primitives for graph : SHORT REPORT / NOTES
Algorithmic optimizations for Dynamic Levelwise PageRank (from STICD) : SHORT...
Algorithmic optimizations for Dynamic Levelwise PageRank (from STICD) : SHORT...
The Building Blocks of QuestDB, a Time Series Database
The Building Blocks of QuestDB, a Time Series Database
Tabla de resultados de la encuesta
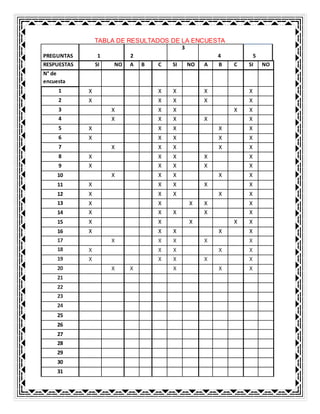
- 1. TABLA DE RESULTADOS DE LA ENCUESTA PREGUNTAS 1 2 3 4 5 RESPUESTAS SI NO A B C SI NO A B C SI NO N° de encuesta 1 X X X X X 2 X X X X X 3 X X X X X 4 X X X X X 5 X X X X X 6 X X X X X 7 X X X X X 8 X X X X X 9 X X X X X 10 X X X X X 11 X X X X X 12 X X X X X 13 X X X X X 14 X X X X X 15 X X X X X 16 X X X X X 17 X X X X X 18 X X X X X 19 X X X X X 20 X X X X X 21 22 23 24 25 26 27 28 29 30 31
- 2. 32 33 34 35 36 37 38 39 40 TOTAL 14 6 1 0 19 18 2 10 8 2 20 0