Download to read offline






![1
5
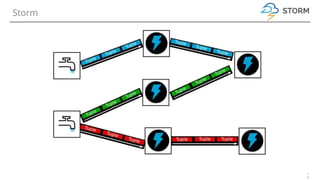
Storm/Heron
➔ Near real time processing
[micro-batching using Trident]
➔ No single point of failure
➔ At-least-once processing guarantee
[exactly-once using Trident]
➔ Windowing support [using Trident]
➔ Little community support
➔ Not tied to Hadoop](https://image.slidesharecdn.com/streamingoptionsinthewild-180729153849/85/Streaming-options-in-the-wild-15-320.jpg)


![1
9
Akka Streams
val fetchLinks: Flow[String, Link, Unit] =
Flow[String]
.via(throttle(redditAPIRate))
.mapAsyncUnordered( subreddit => RedditAPI.popularLinks(subreddit)
)](https://image.slidesharecdn.com/streamingoptionsinthewild-180729153849/85/Streaming-options-in-the-wild-19-320.jpg)

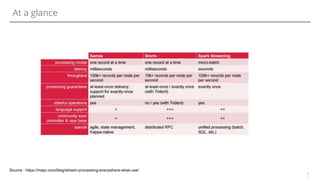
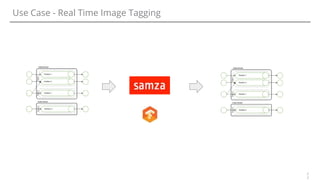




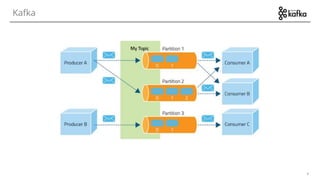
The document discusses various options for data streaming, focusing on different processing paradigms such as real-time, near real-time, and micro-batching. It compares frameworks like Kafka, Flume, Spark Streaming, Storm, and Apache Samza, highlighting their features, use cases, and community support. Key considerations for streaming include event time, state management, fault tolerance, and handling out-of-sequence events.
















![Frossie Economou & Angelo Fausti [Vera C. Rubin Observatory] | How InfluxDB H...](https://cdn.slidesharecdn.com/ss_thumbnails/veracrubininfluxdays2020-201111202349-thumbnail.jpg?width=640&height=640&fit=bounds)


















































