Downloaded 457 times





















































The document discusses syntax analysis and parsing. It defines a syntax analyzer as creating the syntactic structure of a source program in the form of a parse tree. A syntax analyzer, also called a parser, checks if a program satisfies the rules of a context-free grammar and produces the parse tree if it does, or error messages otherwise. It describes top-down and bottom-up parsing methods and how parsers use grammars to analyze syntax.
Introduces syntax analysis and its role in programming languages using context-free grammars.
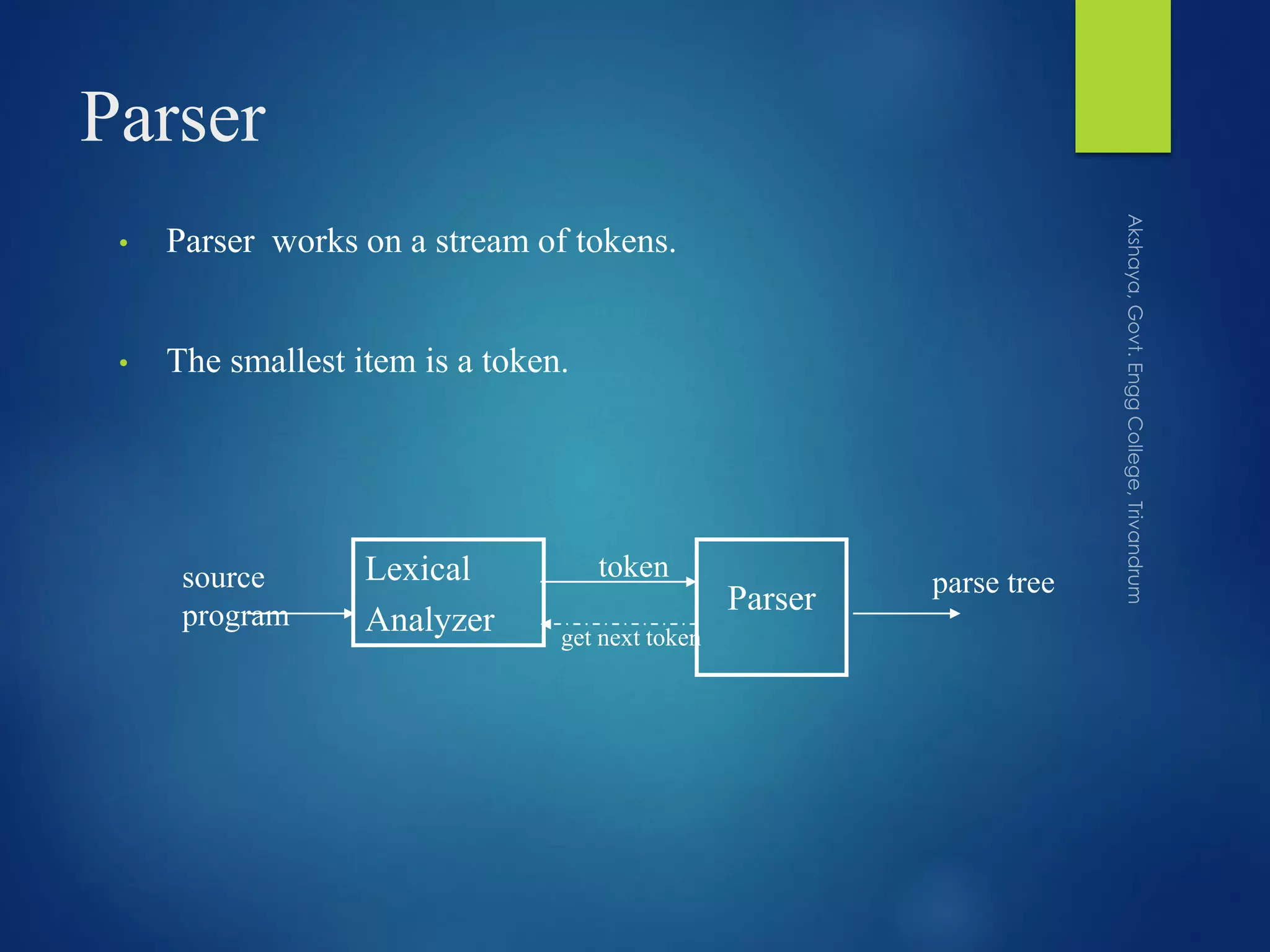
Explains the parser's function using tokens and introduces top-down and bottom-up parsing methods.
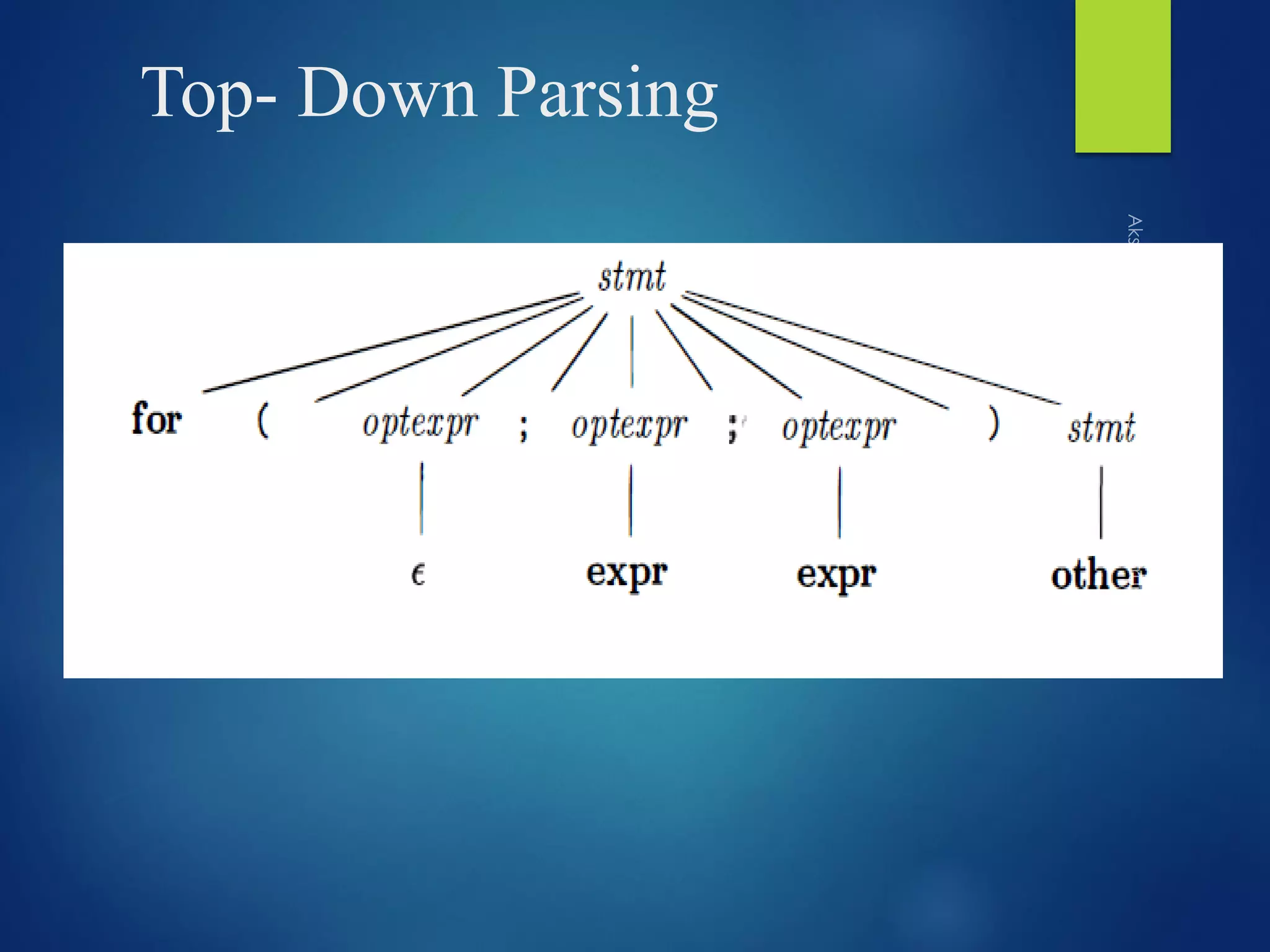
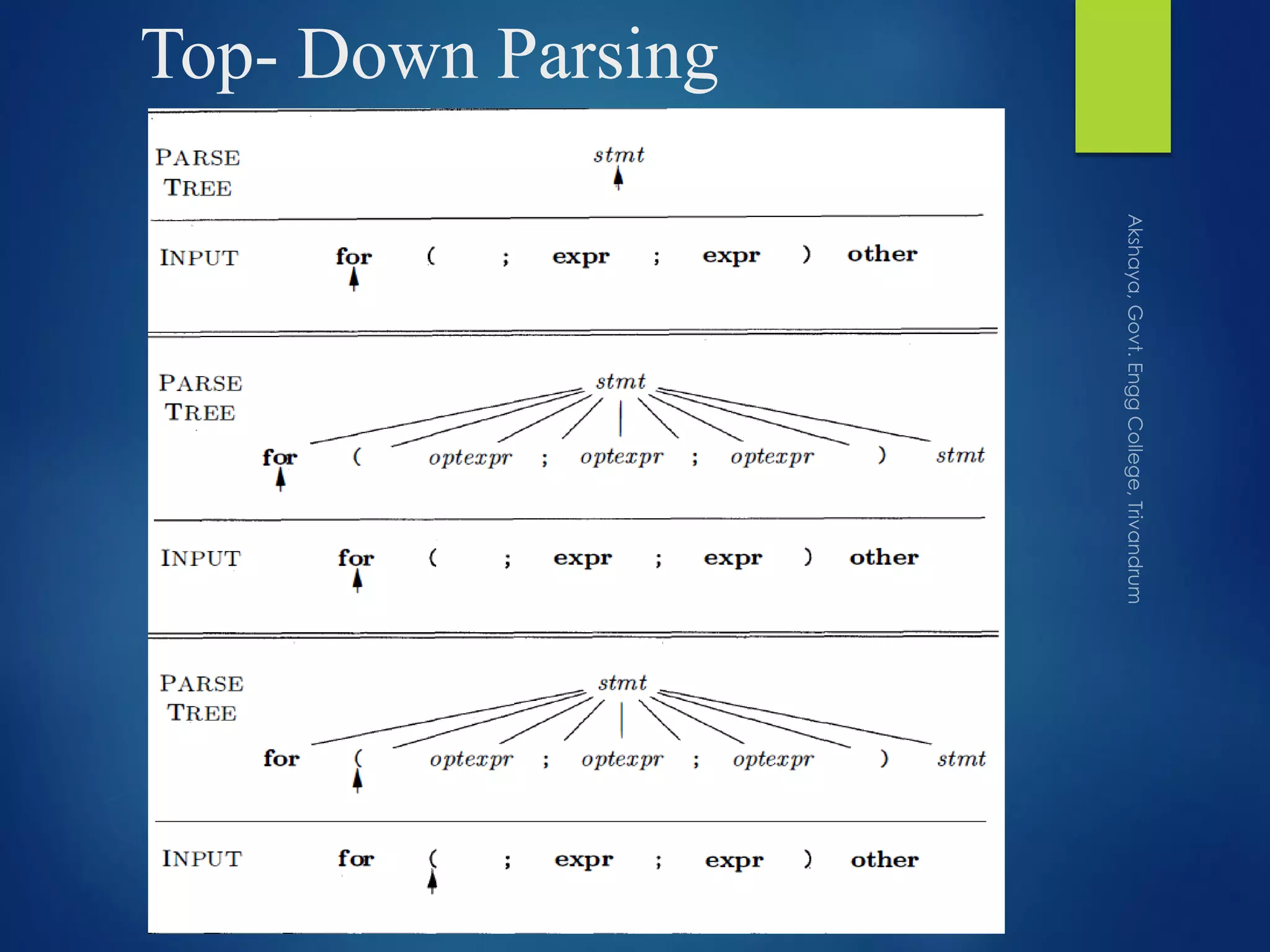
Discusses the steps and strategy behind top-down parsing, showcasing derivations and examples.
Describes recursive-descent parsing as a form of predictive parsing.
Explains goals and strategies for syntax error handling, including panic-mode and local corrections.
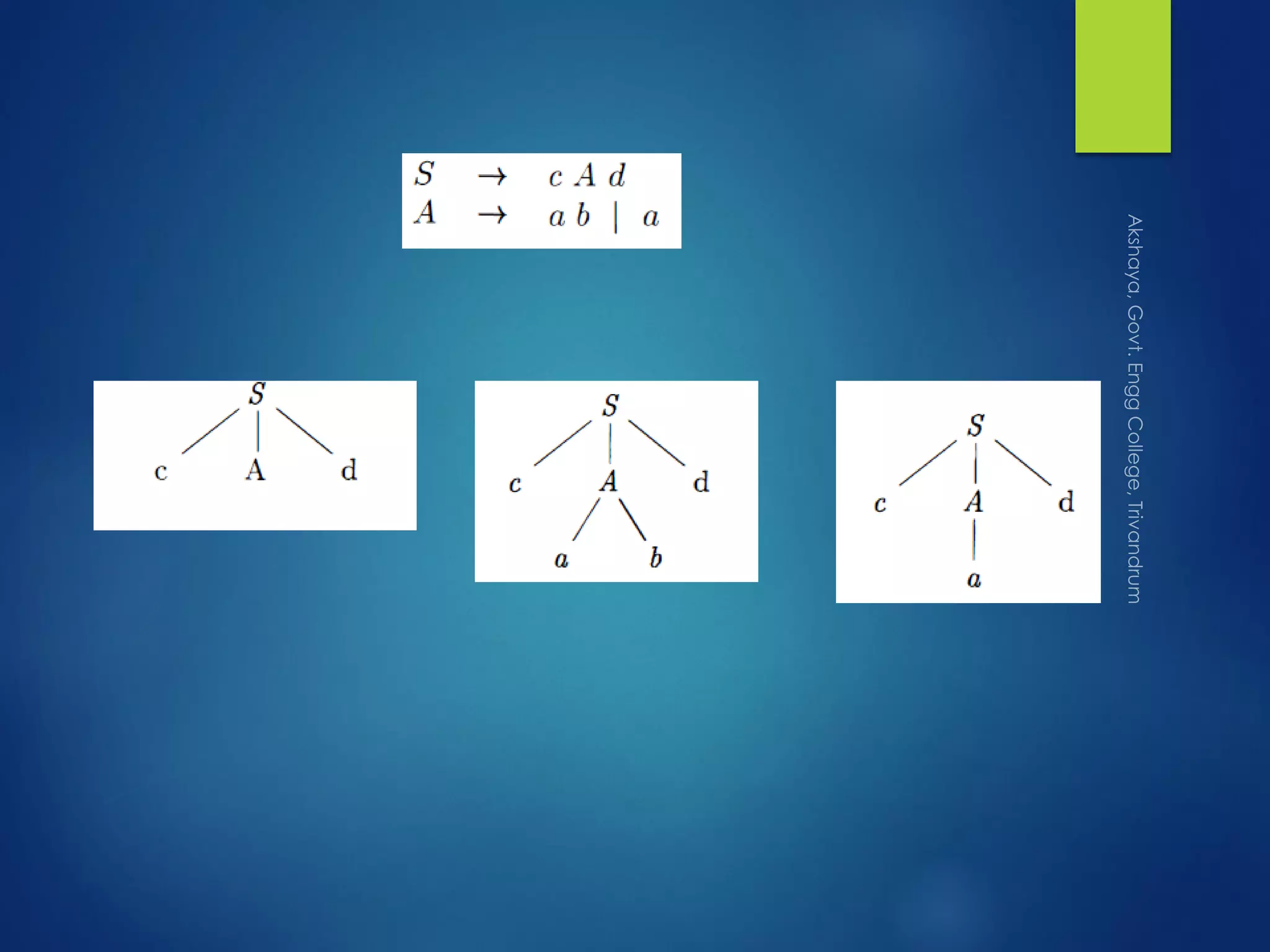
Details the structure of programming constructs and the components of a context-free grammar.
Defines terminal and nonterminal symbols and their representations within grammar.
Discusses derivations, left-most and right-most derivations, and their relations to parse trees.
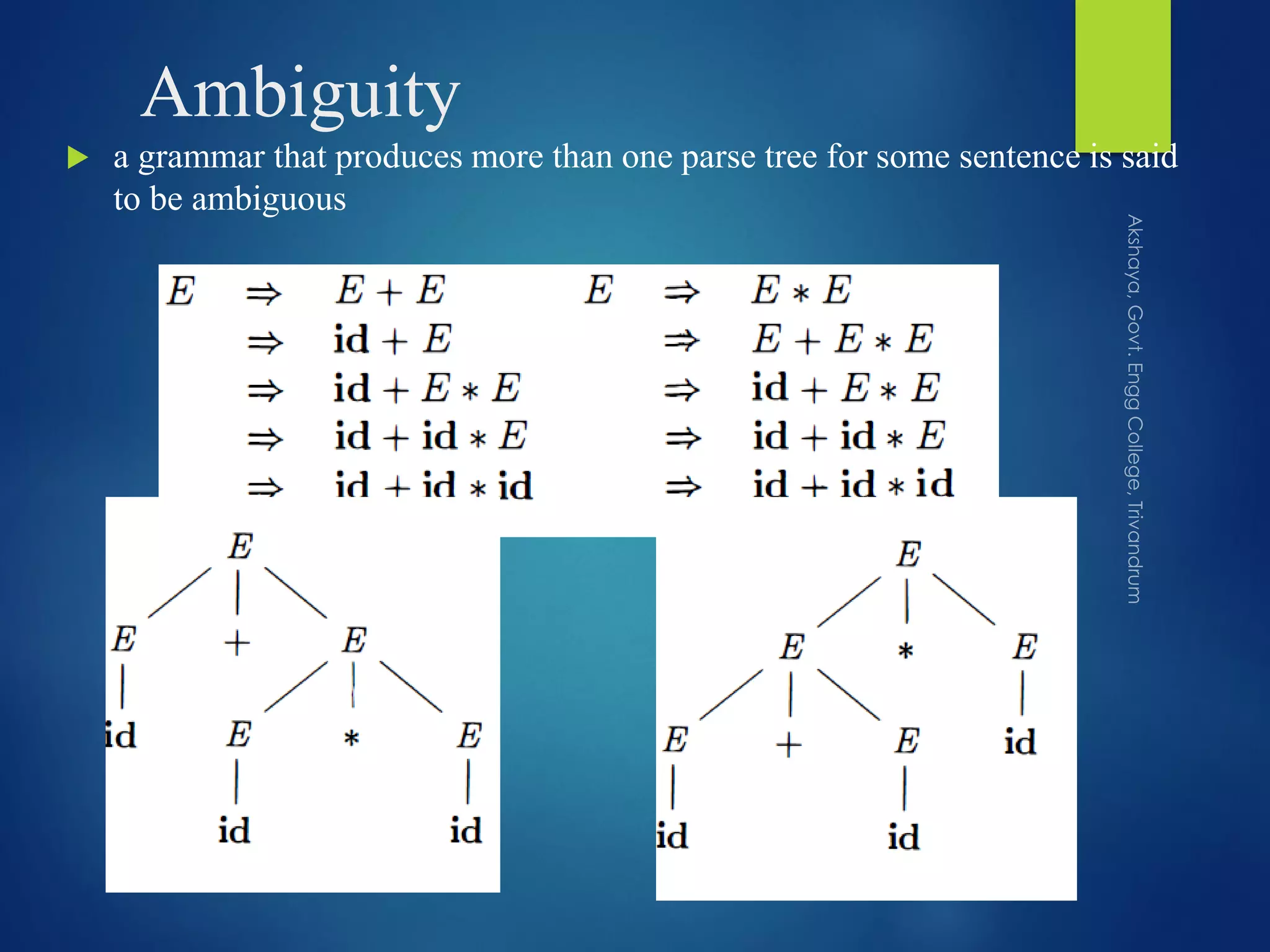
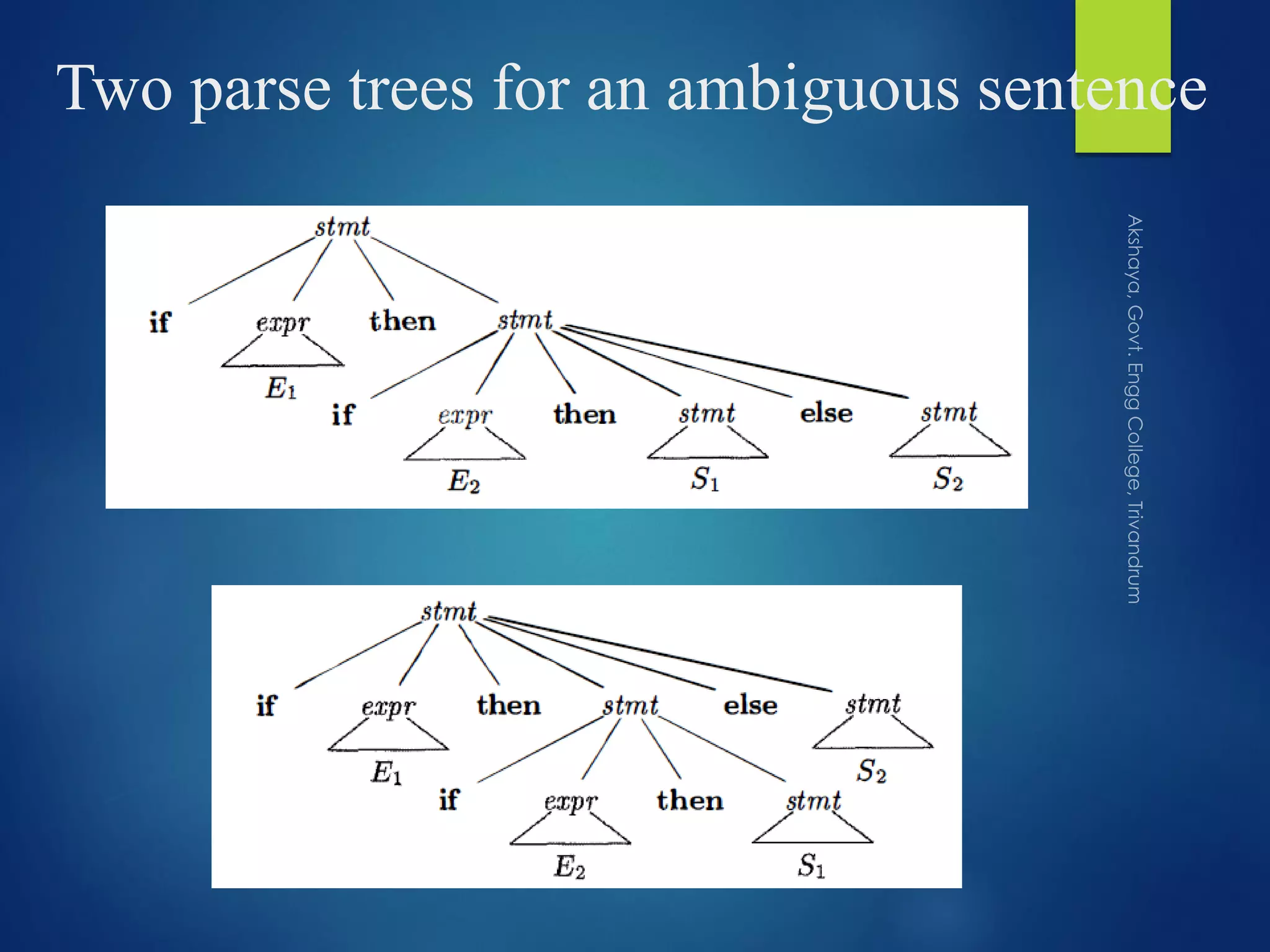
Describes parse trees as graphical representations of derivations and introduces ambiguity in grammars.
Describes constructing unambiguous grammars and the rules for eliminating ambiguity in grammar.
Defines left recursion, its implications in parsing, and methods to eliminate it from grammars.
Explains left factoring as a technique to make grammars suitable for predictive parsing.
Summarizes the characteristics of top-down parsing methods and introduces predictive parsing.
Introduces FIRST and FOLLOW sets, crucial for parsing decisions in grammar analysis.
Defines LL(1) grammars and outlines the construction process for a predictive parsing table.














































![Cd2 [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/cd2autosaved-161231072301-thumbnail.jpg?width=640&height=640&fit=bounds)






























